
0 Allgemeines
In diesem Handbuch wird beschrieben, welche Aktivitäten technischer Art erforderlich sind, um in einem RZ ein installiertes ASS zu betreiben.
Dieses Handbuch gilt für folgende Systemumgebungen:
-
IBM-Betriebssysteme MVS, OS/390, z/OS oder VSE
mit den Versionen:- IMS/DLI
- IMS/DB2
- CICS/VSAM
- CICS/DLI
- CICS/DB2
- CICS/ADABAS
-
SIEMENS-Betriebssystem BS2000
mit den Versionen:- UTM/ISAM
- Linux und Unix
- Windows
Für den einzelnen Anwender sind natürlich nur die für seine ASS-Version relevanten Ausführungen zu beachten.
1 Betrieb der Verwaltung der Parameterdatenbanken
1.1 DLI
Die Parameterdatenbanken müssen ONLINE zugreifbar sein; die Transaktion ST06 muss gestartet sein.
-
DST001
- DST011
- DST012
- DST013
- DST002
- DST021
- DST022
- DST023
- DST003
- DST031
- DST032
- DST033
- DST007
- DST071
- DST009
1.2 ADABAS
ADABAS muss aktiv sein und die erforderlichen ADABAS-Files müssen im JOB, in dem die Transaktion ST06 abläuft, zugeordnet sein, ST06 muss gestartet sein.
1.3 BS2000-ISAM
Die Transaktionen ST06 und ST31 und gegebenenfalls ST09 (vgl. Kap. 8) sind in einer UTM-Anwendung zusammengefasst, siehe daher 6.3.
2 Folgeeinspeicherung
Die Folgeeinspeicherung läuft in mehreren Schritten ab:
-
Schritt:
Verarbeiten externe Schnittstellendatei und
Erzeugen interne Schnittstellendatei,
bestehend aus den Steps
- Abziehen Arbeitsgebiet (PCL1004)
- Erzeugen interne Schnittstellendatei (PCL1001)
-
Schritt:
Abziehen alte Summendatenbank(en) auf seq. Datei
(entfällt bei Ersteinspeicherung oder falls
die interne Schnittstelle direkt eingespeichert
wird).
-
IBM DL/I
Regelfall: Alte Summendatenbank mittels HSSR oder DFSURGU0 auf seq. Datei abziehen. Existiert im betreffenden RZ HSSR bzw. DFSURGU0 nicht, so kann die alte Summendatenbank mit dem Programm PCL1024 abgezogen werden. Werden Verdichtungsstufen fortgeschrieben, die in mehreren Summendatenbanken gespeichert sind, so muss der Abzug mit dem Programm PCL1124 erzeugt werden. -
SIEMENS
ISAM
Alte Summendatenbank(en) mit PCL1024/PCL1124 abziehen. -
SAG ADABAS
Alte Summendatenbank(en) mit PCL1024/PCL1124 abziehen.
-
IBM DL/I
-
Schritt:
Verarbeiten der Internen Schnittstellendatei
mit dem Programm PCL1002:
Laden Summendatenbank(en) aus interner
Schnittstellendatei bzw. erzeugen Ladebestand (bzw.
Ladebestände) aus interner Schnittstellendatei
für PCL1013 (siehe PCL1002).
HINWEIS:
PCL1002 führt einen UPDATE auf die Steuerungs-DB durch. Beim Laden von großen Summendatenbanken entsteht daher viel Loginformation. In diesem Fall führt man das Laden besser mit Schritt 5 durch.
-
Schritt:
Einspeicherung in die Summendatenbank(en)
(entfällt, falls Einspeicherung bereits von PCL1002
durchgeführt wurde).
-
IBM
Ladebestand (bzw. Ladebestände) in Summendatenbank(en) speichern (PCL1013) -
SIEMENS
Ladebestand (bzw. Ladebestände) in Summendatenbank(en) speichern (PCL1013) -
SAG ADABAS
Summendatenbank(en) mit ADABAS-Utilities laden unter Verwendung von MST0100 im User-Exit 6.
-
IBM
- Schritt: Update auf die Steuerungs-DB (PCL1032) Normalerweise führt PCL1002 einen UPDATE auf die Steuerungs-DB durch. Falls Parallelläufe von PCL1002 erforderlich sein sollten, kann man diesen UPDATE verzögern und später vom Programm PCL1032 durchführen lassen. Einzelheiten s.u..
HINWEIS:
Im Programm PCL1002 existiert auch die Möglichkeit, Änderungen direkt auf die Summendatenbank zu spielen. Dies ist jedoch nur möglich, wenn die externe Schnittstelle ausschließlich Bewegungswerte enthält und keine aktiven Verdichtungsstufen auf sequentiellem Datenträger vorliegen. Beim Fortschreiben von Änderungen auf die Summendatenbanken verlängern sich die Sätze. Dies führt z.B. in einer DLI-Umgebung zu Segmentsplits. Ein direktes Fortschreiben ist also nur bei kleinem Änderungsumfang empfehlenswert. Führt man eine Folgeeinspeicherung in der oben beschriebenen Form (sechs Steps) durch, so wird die betreffende Summendatenbank reorganisiert.
Hinweis für DLI:Es versteht sich, dass beim direkten Einspeichern von Änderungen mittels PCL1002 nicht mehr mit einem LADE-PCB gearbeitet werden kann, PROCOPT=A ist dann für die betreffenden Summendatenbanken erforderlich.
Achtung: Die Schritte 3 und 4 dürfen nicht vertauscht werden.
2.1 Verarbeiten der externen Schnittstelle PCL1001
ASS ist ein in sich abgeschlossenes System. Es übernimmt Daten aus anderen Systemen nur über die externe Schnittstellendatei. Die externe Schnittstelle ist also die zentrale Schnittstelle von ASS zu ASS-fremden Datenbeständen. Alle Statistikdaten, die in ASS-Summendatenbanken gespeichert und maschinell zur Verfügung gestellt werden können, müssen in externen Schnittstellendateien bereitgestellt werden, von wo aus sie ihm Rahmen der Folgeeinspeicherung in ASS-Summendatenbanken übernommen werden. Der physikalische Aufbau der externen Schnittstelle ist in dem Handbuch SYSTEMDOKUMENTATION beschrieben.
Externe Schnittstellen, die von Schnittstellenprogrammen erstellt wurden, werden zunächst vom Programm PCL1001 verarbeitet und dabei in eine sogenannte interne Schnittstelle umgeformt. Bei der Verarbeitung von externen Schnittstellendateien werden eine Reihe von Prüfungen durchgeführt, um Fehler in der externen Schnittstelle oder Fehler im Handling der Folgeeinspeicherung erkennen zu können.
Eingaben:
- Die externe Schnittstellendatei (ASSIN01).
- Abzug des Arbeitsgebiets, für das eine interne Schnittstellendatei erzeugt werden soll. Dieser Abzug wird mit dem Programm PCL1004 erzeugt. Einzelheiten zu diesen Programmen sind dem Handbuch für die Dienstprogramme zu entnehmen.
Ausgaben:
Der OUTPUT von PCL1001 besteht aus drei Komponenten:- Eine interne Schnittstellendatei.
-
Fortschreiben von Kontrollinformationen in Werte- und
Schlüssel- und Steuerungsdatenbank, u.a.:
- Änderungssperre bei Schlüsseln setzen
- Änderungssperre bei Werten setzen
- Zeiträume bei verwendeten Werten setzen
- Eingespeicherte Zeiten im Arbeitsgebiet setzen
- Evtl. Ergänzung von Schlüsselausprägungen in der Schlüsseldatenbank.
Betriebsmittel:
Da externe Schnittstellen unter Umständen einen sehr großen Umfang annehmen können, braucht PCL1001 für die Verarbeitung auch eine gewisse Menge an Betriebsmitteln:- temporäre Workdatei ASSWONN
- zwei Arbeitsdateien ASSWK01 und ASSWK02
- Arbeitsdatei ASSWK03, falls in Vorlaufkarte ASSWK = 3 oder ASSWK = 4 angegeben
- Arbeitsdatei ASSWK04, falls in Vorlaufkarte ASSWK = 4 angegeben
Ablauf:
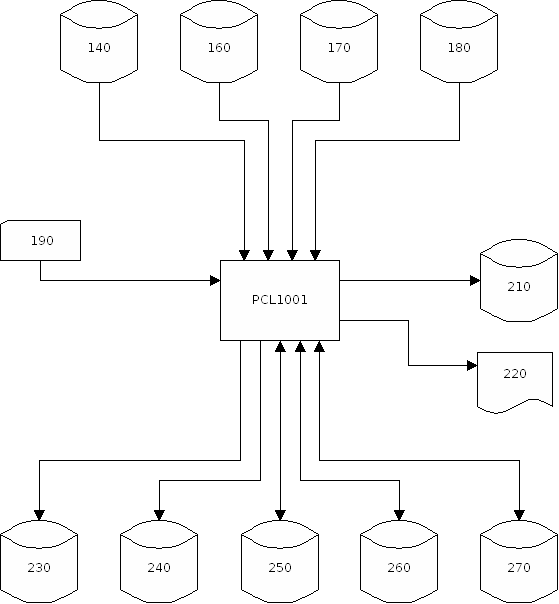
Dateibeschreibung:
| Lfd.-Nr. | DD-Name/PGM LINK-Name |
Dateiname ASS-PC | Beschreibung |
|---|---|---|---|
| 140 | //ASSDB | $ASS/AG.EBC | Abzug des Arbeitsgebiets Ausgabe von PCL1004 |
| 160 | //ASSIN01 | $ASS/ASSIN01 | Externe Schnittstelle |
| 180 | //DST001 //DST011 //DST012 //DST013 //DST002 //DST021 //DST022 //DST023 //DST003 //DST031 //DST032 //DST033 //DST006 //DST007 |
$ASSDB/DST001 - - - $ASSDB/DST002 - - - $ASSDB/DST003 - - - - §ASSDB/DST007 | Werte-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Schlüssel-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Steuerungs-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Before-Images (nur SIEMENS-ISAM / VSAM) Text-DB |
| 190 | //ASSCO | $ASSVLK/T1001.VLK | Vorlaufkarte |
| 210 | - | - | LOGDATEI (nur DLI) |
| 220 | //ASSLIST //SYSPRINT | $ASSPTK/PCL1001.PTK | Ablaufprotokoll PCL1001 |
| 230 | //ASSOUNN | $ASS/AE.DAT | Interne Schnittstelle, Eingabe für PCL1002 Satzlänge=10000 |
| 240 | //ASSFEHL | $ASS/ASSFEHL bzw. $ASS/ASSFEHLV (bei EXIT_TEXT) | Fehler- und Schwebedatei Satzlänge=10000 |
| 250 | //ASSWONN | $ASSWK/ASSWONN | Arbeitsdatei Satzlänge=20000 |
| 260 | //ASSWK01 //ASSWK02 //ASSWK03 //ASSWK04 |
$ASSWK/ASSWK01 $ASSWK/ASSWK02 $ASSWK/ASSWK03 $ASSWK/ASSWK04 |
Workdatei 01, Satzlänge=20000 Workdatei 02, Satzlänge=20000 Workdatei 03, Satzlänge=20000 Workdatei 04, Satzlänge=20000 |
| 270 | //SORTWK01 bis //SORTWKnn //SORTWK1 bis //SORTWKn |
$ASSWK/SORTNN | SORTWORK-Bereich 1 (bei IBM) bis SORTWORK-Bereich nn (bei IBM) SORTWORK-Bereich 1 (bei SIEMENS) bis SORTWORK-Bereich n (bei SIEMENS) |
| - | //ASSUPD | $ASS/ASSUPD.DAT | Ausgabe für die Option NUPDAT |
| - | //ASSAU | $ASS/ASSAU | Ausgabe für die Option ASSAU bzw. ASSAU_KOPF Host: F B 80, PC: Textdatei |
Restriktionen:
In einem Programmlauf können nur die Daten für ein Arbeitsgebiet übernommen werden.
Besonderheiten:
Wird PCL1001 vorzeitig beendet, so wird ein gezielter Programmabbruch erzeugt. Vorzeitiges Programmende liegt vor, wenn- es durch Angaben in den Vorlaufkarten erzwungen wird
- wenn mehr als 100 fehlerhafte Summensätze erkannt werden. Der Wert von 100 kann durch Vorlaufkarte übersteuert werden (s.u. Option 'FEHLER=NNNN').
Das Datenmengenproblem
Das Programm PCL1001 (wie auch das Programm PCL1002) sind darauf ausgelegt, große Datenmengen zu verarbeiten. So gibt es Schnittstellendateien, die mehrere Millionen Sätze enthalten. Jeder Satz der Schnittstelle muss intern in PCL1001 noch zusätzlich vervielfältigt werden (entsprechend der Anzahl der nicht generierbaren Verdichtungsstufen). Das entstehende Datenvolumen wäre dann noch zu sortieren, ein Unterfangen, das von vornherein zum Scheitern verurteilt ist.
Es wurde daher eine portionsweise Verarbeitung der Schnittstellendatei realisiert. Es werden n Sätze der Schnittstellendatei eingelesen, auf das Format der internen Schnittstellendatei gebracht und in die Datei ASSWONN geschrieben. Dann wird ein Sort aufgerufen.
In der Sort-Input-Phase wird die Datei ASSWONN seq. gelesen,
jeder gelesene Satz wird entsprechend den Anforderungen der
Verdichtungsstufen vervielfältigt und dann dem SORT
übergeben.
In der Sort-Output-Phase erfolgt die Verdichtung. Beim ersten
Aufruf des Sort werden die verdichteten Summensätze in eine
Datei ASSWKnn geschrieben. Bei den Folgeaufrufen werden die im
vorhergehenden Aufruf erzeugten verdichteten Summensätze aus
einer Datei ASSWKnn sofort mit den vom SORT gelieferten Sätzen
gemischt und verdichtet und das Ganze in eine Datei ASSWKmm
gestellt. ASSWKnn wird dann im nächsten Aufruf wieder als
Ausgabedatei verwendet.
Beim letzten Aufruf des Sort wird auf die Datei ASSOUNN
ausgegeben.
Es werden zwei Arbeitsdateien ASSWK01 und ASSWK02 benötigt.
Bei kleinen Datenmengen kann der erste Aufruf des Sort
auch schon der letzte sein. In diesem Fall werden keine
Dateien ASSWKnn benötigt. Die Ausgabe erfolgt sofort
und vollständig auf ASSOUNN.
Fortschreibung stillgelegter Verdichtungsstufen:
Stillgelegte Verdichtungsstufen werden standardmäßig bei der Folgeeinspeicherung nicht fortgeschrieben. Dies kann mittels der Option VSTNR=nn übersteuert werden. Wenn Sie mit der Option VSTNR arbeiten, müssen Sie alle Verdichtungsstufen, in die Einspeicherungen vorgenommen werden sollen, in der Vorlaufkarte angeben. Dabei muss natürlich auf Datenkonsistenz geachtet werden. So dürfen zum Beispiel keine Datensätze verloren gehen oder doppelt eingespeichert werden.
Um die Regeln zur Auswahl der Verdichtungsstufen zu verstehen, muss man den Begriff der Verdichtungsstufenmenge kennen. Dazu betrachten wir einen Wert, der bei der Einspeicherung angeliefert wird und dazu alle Verdichtungsstufen, in denen dieser Wert verwendet wird. Dann bilden jeweils die Verdichtungsstufen, in denen exakt dieselben Schlüssel ausgeprägt sind und die die gleiche Schlüsselreihenfolge haben, eine Verdichtungsstufenmenge.
Folgende Regeln sind nun zu beachten :
- Aus jeder Verdichtungsstufenmenge (pro angeliefertem Wert) darf höchstens eine Verdichtungsstufe ausgewählt werden.
- Aus jeder Verdichtungsstufenmenge, die eine aktive Verdichtungsstufe enthält, muss genau eine Verdichtungsstufe ausgewählt werden.
- Alle aktiven sequentiellen Verdichtungsstufen müssen angegeben werden.
- Stillgelegte sequentielle Verdichtungsstufen werden nicht berücksichtigt.
Generierung von Verdichtungsstufen:
Der Begriff "GENERIERBARE VERDICHTUNGSSTUFE":
Eine Verdichtungsstufe V1 ist aus anderen Verdichtungsstufen
generierbar, wenn die Verdichtungsstufen ungleich V1, in denen
mindestens die in V1 ausgeprägten Schlüssel auch ausgeprägt
sind, zusammen alle verwendeten Werte von V1 auch verwenden.
Schlüsselrelationen im Arbeitsgebiet sind per Definition nicht
generierbar.
Standardmäßig werden während der Verarbeitung der
Schnittstellendatei im Programm PCL1001 interne Schnittstellensätze
nur für nicht generierbare Verdichtungsstufen erzeugt.
Gibt es generierbare Verdichtungsstufen, so stehen am Ende
der Verarbeitung der Schnittstellendatei die internen
Schnittstellensätze für nicht generierbare Verdichtungsstufen
in verdichteter Form in einer Datei ASSWKnn.
Zur Generierung der generierbaren Verdichtungsstufen
wird die Datei ASSWKnn sequentiell gelesen, daraus interne
Schnittstellensätze (noch nicht verdichtet) erzeugt und in
ASSWONN gestellt.
Mit Hilfe des Sort wird dann ASSWONN sortiert und verdichtet,
mit ASSWKnn gemischt und nach ASSOUNN ausgegeben.
Hierbei kann es passieren, dass auf die Datei ASSWONN sehr
viele Sätze ausgegeben werden. Die erzeugte Datenmenge wäre
für einen Sort-Aufruf ev. zu groß. In diesem Fall kann
eine portionsweise Verarbeitung wie bei der Verarbeitung der
externen Schnittstelle aktiviert werden. Eine portionsweise
Verarbeitung benötigt eine dritte Arbeitsdatei ASSWK03.
Diese muss in der JCL zur Verfügung gestellt werden
und via Vorlaufkarte (ASSWK = 3) muss dies dem Programm
mitgeteilt werden.
Insgesamt wird durch obiges Verfahren die Anzahl der
erzeugten (und somit zu sortierenden und verdichtenden)
internen Schnittstellensätze i.a. drastisch reduziert.
Lassen sich generierbare Verdichtungsstufen aus
unterschiedlichen anderen Verdichtungsstufen generieren,
so werden zur Generierung die Verdichtungsstufen mit den
wenigsten Sätzen genommen. Anzahl Sätze pro Verdichtungsstufe
wird aus SST023CV.CANZSA (Steuerungsdatenbank) entnommen.
Bei der ersten Folgeeinspeicherung für ein Arbeitsgebiet
existiert CANZSA noch nicht, die Auswahl der Verdichtungsstufen,
aus denen generiert wird, ist dann rein zufällig.
Die Generierung von Verdichtungsstufen kann von außen
ausgeschaltet werden (OPTION 'NOVSTGENER' in der Vorlaufkarte).
Bei Eingabe dieser OPTION werden alle Verdichtungsstufen als
nicht generierbar angenommen und dementsprechend verarbeitet.
Verdichtungsstufen aus generierbaren Verdichtungsstufen
generieren:
Betrachtet man allein die Menge der generierbaren
Verdichtungsstufen, so kann diese Menge wieder in zwei Teilmengen
zerlegt werden: Verdichtungsstufen, die aus bereits
generierbaren Verdichtungsstufen generiert werden können
bzw. nicht.
Beispiel:
- Die Verdichtungsstufe 1 enthalte die Schlüssel S1, S2, S3 und S4, die Werte W1 und W2.
- Die Verdichtungsstufe 2 enthalte die Schlüssel S1, S2 und S4, die Werte W1 und W2.
- Die Verdichtungsstufe 3 enthalte die Schlüssel S1 und S2, den Wert W1.
- Die Verdichtungsstufe 4 enthalte die Schlüssel S1 und S4, den Wert W2.
Die Verdichtungsstufen 1 ist nicht generierbar.
Die Verdichtungsstufen 2, 3 und 4 sind alle generierbar
(aus Verdichtungsstufe 1).
Die Verdichtungsstufen 3 und 4 sind jedoch auch aus
Verdichtungsstufe 2 generierbar.
Folgendes soll erreicht werden:
Zunächst sollen die Daten für die nicht generierbaren
Verdichtungsstufen (im Beispiel Verdichtungsstufe 1) erzeugt
werden. Dann werden hieraus die Daten für die nicht
generierbaren Verdichtungsstufen, die nicht aus generierbaren
Verdichtungsstufen generiert werden können,
(im Beispiel Verdichtungsstufe 2) erzeugt und zum Schluss
hieraus die Daten für die generierbaren Verdichtungsstufen,
die aus generierbaren Verdichtungsstufen
generierbar sind (im Beispiel Verdichtungsstufe 3 und 4).
Das geschilderte Verfahren benötigt 4 Arbeitsdateien.
Es wird durch die Angabe ASSWK = 4 in der Vorlaufkarte
aktiviert.
Folgende Besonderheiten sind zu beachten:
Index-Verdichtungsstufen gelten u.U. (s.u.) als
generierbar. Sie gelten jedoch nie als aus generierbaren
Verdichtungsstufen generierbar.
Existieren explizite Generierungsangaben (s.u.), so wird das hier geschilderte Verfahren nicht aktiviert.
Um sicherzustellen, dass bei ASSWK = 4 nicht zu große Verdichtungsstufen generiert werden, gilt eine Verdichtungsstufe als generierbar aus generierbaren Verdichtungsstufen, wenn sie nicht zu "groß" ist. Eine Verdichtungsstufe gilt als nicht zu "groß", wenn ihre Satzanzahl kleiner als ein Zehntel der Satzanzahl der größten Verdichtungsstufe, die eingespeichert wird, ist. Bei der Ersteinspeicherung in ein Arbeitsgebiet sind die genannten Satzanzahlen nicht bekannt. In diesem Fall gibt es keine zu großen Verdichtungsstufen.
Explizite Generierungsangaben
Die Generierung von Verdichtungsstufen kann explizit über Vorlaufkarten vorgegeben werden:
GENVST: Quell-Verdichtungsstufe -> Ziel-Verdichtungsstufe
Beispiel: GENVST: 17 -> 23
Die Verdichtungsstufe 23 soll aus der Verdichtungstufe 17
generiert werden.
Verdichtungsstufen mit Werten:
Eine Ziel-Verdichtungsstufe kann aus einer Quell-Verdichtungsstufe
generiert werden, wenn alle Schlüssel, die in der
Ziel-Verdichtungsstufe ausgeprägt sind, auch in der
Quell-Verdichtungsstufe ausgeprägt sind
und
alle Werte, die in der Ziel-Verdichtungsstufe enthalten
sind, auch in der Quell-Verdichtungsstufe enthalten sind
(unabhängig von der externen Schnittstelle).
Index-Verdichtungsstufen:
Eine Index-Verdichtungsstufe kann aus einer Quell-Verdichtungsstufe
generiert werden, wenn alle Schlüssel, die in der
Index-Verdichtungsstufe ausgeprägt sind auch in der
Quell-Verdichtungsstufe ausgeprägt sind und die
Quell-Verdichtungsstufe selbst keine Index-Verdichtungsstufe ist.
Es können mehrere GENVST-Angaben gemacht werden, wobei jede Angabe vollständig in einer Vorlaufkarte stehen muss. Zu einer Ziel-Verdichtungsstufe darf nur eine Quell-Verdichtungsstufe angegeben werden, falsch wäre also
- GENVST: 17 -> 23
- GENVST: 18 -> 23
Quell-Verdichungsstufen dürfen nicht als Ziel-Verdichtungsstufen angegeben werden und umgekehrt.
Folgende Vorlaufkarten-Optionen beeinflussen die GENVST-Angaben:
Ist CANZSA_GENER_MAX angegeben, so werden bei Verdichtungsstufen mit Werten als Quelle nur Verdichtungsstufen akzeptiert, die noch nicht eingespeichert sind oder die weniger Sätze enthalten, als bei CANZSA_GENER_MAX vorgegeben wurde.
Index-Verdichtungsstufen werden werden als Ziel nur wirksam, wenn auch INDEX_GEN = n angegeben ist, n > 0. Als Quelle werden dann nur Verdichtungsstufen akzepiert, die weniger als n Sätze enthalten oder noch nicht eingespeichert wurden.
Ist NOVSTGENER angegeben, so wirken die GENVST-Angaben nicht.
Existieren GENVST-Angaben, die nicht aktzeptiert werden, so wird das Programm abgebrochen. Soll das Programm nicht abgebrochen werden, so ist zusätzlich die Vorlaufkarten-Option GENVST_NICHT_ABBRECHEN anzugeben. Grundsätzlich werden nicht aktzeptierte GENVST-Angaben protokolliert. Ziel-Verdichtungsstufen, deren GENVST-Angaben nicht erfüllbar sind, werden wie nicht generierbare Verdichtungsstufen behandelt.
Vorzeitiges Programmende:
Nach jedem SORT-Aufruf wird geprüft, ob durch Vorlaufkarten-Optionen ein vorzeitiges Programmende erzwungen werden soll. Die zeitliche Frequenz dieser Prüfung richtet sich also nach der Häufigkeit der SORT-Aufrufe. Die Frequenz der Sortaufrufe richtet sich nach der Verarbeitungs-OPTION 'SORTMAX', in der angegeben wird, wieviele Sätze pro Aufruf sortiert werden sollen.
ACHTUNG:
Ein Satz aus der Schnittstellendatei ergibt N zu sortierende Sätze, wobei N die Anzahl der nicht generierbaren Verdichtungsstufen ist.
Ist die Schnittstellendatei vollständig verarbeitet, folgt ein abschließender SORT-Aufruf. Gibt es generierbare Verdichtungsstufen, so kann es bei der Generierung von Verdichtungsstufen zusätzliche SORT-Aufrufe geben.
Folgende Kriterien führen zum vorzeitigen Programmende:
- Es sind aus der Schnittstellendatei bereits mehr Sätze als in der Verarbeitungs-OPTION 'SAETZE' angegeben wurde, verarbeitet worden.
- Die Laufzeit des Programms ist größer als in der Verarbeitungs-OPTION 'MINUTEN' angegeben wurde.
Wird das Programm PCL1001 aufgrund von Verarbeitungsoptionen vorzeitig beendet, wird es abnormal beendet, damit eventuelle Folgesteps des aktuellen Jobs nicht mehr ausgeführt werden.
Verzögerter Update der Parameterdatenbanken
Die Update's auf die Parameter-Datenbanken werden erst
am Programmende von PCL1001 durchgeführt (Ausnahme
Schlüssel-Datenbank. s.u.).
Ist die Option NUPDAT gesetzt, so werden alle Update's
der Parameterdatenbanken auf die Datei ASSUPD ausgegeben.
Diese Update's können (müssen) dann mit dem Programm PCL1032
nachgeholt werden.
Eine Sonderbehandlung erfahren Schlüsselausprägungen.
Sie werden u.U. (in Abhängigkeit von Vorlaufkarten-Optionen)
sofort auf die Schlüssel-Datenbank gespeichert.
Siehe hierzu auch die Beschreibung der Optionen KEYUPDATE
bzw. KEYZU.
Implementation der „privaten“ Checkpoint-Schreibung
Checkpoints werden mit dem Programm MCL0699 geschrieben.
Die Aufrufe auf MCL0699 werden durch die Vorlaufkarten-Option
CHKP_PRIVAT aktiviert. Checkpoints werden nur dann
geschrieben, wenn in der betreffenden Installation
MCL0699 dafür ausgelegt ist.
Checkpoints werden nur nach Änderungen der
Parameter-Datenbanken geschrieben.
Werden Schlüsselausprägungen während der Verarbeitung
der externen Schnittstelle (nicht am Programmende) auf
die Schlüssel-Datenbank ergänzt, so werden die
betreffenden Änderungen mit installationsabhängigen
Verfahren fixiert und zwar unabhängig von der privaten
Checkpoint-Schreibung.
Benutzung eines Schreib-cache-Verfahrens zur Erzeugung nicht generierbarer Verdichtungsstufen:
Die Eingabe der OPTION 'VORVERDICHTEN' bewirkt eine andere Art der Erzeugung der nicht generierbaren Verdichtungsstufen. Jeder von ASSIN01 gelesene Summensatz wird auf internes Format gebracht und zunächst in eine programminterne Tabelle gestellt (SCHREIB-cache). Bei jedem weiteren Summensatz wird zunächst versucht, diesen soweit wie möglich in diesen SCHREIB-cache einzuarbeiten. Ist dies nicht möglich (Änderung des internen Schlüssels), so wird zunächst der alte Tabelleneintrag nach ASSWONN geschrieben und dann der neue Inhalt aufgenommen.
Eine Vervielfältigung im USER-EXIT E15 entfällt in diesem Fall.
Eine Sortierung der Daten von ASSWONN erfolgt immer dann, wenn mindestens N Sätze ('SORTMAX=N') auf ASSWONN geschrieben wurden und natürlich bei EOF von ASSIN01.
Der SCHREIB-cache enthält M Einträge, wobei M die Anzahl der nicht generierbaren Verdichtungsstufen ist.
Die OPTION 'VORVERDICHTEN' empfiehlt sich immer dann, wenn die externe Schnittstellendatei sortiert vorliegt. Sortiert heißt in unserem Fall: Der höchste Sortierbegriff ist der Schlüsselinhalt desjenigen Schlüssels, der in der zugehörigen Summen-DB am weitesten links steht (kleinste CREPO), ... , niedrigster Sortierbegriff ist der Schlüsselinhalt desjenigen Schlüssels, der in der zugehörigen Summen-DB am weitesten rechts steht (größte CREPO).
Beim Generieren der generierbaren Verdichtungsstufen wird stets mit der obigen Vorverdichtung gearbeitet. Ein Ausschalten der Generierung ist voraussichtlich nur in wenigen Anwendungsfällen sinnvoll. Es ist sicherlich dann sinnvoll, wenn man bei der Generierung der Verdichtungsstufen Platzprobleme auf ASSWONN bekommt.
Platzbedarf für Dateien
Auf die Dateien ASSWONN, ASSWK01, ASSWK02, ASSWK03, ASSWK04 und ASSOUNN werden interne Summensätze geschrieben. Diese Sätze bestehen aus einem Schlüsselteil und einer Wertetabelle. Der Schlüsselteil hat die Länge des KEYS der zugehörigen Summen-DB + 2. In Abhängigkeit von Vorlaufkarten-Optionen (z. B. VERDICHTEN) ist ein Eintrag der Wertetabelle unterschiedlich lang. Die maximale Länge beträgt 14 Byte. In die Wertetabelle werden i.a. nur Werte ungleich Null aufgenommen.
Beispiel:
Die externe Schnittstelle enthalte 10 Werte mit gleichem Wertezeitraum. Der KEY der Summen-DB habe die Länge 30. Daraus ergibt sich eine maximale Satzlänge von 30 + 2 + 10 * 14 = 172 BYTES (+ Satzlängenfeld).
Dateigrößen:
ASSWONN:
Die Datei ASSWONN kann in zwei Funktionen während des Programmlaufes verwendet werden:
- Während der portionsweisen Verarbeitung der Ext. Schnittstellendatei ASSIN01 wird ASSWONN i.a. mehrfach erstellt. Die Anzahl der geschriebenen Sätze pro Erstellung hängt von diversen Parametern ab (s.u.).
- bei der Generierung der generierbaren Verdichtungsstufen
Damit hängt die Dateigröße von zwei Faktoren ab: (Der Datei-Bedarf ist das Maximum von Punkt 1. und 2..)
-
SORTMAX-Parameter:
-
ohne Vorverdichten:
Anzahl-Sätze = SORTMAX / Anzahl nicht generierbarer Verdichtungsstufen. - mit Vorverdichten:
Anzahl-Sätze = SORTMAX.
-
ohne Vorverdichten:
- Verdichtungsstufengenerierung
-
Verdichtungsstufengenerierung ist nicht ausgeschaltet
(keine Option NOVSTGENER):
In diesem Fall werden die Sätze aller generierbaren Verdichtungsstufen aus ASSWK01 oder ASSWK02 erzeugt und nach ASSWONN (mit Vorverdichten) geschrieben. Dies kann in Extremfällen zu sehr großen Datenmengen führen und zwar dann, wenn- die ausgeprägten Schlüssel der generierbaren Verdichtungsstufen vorwiegend rechts im KEY der zugehörigen Summen-DB angeordnet sind.
- ASSWK01/ASSWK02 bereits große Ausmaße angenommen haben.
- Verdichtungsstufengenerierung ist ausgeschaltet:
(Option NOVSTGENER):
Es wird nicht auf ASSWONN geschrieben.
-
Verdichtungsstufengenerierung ist nicht ausgeschaltet
(keine Option NOVSTGENER):
ASSWK01/ASSWK02:
Diese Dateien müssen so groß dimensioniert werden, dass sie
die Endausgabedatenmenge der nicht generierbaren
Verdichtungsstufen aufnehmen können, es sei denn, man arbeitet
mit 'NOVSTGENER' und so großem SORTMAX-Parameter, dass sofort
auf ASSOUNN geschrieben wird.
In diesem Fall werden ASSWK01 und ASSWK02 nicht benutzt.
ASSWK03/ASSWK04:
Diese Dateien werden beim Generieren von Verdichtungsstufen
benutzt. Je nach Situation müssen sie das Volumen der
generierbaren Verdichtungsstufen aufnehmen können.
ASSOUNN:
Diese Datei enthält die komplette interne Schnittstelle für
komprimierte Verdichtungsstufen. Eine Schätzung, wie viele
Sätze diese Datei enthält, ist praktisch nicht möglich. Der
Platzbedarf für ASSOUNN hängt entscheidend davon ab, wie stark
die externe Schnittstellendatei verdichtet werden kann.
Verdichtungsverhältnisse von nahezu 1:1 bis 20:1 kommen in
der Praxis vor.
Laufzeitprobleme:
Bei großen externen Schnittstellendateien und Arbeitsgebieten mit mehreren Verdichtungsstufen können optimale Vorlaufkartenangaben zu deutlicher Programmlaufzeitverkürzung führen:
- Der SORTMAX-Parameter sollte nicht zu klein gewählt werden. Die Voreinstellung von zwei Millionen sollte, wenn die SORTWK-Bereiche und ASSWONN hinreichend groß gewählt werden können, nicht verkleinert werden, eher vergrößert.
- Unter Windows/Linux ist ein anderes Sort-Verfahren aktiv. Hier empfiehlt sich eine kleinere Einstellung für SORTMAX (1 Million)
-
Die Generierung von Verdichtungsstufen sollte höchstens dann
ausgeschaltet werden, wenn die externe Schnittstellendatei
sortiert vorliegt (s.o.) und wenn im Arbeitsgebiet
hauptsächlich über die Schlüssel verdichtet wird, die im
KEY der zugehörigen Summen-DB weit rechts liegen (große
CREPO).
Werden Verdichtungsstufen generiert, so sollte ASSWK03 und ev. sogar ASSWK04 (s.o.) zur Verfügung gestellt werden. -
Das VORVERDICHTEN sollte eingeschaltet werden:
- wenn es genau eine nicht generierbare Verdichtungsstufe gibt oder
- wenn die externe Schnittstellendatei sortiert vorliegt.
Adressraumbedarf für Ausprägungstabellen
Schlüsselausprägungen werden von PCL1001 von der externen Darstellung in eine interne Nummer umgeschlüsselt. Diese Umschlüsselung wird mit Hilfe von Ausprägungstabellen durchgeführt. Für jeden verwendeten Schlüssel des betreffenden Arbeitsgebiets wird programmintern eine Schlüsselausprägungstabelle angelegt. Jede Ausprägung belegt hierbei einen Tabellenplatz. Der Platz, der für eine Ausprägung erforderlich ist, variiert i.a. von Schlüssel zu Schlüssel und ist abhängig davon, ob mit Zeitprüfung gearbeitet wird. Ein Tabelleneintrag ist folgendermaßen aufgebaut:
-
interne Nummer
2 Byte (bei interner Länge 1 oder 2)
4 Byte (bei interner Länge 3 oder 4) - Schlüsselinhalt
1 bis n Byte in Abhängigkeit von der externen Länge des Schlüssels. - Gültigkeitsintervall
8 Byte
Dieser Eintrag existiert nur, wenn die Zeitprüfung eingeschaltet ist (siehe Option ZEITPRUEF).
In die oben beschriebenen Tabellen werden
alle Schlüsselausprägungen gestellt, die im
Arbeitsgebietsabzug enthalten sind.
Schlüsselausprägungen von Schlüsseln der internen Länge
3 bzw. 4 werden in Abhängigkeit der Vorlaufkarten-Option
UMSCHLMAX bzw. UMSCHLPLATZ (s.u.) in Tabellen gestellt.
Ausprägungen, die automatisch ergänzt werden, werden in
speziellen Überlauftabellen gesammelt. Diese werden
sortiert verwaltet. Werden sehr viele Schlüsselausprägungen
ergänzt, so kann das sortierte Einarbeiten in diese
Überlauftabellen zu erhöhtem CPU-Bedarf führen.
Überlauftabellen werden pro Schlüssel verwaltet.
Um nicht zu viel Adressraum zu beanspruchen, wird zunächst
mit "kleinen" Überlauftabellen gearbeitet. Läuft eine
Überlauftabelle über, so wird eine neue, größere
eingerichtet.
Bei Schlüsseln der interne Länge 3 oder 4 wird
installationsabhängig durch die Variable ALC-AU-UE-MAX
(Text-Datenbank, siehe Handbuch INSTALLATION) die maximale
Tabellengröße der Überlauftabelle festgelegt.
Es ist erstrebenswert, nicht zu viele Schlüsselausprägungen ergänzen zu lassen. Eine Reduktion kann durch Einsatz der Option KEYZU erreicht werden (siehe entsprechende Beschreibung).
Zeitprüfung von Schlüsselausprägungen
Schlüsselausprägungen können in der Transaktion ST06 mit zeitlichen Gültigkeitsintervallen versehen werden (Ausprägung ist gültig von, bis). Beim Prüfen von externen Schnittstellen kann gegen diese Zeitintervalle geprüft werden. Überprüft werden dabei Summensätze. Es werden hierbei alle Zeitangaben zu Werten mit Werteinhalt ungleich 0 überprüft. Bei jeder aktiven Schlüsselausprägung (d.h. der betreffende Schlüssel ist in mindestens einer aktiven Verdichtungsstufe ausgeprägt und die aktuelle Schnittstelle enthält wenigstens einen verwendeten Wert dieser Verdichtungsstufe) wird geprüft, ob jedes Wertedatum im Gültigkeitsintervall enthalten ist. Die Prüfung entfällt, wenn die Schlüsselausprägung noch nicht in der Schlüsseldatenbank enthalten ist.
Die geschilderte Zeitprüfung ist standardmäßig nicht eingeschaltet. Sie muss explizit durch die OPTION ZEITPRUEF (s.u.) angefordert werden. Zu beachten ist, dass die Zeitprüfung zusätzliche Rechenzeit und zusätzlichen Adressraum für Schlüsselausprägungstabellen erfordert. Die Zeitprüfung erfolgt grundsätzlich monatsgenau, auch wenn in der externen Schnittstelle tagesgenaue Daten angeliefert werden.
VORLAUFKARTE:
Die Optionen in der Vorlaufkarte müssen durch Komma getrennt
werden. Sie können zwischen Hochkommata gestellt werden.
Beispiel: NMAXDAT,SORTMAX=1000000
oder: 'NMAXDAT','SORTMAX=1000000'
Es werden nur die Stellen 1 - 72 berücksichtigt.
Mögliche Optionen:
| Option | Bedeutung | Voreinstellung |
|---|---|---|
| DRUCK | Protokoll maximal erzeugen | DRUCK |
| NDRUCK | Protokoll unterdrücken | DRUCK |
| MAXDAT | es wird geprüft, ob das Wertedatum aufsteigend ist. Es wird nur der Monat geprüft, auch bei Tagesarbeitsgebieten (vgl. MAXDAT_T). | MAXDAT |
| NMAXDAT | Es wird nicht geprüft, ob das Wertedatum aufsteigend ist. Impliziert MAXDATGLEICH (s.u.). | MAXDAT |
| MAXDAT_T | Nur wirksam bei Tagesarbeitsgebieten: Es wird geprüft, ob das Wertedatum aufsteigend ist.
Nicht reguläre Datumsangaben (z.B. 13. Monat oder 32. Tag) beim Einspeicherungsdatum oder im Kopfsatz
der Schnittstelle werden ggf. auf das nächstkleinere reguläre Datum vorgeschaltet. Die Tagesdifferenz wird
also wie beim Werteoperator ZEITDIFFERENZ mit dem dortigen Format "T" berechnet, bei Differenz > 1 wird ein Fehler erzeugt. Unverträglich mit Option NMAXDAT. |
nicht MAXDAT_T |
| MAXDAT_TA, MAXDAT_TB, MAXDAT_TC | Nur wirksam bei Tagesarbeitsgebieten: Wie MAXDAT_T, aber es werden nur Arbeitstage gezählt. Die Berechnung erfolgt auch hier analog zum Werteoperator ZEITDIFFERENZ, mit den dortigen Formaten "TA", "TB" bzw. "TC". | nicht MAXDAT_TA etc. |
| MAXDATGLEICH | Wertedatum darf <= dem Datum der letzten Einspeicherung sein, muss aber >= dem Datum der ersten Einspeicherung sein | nicht MAXDATGLEICH |
| UPDAT | UPDATE Parameterdatenbanken | UPDAT |
| NUPDAT | kein UPDATE der Parameterdatenbanken | UPDAT |
| MINUTEN=NNNN | maximale Laufzeit in Minuten | 1000000 |
| SAETZE=NNNNNN | Maximal zu verarbeitende Sätze aus Schnittstelle. 0 bedeutet kein Limit. |
99000000 |
| SORTMAX=NNNN | maximal pro SORT-Aufruf zu sortierende Sätze | 2000000 |
| AGNR=NN | Festlegung, für welches Arbeitsgebiet ASSIN01 gilt | fehlt diese Angabe, so wird die Schnittstellennummer aus dem Kopfsatz genommen |
| KEYZU | Diese Option dient nur
zum Ergänzen von
Schlüsselausprägungen
aus der Schnittstelle in
die Schlüssel-DB. Sie
darf nur für Sonderläufe
hergenommen werden. Anwendungsfall: Vor Einspeicherung Schlüsselausprägungen auf Schlüssel-Datenbank bringen. SAETZE sollte kleiner als die Anzahl der externen Schnittstellensätze gesetzt werden. Weil das Abbruchkriterium nur zum Zeitpunkt des Sortieraufrufs geprüft wird, ist SORTMAX unter Berücksichtigung der Zahl unter SAETZE=... und den Optionen NOVSTGENER und VORVERDICHTEN geeignet zu wählen. KEYZU bewirkt, dass grundsätzliche keine interne Schnittstellendatei erzeugt wird. Es erfolgt eine optimierte Verarbeitung bei der u.a. kein Sort durchgeführt wird. Weiterhin werden keinerlei Work-Dateien benötigt. A c h t u n g: Dementsprechend erfolgt eine unvollständige Verarbeitung | nicht KEYZU |
| NOKEYZU | Neue Ausprägungen in der externen Schnittstelle führen zu einem Fehler NOKEYZU impliziert FEHLER = 0 | nicht NOKEYZU |
| FEHLER=nnn | Obergrenze für fehlerhafte Summensätze | 100 werden mehr fehlerhafte Summensätze als maximal zulässig erkannt, so wird PCL1001 vorzeitig beendet. |
| EXIT=KURZ | Bei dieser Angabe erwartet PCL1001 eine externe Schnittstelle im kurzen Format. Diese Angabe muss unbedingt mit dem tatsächlichen Format der Schnittstelle harmonieren. Zur Zeit ist jede Angabe identisch mit KURZ. | keine kurze Schnittstelle |
| NOVSTGENER | Generierung von Verdichtungsstufen aus anderen Verdichtungsstufen ausschalten | Verdichtungsstufen generieren |
| VORVERDICHTEN | siehe ausführliche Beschreibung oben. | nicht VORVERDICHTEN |
| CHKP_PRIVAT | aktivieren der „privaten“ Checkpoint-Schreibung | nicht CHKP_PRIVAT |
| INVERS | der Werteinhalt wird mit
inversen Vorzeichen
verarbeitet Anwendungsfall: Fehleinspeicherungen rückgängig machen |
nicht INVERS |
| ZEITPRUEF | Zeitprüfung von Schlüsselausprägungen einsch. s.o. | nicht ZEITPRUEF |
| KEYLIST | neu über die ext. Schnittstelle hinzugekommene Ausprägungen zum jeweiligen Schlüssel protokollieren | nicht KEYLIST |
| VSTNR=nnn | Verdichtungsstufen, in die
eingespeichert werden soll,
explizit angeben.
Hierbei ist für nnn die
jeweilige Verdichtungsstufennummer anzugeben. Beispiel: VSTNR=17 , VSTNR=31 Mittels dieser Option kann man Einspeicherungen in stillgelegte Verdichtungsstufen vornehmen. |
nicht VSTNR |
| ASSIN=nn | Wird z.B. ASSIN=03 angegeben, so werden nacheinander die Dateien ASSIN01, ASSIN02, ASSIN03 gelesen u. verarbeitet. Das Verarbeitungsergebnis entspricht einer Konkatenierung von ASSIN01, ASSIN02 und ASSIN03 unter dem DD-Namen ASSIN01. Diese Option ist vorwiegend für Siemens-Umgebungen gedacht. | keine Angabe |
| NOWEPRUEF | Diese Option bewirkt
folgendes: - Eindeutigkeit von Wertenummer + Wertedatum in Kopfsätzen wird nicht mehr geprüft. - Wird im Kopfsatz nur ein Zeitraum angekündigt, so wird aus den zugehörigen Summensätzen nur der angekündigte Zeitraum übernommen. |
WEPRUEF |
| MCL0169 | Vor der Verarbeitung eines Summensatzes wird der User-Exit MCL0169 aufgerufen, um den aktuellen Summensatz vor der Verarbeitung ev. zu verändern. | nicht MCL0169 |
| VERDICHTEN | Diese Option bewirkt, dass Zwischenergebnisse auf ASSWONN, ASSWK01, ASSWK02, ASSWK03 und ASSWK04 verdichtet gespeichert werden. Sie reduziert dort den Platzbedarf, erfordert dafür jedoch mehr CPU-Zeit. Ebenso wird der Platzbedarf für die Sort-Dateien reduziert. | nicht VERDICHTEN |
| KEYUPDATE | Mit dieser Option können
mehrere PCL1001 für
verschiedene Arbeitsgebiete
parallel laufen. Dabei
werden Schlüsselausausprägungen, die nicht
im PCL1004-Abzug enthalten
sind, sofort in die
Schlüsseldatenbank eingefügt,
sofern sie
dort noch nicht enthalten
sind. Diese Option erfordert
ein serialisiertes
Zugreifen zur Schlüsseldatenbank. Diese Option steht zur Zeit nur für ISAM und auf Anforderung für DL/I mit IMS zur Verfügung. |
nicht KEYUPDATE bei KEYLUECKE gilt jedoch KEYUPDATE |
| KEYLUECKE | Beim Ergänzen von
Schlüsselausprägungen
werden eventuelle Lücken
aufgefüllt. Impliziert KEYUPDATE |
nicht KEYLUECKE |
| KEYUPDATE_TUNE |
Wirkt nur bei KEYUPDATE (und KEYLUECKE).
Bei ASS-ISAM die Serialisation auf die Schlüsseldatenbank nicht sofort freigeben. Damit ist diese faktisch für den gesamten Lauf im exklusiven Zugriff von PCL1001. Sinnvoll nur auf Windows-Netzlaufwerk. |
nicht KEYUPDATE_TUNE |
| INDEX_GEN=n | Generierung von Indizes (Relationen) aus Verdichtungsstufen mit mindestens 1 und höchstens n - 1 Sätzen. | INDEX_GEN=0 bei UMBUCH gilt jedoch INDEX_GEN=0 |
| UMBUCH | Umbuchung von Bestandswerten aus einer Änderungsschnittstelle von dem Dienstprogramm PCL1019. | nicht UMBUCH impliziert NOVSTGENER VORVERDICHTEN INDEX_GEN=0 nicht VSTNR |
| UMSCHLMAX=n | Anzahl Ausprägungen pro Schlüssel mit interner Länge 3 oder 4, die in Hauptspeicher maximal eingelesen werden | UMSCHLMAX=0 |
| UMSCHLPLATZ=n | Adressraum in Bytes, in den Ausprägungen von Schlüssel mit interner Länge 3 oder 4 in den Hauptspeicher eingelesen werden | UMSCHLPLATZ=0 |
| CANZSA_GENER_MAX = n |
Generierung aus Verdichtungsstufen mit maximal n Sätzen | CANZSA_GENER_MAX=0 Steuerung nicht aktiv |
| NO_EURO_PRUEF | Mit dieser Optionen können
Prüfungen bei Euro-Werten
mit Stichtag bei Bestandsfortschreibung
durch Bewegungsanlieferung
ausgeschaltet werden. Diese
Option ist gefährlich. Sie
ist nur zulässig, wenn
sichergestellt ist, dass
in der Schnittstelle
Gegenbuchungen enthalten
sind, die bewirken, dass
sich die Bewegungen nur
auf einen Zeitpunkt auswirken. Dies ist auch nach PCL1019 der Fall mit BEWEGUNG_BESTAND, über ein Zeitintervall und ohne Euro-Umrechnung. |
Prüfen |
| SICHTEN | Diese Option bewirkt, dass eine aktive Verdichtungsstufe betrachtet wird, wenn die Schnittstelle einen ausgeprägten Schlüssel dieser Verdichtungsstufe und einen verwendeten Wert enthält. Betrachtete Verdichtungsstufen müssen bzgl. der Schlüssel vollständig bedient werden. Die erforderlichen Schlüssel können auch durch die Optionen INHALT bzw. INHALT_ERS geliefert werden. Diese Option ist gefährlich. Sie darf nur benutzt werden, wenn im betreffenden Arbeitsgebiet die Verdichtungsstufen geeignet definiert sind und mit den Einspeicherungen hierfür harmonieren. | keine Sichten |
| EXIT_TEXT | Es wird eine externe Schnittstelle im Textformat erwartet (HSYSDOK,Kap. 5.3) | nicht EXIT_TEXT |
| TAB | Für die externe Schnittstelle im Textformat (EXIT_TEXT) wird statt des Semikolons der Tabulator als Trennsymbol verwendet | nicht TAB |
| BESTANDSUEBERNAHME | Steuerung der Verarbeitung externer Schnittstellen mit Bestandswerten und Bestandsanlieferung (siehe auch PCL1002) | nicht BESTANDSUEBERNAHME |
| GENVST | s.o. | |
| GENVST_NICHT_ABBRECHEN | s.o. | |
| NO_END_CNT_VAL | Zähler für Summensätze im Endesatz nicht prüfen | prüfen |
| ASSWK = n | n = 3 oder 4, Generierung von Verdichtungsstufen optimieren (s.o.) | |
| ISAMSORT | wird ab Release 8.10 ignoriert Das Sortierverfahren wird automatisch bestimmt |
|
| INHALT (...) = ... | Schlüsselinhalte via Vorlaufkarte, s.u. | |
| INHALT_ERS (...) = ... | Schlüsselinhalte via Vorlaufkarte, s.u. | |
| ASSAU | Auf die Schlüsseldatenbank eingefügte Ausprägungen auf die Datei ASSAU ausgeben. | nicht ASSAU |
| ASSAU_KOPF | wie ASSAU, jedoch mit Kopfsatz (Überschrift) | nicht ASSAU_KOPF |
| FB | Externe Schnittstelle ist festgeblockt im langen oder kurzen (EXIT=KURZ) Format. | nicht FB |
| EXIT_VAR | Automatische Erkennung des Formats von externen Schnittstellen.
Das Format wird mit jedem ersten Dateisatz neu ermittelt, der
ein Kopfsatz ist. Es können also mehrere Schnittstellen
unterschiedlichen Formats ein einem Lauf verarbeitet werden.
Zur Zeit wird das kurze (EXIT=KURZ) und lange Format erkannt,
geblockt (FB) und ungeblockt. Das Textformat (EXIT_TEXT) wird
auch erkannt. Wird auch eine Translate-Option (ANSI, BS2000 o.Ä.) angegeben, wird bei jeder neuen Schnittstelle geprüft ob jene dazu passt. Wenn nicht, wird sie für die jeweilige Schnittstelle ignoriert. Dabei wird lediglich geprüft, ob die Schnittstelle in einem EBCDIC- (Host) oder ASCII-basierten (PC) Zeichensatz verfasst ist. Die Translate-Angabe wird dann nur genommen, wenn sie ebenfalls EBCDIC- bzw. ASCII-basiert ist. Diese Funktionalität ist sowohl beim langen-, kurzen- und beim Textformat gegeben. Hinweis: Am PC können nur ASCII-basierte Textschnittstellen verarbeitet werden, am Host nur EBCDIC-basierte. Am PC sollte kein Kopfsatz mit der veralteten Satzart 0 angeliefert werden. Diese Satzart wird von keinem ASS-Programm mehr erzeugt (PCL1019, PCL1081 usw.) |
nicht EXIT_VAR |
| MVS (veraltet: MVS_ANSI, MVS_BS2000) | Externe Schnittstelle von MVS-EBCDIC in den (automatisch bestimmten) Zeichensatz der ASS-Umgebung übersetzen. Der Zielzeichensatz bei den veralteten Optionen (_ANSI, _BS2000) wird ignoriert. | keine Übersetzung |
| BS2000 (veraltet: BS2000_ANSI, BS2000_MVS) | Externe Schnittstelle von BS2000-EBCDIC in den (automatisch bestimmten) Zeichensatz der ASS-Umgebung übersetzen. Der Zielzeichensatz bei den veralteten Optionen (_ANSI, _MVS) wird ignoriert. | keine Übersetzung |
| OS2 (veraltet: OS2_ANSI) | Externe Schnittstelle von Windows (OEM 858) in den (automatisch bestimmten) Zeichensatz der ASS-Umgebung übersetzen. Der Zielzeichensatz bei der veralteten Option (_ANSI) wird ignoriert. | keine Übersetzung |
| ANSI (veraltet: ANSI_OS2) | Externe Schnittstelle von Unix (Standard-ANSI bzw. ISO 8859-1) in den (automatisch bestimmten) Zeichensatz der ASS-Umgebung übersetzen. Der Zielzeichensatz bei der veralteten Option (_OS2) wird ignoriert. | keine Übersetzung |
| CP1252 | Externe Schnittstelle von "Windows-ANSI" (Codepage CP1252, enthält €-Zeichen) in den (automatisch bestimmten) Zeichensatz der ASS-Umgebung übersetzen. | keine Übersetzung |
Generierung von Verdichtungsstufen: CANZSA_GENER_MAX=n
Ist die Vorlaufkartenoption NOVSTGENER nicht angegeben, so unterscheidet PCL1001 zwischen generierbaren und nicht generierbaren Verdichtungsstufen. Die Einteilung hängt allein von den ausgeprägten Schlüsseln und Werten ab, d.h. ob sich die Informationen aus anderen Verdichtungsstufen (durch Summierung) ergeben. Dieses kann in der Praxis dazu führen, dass alle Verdichtungsstufen bis auf die Basis generierbar sind und sich ein ungünstiges Verhalten bzgl. Platz und Laufzeit ergibt. Durch die Angabe von CANZSA_GENER_MAX=n gelten alle Verdichtungsstufen mit 0 oder mehr als n Sätzen als nicht generierbar und werden zum Generieren auch nicht verwendet. Für alle übrigen Verdichtungsstufen wird folgendermaßen verfahren: die Verdichtungsstufen werden intern nach der Anzahl Sätze, die sie enthalten, sortiert. Eine Verdichtungsstufe gilt als generierbar, wenn sich ihre Information aus anderen Verdichtungsstufen ergibt. Diese anderen Verdichtungsstufen sind automatisch nicht generierbar.
Generierung von Indizes (Relationen): INDEX_GEN=n
Standardmäßig sind Indizes nicht aus anderen Verdichtungsstufen generierbar. Über die Vorlaufkartenoption INDEX_GEN=n kann dies abgeändert werden, wobei n für eine positive Zahl steht, zum Beispiel INDEX_GEN=100000. Dann wird zur Generierung eines Index die kleinste Verdichtungsstufe genommen, die mindestens einen Satz und höchstens n - 1 Sätze enthält. Mit INDEX_GEN=0 (dem Standard) wird die Generierung von Indizes deaktiviert. Folglich ist die Angabe der Option bei einer Ersteinspeicherung wirkungslos, da dann noch jede Verdichtungsstufe leer ist. Des weiteren kann weder eine Verdichtungsstufe noch ein Index aus einem Index generiert werden. Intern können bei der Generierung von Indizes sogenannte Nullsätze zu den nicht generierbaren Verdichtungsstufen erzeugt werden. Diese Nullsätze sind notwendig: wenn ein Index für mehrere Verdichtungsstufen geeignet ist und ein Satz der externen Schnittstelle jedoch wegen der verwendeten Werte nicht in die Verdichtungsstufe übernommen werden muss aus der der Index generiert wird. Diese Nullsätze werden erst durch das Dienstprogramm PCL1002 eliminiert.
Die Option INDEX_GEN wird bei Angabe der Option UMBUCH ignoriert.
Umbuchung von Bestandswerten: UMBUCH
Das Umbuchen von Bestandswerten aus einer Schnittstelle des
Dienstprogrammes PCL1019 (mit der Angabe AENDERN) erfolgt mit dieser
Option. Voraussetzung an diese Schnittstelle ist, dass bei
Bestandswerten wie durch PCL1019 der Folgemonat wieder rausgebucht
wird.
Umgebucht werden sämtliche Verdichtungsstufenmengen, die mindestens
eine aktive Verdichtungsstufe enthalten, selbstverständlich außer
sequentielle Verdichtungsstufen mit der Art 1, da diese ja nicht
fortgeschrieben werden können. Es werden also auch stillgelegte
Verdichtungsstufen umgebucht, falls sie in einer Menge enthalten sind
mit mindestens einer aktiven Verdichtungsstufe. Die eingespeicherten
Zeiten dürfen sich nur soweit überlappen, dass mindestens ein Monat
jeder Verdichtungsstufe nicht durch andere dieser Menge abgedeckt
wird. Des weiteren ist zu beachten, dass überlappende Zeiten nur in
einer Verdichtungsstufe umgebucht werden. Deshalb sollte man
überlappende Zeiten möglichst vermeiden. Durch das Dienstprogramm
PCL1042 gesplittete Mengen haben keine überlappende Zeiten. Um
Inkonsistenz zu vermeiden, wird überprüft, ob jeder Werteintrag in
jeder Menge bezüglich der eingespeicherten Zeiten umbuchbar ist.
Ansonsten wird der Satz als fehlerhaft abgewiesen.
Die Option UMBUCH impliziert die Optionen NOVSTGENER, VORVERDICHTEN
und INDEX_GEN=0 auch unabhängig von gegenteiligen Angaben in der
Vorlaufkarte. Dagegen führt die Angabe der Option VSTNR zu einer
Fehlermeldung.
Die Umbuchung kann auch stillgelegte Verdichtungsstufen betreffen.
Ergänzung von Schlüsselausprägungen (Option KEYLUECKE)
Wenn das Dienstprogramm PCL1001 neue Schlüsselausprägungen
ergänzt, so wird standardmäßig als interne Nummer der Ausprägung
die größte bisher vergebene Nummer plus eins genommen.
Durch Umbuchungen (zum Beispiel mit PCL1019) können nun
Schlüsselausprägungen auf der Schlüsseldatenbank verbleiben, auf
die es keinen Bezug aus Verdichtungsstufen mehr gibt. Trifft dies
für sehr viele Ausprägungen zu, so können diese mit dem
Dienstprogramm PCL1055 von der Schlüsseldatenbank gelöscht werden.
Die dabei entstehenden Lücken werden jedoch standardmäßig nicht
für neue Ausprägungen wieder benutzt. Diese Lücken kann man
entweder mit dem Dienstprogramm PCL1058 (dabei müssen jedoch
sämtliche betroffenen Verdichtungsstufen neu geladen werden)
schließen oder mittels der Option KEYLUECKE.
Die Option KEYLUECKE impliziert die Option KEYUPDATE. Da jedoch für
jede zu ergänzende Ausprägung sämtliche Ausprägungen zu diesem
Schlüssel nachgelesen werden müssen, werden die Ausprägungen
zunächst wie im Standardfall ergänzt. Erst beim Erreichen der
Obergrenze werden die Lücken abgesucht.
Einspeicherung in Schlüssel mit interner Länge > 2
Schlüssel mit interner Länge > 2 gelten im ASS als Massenschlüssel
mit vielen Ausprägungen. Daher werden in der Regel
die Ausprägungen derartiger Schlüssel im Rahmen der
Einspeicherung nicht intern in Tabellen verwaltet (Platzproblem). Für
das Ermitteln der internen Zählnummer (verdichteter Inhalt) zu
einem Schlüsselinhalt eines Schnittstellensatzes ist daher
jeweils ein Schlüsseldatenbankzugriff erforderlich.
Kann durch das System hinreichend viel Adressraum zur Verfügung
gestellt werden, so kann durch die Angabe von UMSCHLMAX=n
dieses Verhalten verbessert werden. Zu jedem Schlüssel mit
interner Länge > 2, wird soviel Adressraum angefordert, dass
n Ausprägungen darin Platz finden. Das Verfahren wird jedoch
nur für die Schlüssel angewandt, deren Ausprägungsanzahl
höchstens 4 mal so groß ist wie das angegebene n. Hierdurch
wird erreicht, dass einerseits nicht unnötig allokiert wird,
andererseits jedoch ein Großteil der Datenbankzugriffe vermieden
wird. ACHTUNG: Bei Angabe dieser Option darf das Programm PCL1004
nicht mit der Option OA laufen.
Analog zu UMSCHLMAX können mit der Angabe UMSCHLPLATZ=n die
Zugriffe auf die Schlüsseldatenbank deutlich reduziert werden.
Mit UMSCHLPLATZ wird vorgegeben, wieviel Adressraum (in Bytes)
für Ausprägungstabellen für Schlüssel mit interner Länge > 2
maximal verwendet werden soll.
Die Angabe über Vorlaufkarte ist erforderlich, da i.a. nicht
ermittelbar ist, wieviel Adressraum zur Verfügung steht
(bestimmter Adressraum muss z.B. für Satzpuffer oder den Sort
freigehalten werden). Pro Schlüssel mit interner Länge > 2
wird maximal der Platz für m Ausprägungen benötigt, wobei
m die nächste interne Nummer für die Ausprägungen des
betreffenden Schlüssels ist (es wird die nächste interne
Nummer verwendet, da die Anzahl Ausprägungen nicht bekannt ist).
Alle Ausprägungen, die in den Arbeitsspeicher eingelesen werden,
werden via Arbeitsspeicher umgeschlüsselt, für den Rest wird
auf die Schlüsseldatenbank zugegriffen.
Platzbedarf für eine Schlüsselausprägung:
- 4 Byte für die interne Nummer +
- n Byte für den Schlüsselinhalt (n = externe Länge) +
- 8 Byte für ein Zeitintervall, falls die Zeitprüfung für Schlüsselausprägungen aktiviert wurde (ist i.a. nicht der Fall).
Die Angaben bei UMSCHLPLATZ sollten mindestens im Megabyte-Bereich liegen.
ACHTUNG:
Bei Angabe von UMSCHLPLATZ darf das Programm PCL1004 nicht mit der Option OA laufen.
Die Optionen UMSCHLMAX und UMSCHLPLATZ dürfen nur alternativ verwendet werden.
ASSAU bzw. ASSAU_KOPF
Auf die Schlüsseldatenbank eingefügte Ausprägungen werden auf die Datei ASSAU ausgeben. Die Ausgabe erfolgt semikolonsepariert als Textdatei. Die Einträge bestehen aus folgenden Feldern:
- Datum in der Form JJMMTT, Startdatum von PCL1001
- Arbeitsgebietsnummer, 3-stellig mit führenden Nullen
- Schlüsselnummer, 5-stellig mit führenden Nullen
- Schlüsselbezeichnung, 20 Byte
- Schlüsselinhalt, 32 Byte
- Verdichteter Schlüsselinhalt, 9-stellig mit führenden Nullen
Am Host haben die Sätze die fixe Länge 80, am PC das Format line-sequential. Die Ausgabe ist sortiert. Da die Ausgabe im Textformat erfolgt, werden Bitschlüssel nicht ausgegeben.
Ist die Option ASSAU gesetzt, so werden auf die Schlüsseldatenbank eingefügte Schlüsselausprägungen nicht im Ablaufprotokoll aufgeführt.
Die Option ASSAU_KOPF impliziert die Option ASSAU. Bei ASSAU_KOPF wird zusätzlich ein Kopfsatz (Überschrift) als erster Satz in die Datei ASSAU geschrieben.
Schlüssel via Vorlaufkarte
I.a. muss eine externe Schnittstelle, die in ein bestimmtes Arbeitsgebiet eingespeichert werden soll, alle Schlüssel, die in diesem Arbeitsgebiet gebraucht werden, anliefern. Die angekündigten Werte bestimmen die benötigten Verdichtungsstufen. Alle in diesen Verdichtungsstufen ausgeprägten Schlüssel sind die erforderlichen Schlüssel. Fehlen Schlüssel, so können diese durch Vorlaufkartenangaben ergänzt werden: INHALT (Schlüsselnummer) = 'Schlüsselinhalt' Einem Schlüssel kann hierdurch genau ein (fester) Schlüsselinhalt zugeordnet werden. Die durch INHALT (...) angegebenen Schlüssel ergänzen die externe Schnittstelle. Werden Schlüssel angegeben, die nicht gebraucht werden oder die in der externen Schnittstelle bereits enthalten sind, so werden diese Angaben ignoriert.
Sollen die Inhalte eines Schlüssel der externen Schnittstelle durch einen festen Inhalt überschrieben werden, so wird dies durch INHALT_ERS (Schlüsselnummer) = 'Schlüsselinhalt' ermöglicht. Fehlt der betreffende Schlüssel in der externen Schnittstelle, so wirken die Schlüssel von INHALT_ERS wie die Schlüssel von INHALT.
Es können maximal 90 Schlüssel durch INHALT bzw. INHALT_ERS versorgt werden.
2.1.1 Umschlüsseln mit User-Exit MCL0169
Mit dem User-Exit MCL0169 besteht die Möglichkeit, die Schlüsselinhalte und Zeiten der mit der externen Schnittstelle angelieferten Summensätze zu verändern. Die nötigen Umschlüsselungsanweisungen müssen in der Datei '$ASS/ASSMANI.TXT' (DD-Name, bzw. Link-Name: ASSMANI) stehen und folgender Form entsprechen:
SCHLÜSSEL/RELATION-NUMMER;SCHLÜSSELINHALT_ALT;SCHLÜSSELINHALT_NEU
oder
ZEITRAUM;Zeit_alt;Zeit_neu
Optional kann die Anweisung mit einem Semikolon abgeschlossen werden.
Aktiviert wird der User-Exit MCL0169 per PCL1001-Vorlaufkarte mit der Option 'MCL0169' (aus historischen Gründen ist auch 'MST0169' zulässig).
Beispiel:
Bei der Anlieferung neuer Summensätze soll sich der Schlüsselinhalt von Schlüssel 4897 (Produktname) von PRODUKT1 in PRODUKT2 ändern und PRODUKT76 in PRODUKT13, sowie der Inhalt KUNDE1 von Schlüssel 324 (Kundenname) in KUNDE25:
- 4897;PRODUKT1;PRODUKT2
- 4897;PRODUKT76;PRODUKT13;
- 0324;KUNDE1;KUNDE25
Für die Umschlüsselungsangaben gelten folgende Restriktionen:
- Die Schlüsselnummer kann führende Nullen enthalten, darf aber nicht länger als 5 Ziffern sein; Blanks davor und dahinter sind erlaubt
- Relationen werden mit R bzw. r gekennzeichnet, also zum Beispiel R9890 oder R 9890
- Bei Schlüsselinhalten werden führende Blanks zur Ausprägung gezählt, hintere werden ignoriert
- Alter und neuer Inhalt dürfen jeweils nicht länger als die externe Länge des Schlüssels sein
- Leere Angaben sind in allen drei Feldern unzulässig
- Es dürfen keine doppelten Angaben gemacht werden, d.h. jede Kombination "SCHLÜSSELNUMMER;SCHLÜSSELINHALT_ALT" muss eindeutig sein; dagegen dürfen verschiedene alte Inhalte auf denselben neuen Inhalt abgebildet werden
Jegliche Verletzung der Restriktionen führt zum Programmabbruch. Die Datei muss nicht sortiert sein. Angaben zu Schlüsseln, die nicht in der externen Schnittstelle angeliefert werden, werden ignoriert.
Auf jeden Inhalt wird max. eine Umschlüsselungsangabe angewendet, d.h. die Angaben
- 00130;A ;B
- 00130;B ;C
Eine Umschlüsselungsangabe braucht 2 * n Bytes Speicherplatz, wobei n die externe Länge des entsprechenden Schlüssels ist. Über die Vorlaufkartenoption "MCL0169_PLATZ = n" kann festgelegt werden, wieviel Speicherplatz insgesamt reserviert werden soll (n muss zwischen 100 und 990.000.000 liegen, natürlich unter Berücksichtigung des max. verfügbaren Speichers in MCL0128). Standardmäßig (d.h. ohne explizite Angabe) werden 100.000 Bytes reserviert, d.h. bei im Schnitt 5-stelligen Schlüsseln können ca. 10.000 Angaben gemacht werden. Dabei werden Angaben zu Schlüsseln, die nicht im Arbeitsgebiet enthalten sind, ignoriert, d.h. sie verbrauchen auch keinen Speicherplatz. Im Protokoll wird dann ausgegeben, wieviel Speicher von MCL0169 wirklich genutzt wurde. Reicht der Speicherplatz nicht aus, kommt es zum Programmabbruch.
Die Umschlüsselung erfolgt VOR der Verarbeitung der externen Schnittstelle, d.h. wird ein alter Inhalt in einen neuen Inhalt geändert, der nicht auf der Schlüsseldatenbank existiert, wird dieser neu angelegt, sofern er den formellen Anforderungen entspricht und die Schlüssel-Neuanlage auf der Schlüsseldatenbank eingestellt ist, siehe Handbuch ST06 Kapitel 3.5.2. Die Form der "alten" Inhalte ist hingegen egal (bis auf die Länge, siehe oben).
Es sind maximal 10 Zeitumsetzungen möglich. Die Zeiten werden in der Form JJMM oder JJMMTT erwartet abhänging vom Format der externen Schnittstelle. Die Zeiten werden im Kopfsatz und den Summensätzen angepaßt. Die Umsetzungen müssen entdeutig sein bezüglich der alten Zeit. Es ist zulässing daß mehrere alte Zeiten auf eine neue Zeit umgesetzt werden.
2.2 Verarbeiten der internen Schnittstelle PCL1002
Interne Schnittstellen für komprimierte Verdichtungsstufen werden vom Programm PCL1002 weiterverarbeitet.
Hierbei gibt es unterschiedliche Varianten:
-
Variante:
(Ur-) Laden einer bzw. mehrerer Summendatenbanken. -
Variante:
Alte Summendatenbank(en) auf sequentielle Datei abziehen, mit interner Schnittstelle mischen und wieder auf Summendatenbank(en) speichern. -
Variante:
Interne Schnittstelle direkt in Summendatenbank(en) einarbeiten. -
Variante:
Interne Schnittstelle additiv zu(r) bestehenden Summendatenbank(en) dazuspeichern. -
Variante:
Abgleich von Plandaten.
Welche Variante zum Einsatz kommt, wird über Vorlaufkarte gesteuert. Die Möglichkeiten bei den Vorlaufkarten sind weiter unten beschrieben. Bevor die Varianten im einzelnen beschrieben werden, sollen zunächst noch einige variantenübergreifende Bemerkungen gemacht werden.
Der INPUT von PCL1002 besteht aus einer internen Schnittstelle, den Parameterdatenbanken DST001, DST002, DST003, mitunter aus einem Abzug von Verdichtungsstufen aus Summendatenbanken und bei der Variante 2 ev. auch noch aus "alten" sequentiellen Verdichtungsstufen. Das Verarbeitungsergebnis von PCL1002 besteht aus einem UPDATE der Steuerungsdatenbank DST003, von neuen oder geänderten Summendatenbanken und ev. aus neuen sequentiellen Verdichtungsstufen.
Eine Summendatenbank kann in einer DLI-Umgebung mit HSSR
abgezogen werden. Falls HSSR nicht zur Verfügung steht
oder Summendatenbanken nicht in DLI gespeichert sind, müssen
Summendatenbanken mit dem Programm PCL1024 abgezogen werden
(Beschreibung siehe unten).
Werden Verdichtungsstufen in einem Arbeitsgebiet auf mehrere
Summendatenbanken verteilt und werden in einem Lauf von PCL1002
Verdichtungsstufen aus mehreren Summendatenbanken
fortgeschrieben, so muss der Abzug der "alten" Verdichtungsstufen
mit dem Programm PCL1124 erzeugt werden.
Werden Summendatenbanken vollständig neu erstellt,
so kann man das Laden entweder direkt vom PCL1002 durchführen
lassen oder aber Ladebestände erstellen, die anschließend
vom Programm PCL1013 geladen werden können. Bei großen
Summendatenbanken führt man das Laden besser mit PCL1013
durch, da PCL1013 mit einem reinen Lade-PSB arbeiten kann
und kein Logging anfällt. Lädt man mit PCL1002, so kann auf
das Logging nicht verzichtet werden.
Das Laden mit PCL1013 ist weiter unten beschrieben.
Man kann die UPDATE's, die von PCL1002 auf der Steuerungs-DB durchgeführt werden, auch verzögern, indem man die Datenbankänderungen zunächst auf eine Datei schreiben lässt. Die Änderungen aus dieser Datei können dann mit dem Programm PCL1032 auf die Steuerungsdatenbank gespielt werden. Man kann also im Extremfall PCL1002 so laufen lassen, dass keine Datenbankänderungen durchgeführt werden.
Hinweis für BMP:
Lässt man PCL1002 als BMP laufen, so kann man nicht die
PROCOPT=LS benutzen.
Hinweis für Siemens:
Werden Summendaten während des ONLINE-Betriebes eingespeichert,
so sollte das betreffende Arbeitsgebiet vorher gesperrt werden,
damit nicht parallel Auswertungen versucht werden. Das Sperren
verhindert im Prinzip nur technische Fehlermeldungen (z. B.
Fehlermeldungen beim Öffnen einer Datei). Wird mit verteilten
Summendatenbanken gearbeitet, so ist das Sperren jedoch unbedingt
erforderlich, um Überholeffekte Einspeicherung/Auswertung
zu verhindern. Diese Überholeffekte müssen auch bei
BATCH-Auswertungen durch Sperren der betreffenden Arbeitsgebiete
verhindert werden. Es ist darauf zu achten, dass in der JCL des
PCL1002 die Parameterdatenbanken mit SHARUPD=YES, die
Summendatenbanken dagegen mit SHARUPD=NO angegeben werden.
1. Variante:
(Ur-) Laden von Summendatenbanken.
-
Variante 1a.:
Wird in einem Arbeitsgebiet eine interne Schnittstelle zum allerersten mal verarbeitet, so ergeben sich natürlich noch keinerlei Fortschreibungsprobleme. Daher eignet sich diese Variante zum erstmaligen Laden von Daten in die ASS-Bestände. Gibt es in einem Arbeitsgebiet Werte vom Typ BESTAND, so kann nur die Variante 1 zur Urladung (vollständige Bestandsübernahme) herangezogen werden. In diesem Fall ist keine Vorlaufkarte erforderlich. -
Variante 1b.:
Ansonsten kann diese Variante in all den Fällen angewandt werden, in denen die interne Schnittstelle die kompletten Summenbestände enthält. PCL1002 wird dann mit der Option LADEN eingesetzt (betrifft PCL1042, PCL1051 und PCL1058).
2. Variante:
Alte Summendatenbank(en) auf sequentielle Datei abziehen, mit interner Schnittstelle mischen und wieder auf Summendatenbank(en) speichern.
Die 2. Variante ist der Standardfall der Folgeeinspeicherung. Diese Variante muss gewählt werden, wenn aktive Verdichtungsstufen auf seq. Datenträgern existieren oder wenn in der externen Schnittstelle Bestandswerte angeliefert werden. Darüber hinaus empfiehlt sich diese Variante, wenn Summendatenbanken reorganisiert werden sollen und wenn die interne Schnittstelle im Verhältnis zur Summendatenbank nicht als sehr klein anzusehen ist.
3. Variante:
Interne Schnittstelle direkt in Summendatenbank(en) einarbeiten.
Die 3. Variante ist für folgenden Anwendungsfall gedacht:
In einem Arbeitsgebiet gibt es keine Verdichtungsstufen auf
seq. Datenträgern. Die Werte in den Summendaten werden
durch Bewegungen fortgeschrieben. Die Anzahl der Bewegungen,
die auf die Summendaten gespielt werden sollen, ist im
Verhältnis zu den bereits vorhandenen Summendaten klein.
Eine Folgeeinspeicherung entsprechend Variante 2, die
technisch möglich ist, ist für diesen Anwendungsfall
sehr teuer.
In diesem Fall kann man daher die interne Schnittstelle direkt
von PCL1002 in die Summendatenbank(en) einarbeiten lassen, und
zwar durch die Verarbeitungsoption DIREKTSP.
ACHTUNG:
I.a. werden Sätze in der Summendatenbank durch Folgeeinspeicherungen länger. Dies führt z.B. in einer DLI-Umgebung zu SEGMENT-SPLIT's. Man kann eine Reorganisation erreichen, wenn man von Zeit zu Zeit eine Folgeeinspeicherung gemäß Variante 2 durchführt.
4. Variante:
Interne Schnittstelle additiv zu(r) bestehenden Summendatenbank(en) dazuspeichern.
Die 4. Variante funktioniert im Prinzip wie die erste
Variante. Sie setzt nur voraus, dass Summendatenbanken
bzw. seq. Verdichtungsstufen bereits existieren, die
vorhandene Schnittstelle aber nur zusätzliche Summensätze
enthält, die in den Summendaten ergänzt werden sollen.
Bei Einsatz dieser Variante werden die schon in den Datenbanken
vorhandenen Sätze beibehalten. Es findet nur eine
Erweiterung statt.
Die Variante 4 wird durch die Vorlaufkarte VST_ERGAENZ
angefordert. Diese Vorlaufkartenoption ist unten bei den
Vorlaufkarten beschrieben.
5. Variante:
Abgleich von Vorgabewerten (Plandaten) bzw. Erfasswerten
Mit dieser Programmfunktion werden die Vorgabe-/Erfasswerte eines Arbeitsgebietes durch die Vorgabe-/Erfasswerte aus einem Sicherungs-Abzug ersetzt. Der Rest der aktuellen Summendaten bleibt dabei unverändert.
Diese Variante ist für folgendes Problem gedacht:
In einem Arbeitsgebiet sind Vorgabe-/Erfasswerte definiert und auch laufend erfasst worden. Fehler in der Folgeeinspeicherung oder Fehler im Schnittstellenprogramm machen es erforderlich, für einen bestimmten Zeitraum Folgeeinspeicherungen zu wiederholen. Hierzu müssen die Summendaten zeitlich zurückgesetzt werden, etwa auf den 10. eines bestimmten Monats. Vorgabe-/Erfasswerte wurden aber noch am 11. und 12. erfasst. Dies hätte zur Konsequenz, dass die Erfassungsarbeiten vom 11. und 12. verloren wären. Man kann die Vorgabe-/Erfasswerte des 11. und 12. retten, wenn man als allererstes einen Summendaten-Abzug (siehe 2.4) der aktuellen Summendaten macht, danach zurücksetzt und die Wiederholungsläufe durchführt. Zum Schluss werden dann die Vorgabe-/Erfasswerte der anfangs abgezogenen Summendaten mit der Option V_ABGLEICH / E_ABGLEICH unter Angabe eines Arbeitsgebietes wieder auf die reparierten Summendaten gespielt.
ACHTUNG:
Es können nur die Werte und Verdichtungsstufen behandelt werden, die zum Laufzeitpunkt in der Steuerungsdatenbank definiert sind, d.h. wurden am 11. oder 12. neue Vorgabe-/Erfasswerte in der Steuerungsdatenbank definiert, so sind diese Werte verloren.
Der Abzug der Summendaten wird über DBALT eingelesen und die aktuellen Summendaten werden direkt angesprochen.
6. Variante:
Gewöhnlich ist die Übernahme von Bestandswerten mit Anlieferungsart Bestand nur Monat für Monat zulässig. Durch Angabe von NMAXDAT in PCL1001 werden jedoch die zugehörigen Prüfungen deaktiviert. Werden nun bei der Einspeicherung Monate ausgelassen, so wird das zeitliche Gültigkeitsintervall eines Werteinhalts vergrößert.
Beispiel:
Eingespeichert sind zu einer Schlüsselinhaltskombination zum
Zeitaspekt 0103 100 Einheiten (Datum letzte Einspeicherung) und
für 0303 zur gleichen Schlüsselinhaltskombination werden
200 Einheiten angeliefert. In diesem Fall liefert die Auswertung
für 0103 und 0203 (!) als Ergebnis 100 Einheiten.
Durch Angabe der Option BESTANDSUEBERNAHME ändert sich das
Verhalten. Im selben Beispiel würde die Auswertung von 0203
0 Einheiten liefern. Ähnliches gilt, wenn in einem Lauf mehrere
Zeitaspekte eingespeichert werden. Auch hier werden in den
"zeitlichen Lücken" Null-Inhalte erzeugt.
Bemerkung: Die Behandlung von bereits eingespeicherten Sätzen, die in der Schnittstelle nicht angeliefert werden, bleibt unberührt. Diese (Alt-)Bestände werden weiterhin durch Null-Setzung der betreffenden Bestandswerte zeitlich abgeschlossen. Außerdem ist weiterhin die Anlieferung zu einem Monat nur einmal gestattet.
Ablauf ohne Restart:
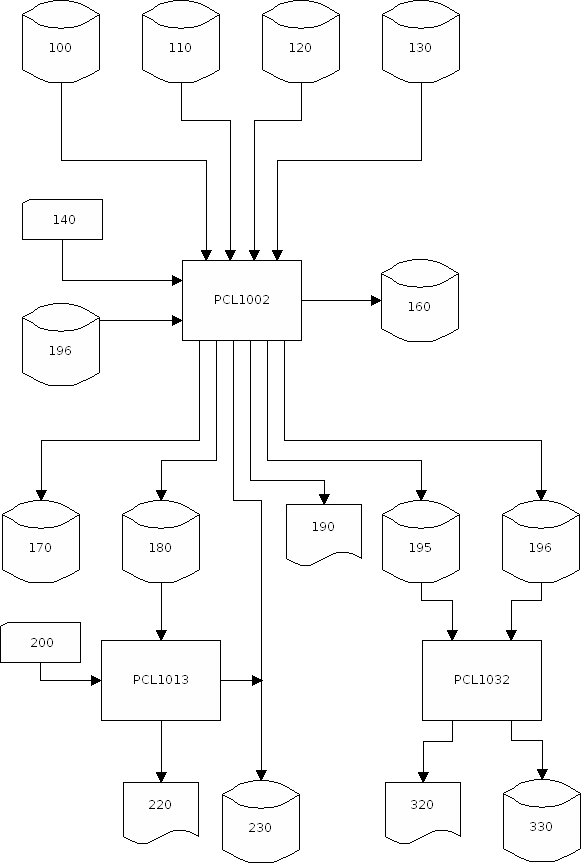
Dateibeschreibung:
| Lfd.-Nr. | DD-Name/PGM LINK-Name |
Dateiname ASS-PC | Beschreibung |
|---|---|---|---|
| 100 | //DBALT | $ASS/AG_SUM.EBC | Abzug der Summendatenbank Aktivieren für Variante 2 und Variante 5 Auf DUMMY setzen für Variante 1, Variante 3 und Variante 4 |
| 110 | //AE | $ASS/AE.DAT | Interne Schnittstelle aus PCL1001 |
| 120 | //DST001 //DST011 //DST012 //DST013 //DST002 //DST021 //DST022 //DST023 //DST003 //DST031 //DST032 //DST033 //DST007 //DST071 |
$ASSDB/DST001 - - - $ASSDB/DST002 - - - $ASSDB/DST003 - - - $ASSDB/DST007 - |
Werte-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Schlüssel-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Steuerungs-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Text-DB Primär-Index (nur DLI) |
| 130 | //ASSCI01 bis //ASSCI50 |
$ASSDB/ASSCVnn | Vortragsbestand der sequentiellen Verdichtungsstufen.
Nur die benötigten Dateien
müssen zugewiesen werden. Die letzten beiden Ziffern bezeichnen den Ort der Verdichtungsstufe. |
| 140 | //VORLAUF | $ASSVLK/T1002.VLK | Vorlaufkarte |
| 160 | - | - | LOGDATEI (nur DLI) |
| 170 | //ASSCO01 bis //ASSCO50 | $ASS/ASSCOnn | Fortschreibung der sequentiellen
Verdichtungsstufen. Nur die benötigten Dateien
müssen zugewiesen werden. Die letzten beiden Ziffern bezeichnen den Ort der Verdichtungsstufe. |
| //AUSnn | $ASS/AUSnn | Ladebestand analog zu //AUS für Summendatenbanken von Verdichtungsstufen, die nicht in der direkt dem Arbeitsgebiet zugeordneten Summendatenbank gespeichert werden (verteilte Summendatenbanken) | |
| 190 | //LISTE | $ASSPTK/PCL1002.PTK | Ablaufprotokoll PCL1002 |
| //ASSINFO | $ASS/ASSINFO.DAT | max. Satzlänge von VST's (falls angef.) | |
| 195 | //ASSUPD | $ASS/ASSUPD.DAT | Verzögerte UPDATE's |
| 196 | //ASSUPI | $ASS/ASSUPI.DAT | Verzögerte UPDATE's von PCL1001 |
| 230 | //DST110 //DST111 bis //DST600 //DST601 |
$ASSDB/DST110 ... | Summen-DB neu (FUER ARBEITSGEBIET 1) Index-DB neu (FUER ARBEITSGEBIET 1, DLI) bis Summen-DB neu (FUER ARBEITSGEBIET 50) Index-DB neu (FUER ARBEITSGEBIET 50, DLI) |
VORLAUFKARTE:
-
IBM:
Feste Satzlänge 80 Bytes ungeblockt, -
SIEMENS:
Variable Sätzlange, mindestens 72 Stellen, hinten mit Blanks auffüllen, maximal 80 Stellen.
Einträge sind ab Spalte 1 vorzunehmen. Mehrere Einträge werden durch Kommata getrennt. Es wird nur die erste Vorlaufkarte interpretiert.
Mögliche Optionen:
| Inhalt | Aktion |
|---|---|
| DATEI | Ausgabe auf Datei(en), UPDATE Steuerungs-DB. Ladebestand für PCL1013 beziehungsweise für das ADABAS-Ladeutility. |
| HSSR | Ausgabe auf Datei(en), UPDATE Steuerungs-DB, wobei
diese Option die Option DATEI impliziert. Ladebestand für DL/I mittels DFSURGL0 oder einem vergleichbarem Produkt. |
| HSSR8 | Diese Option impliziert die Option HSSR. Ladebestand für DL/I ab IMS Version 8, also ohne Kopfsatz und anderem Endesatz. |
| BMC | Diese Option impliziert die Option HSSR. Ladebestand für DL/I mittels BMC Load Plus. |
| DB2 | Diese Option impliziert die Option DATEI. Die Ausgabe erfolgt für das DB2 Load Utility. |
| ADA | Diese Option impliziert die Option DATEI. Die Ausgabe erfolgt wie in der PL/I-Version mit der Option DATEI, aber ohne HSSR, BMC und DB2.
Adabas Load Exit 6 MST0100: PCL1002 mit Option DATEI
PCL1002 mit Option ADA
Adabas Load Exit 6 MCL0100: PCL1002 mit Option DATEI
VSAM Repro: PCL1002 mit Option DATEI
PCL1002 mit Option ADA |
| SONST | Ausgabe auf Datei(en), Update der Steuerungsdatenbank
wenn nicht die Option NUPDAT gesetzt, Prüfungen ausgeschaltet.
Ausgabe auf Datei(en) unter Windows nur bis 4 GB. |
| NOPRUEF | UPDATE der Steuerungs-DB, Prüfungen ausgeschaltet, Ausgabe auf Datei(en) oder Summen-Datenbank(en) in Abhängigkeit von DIREKTSP. Ausgabe auf Datei(en) unter Windows nur bis 4 GB. Diese Option gilt nicht für DIREKTSP. |
| NOPRUEF_DB |
UPDATE der Steuerungs-DB, Versionsprüfungen ausgeschaltet und
Ausgabe auf Summen-Datenbank.
Diese Option gilt nicht für DIREKTSP. |
| NOCELET1 | CELET1 (Datum der letzten Einspeicherung) in SST021CO zunächst nicht fortschreiben, kann mit Kommando FREIGEBEN in der Online-Transaktion ST06 aktiviert werden (vgl. Handbuch Einrichten eines Arbeitsgebietes) |
| DIREKTSP | Interne Schnittstelle direkt in Summen-Datenbank(en) einarbeiten |
| NOKOPFPRUEF | Versionsprüfung ausgeschaltet für DIREKTSP. |
| KORR | Korrekturlauf, ermöglicht es, Bestandswerte, die als Bestand angeliefert werden, zu korrigieren, auch wenn Wertedatum < CELET1 ist. |
| NUPDAT | Änderungen, die normalerweise auf die Steuerungs-DB durchgeführt worden wären, in die Datei ASSUPD stellen, um diese Änderungen mit dem Programm PCL1032 später auf die Steuerungs-DB spielen zu können. |
| VST_ERGAENZ | Dieser Inhalt ist nur im Zusammenhang
mit Reorganisationsmaßnahmen mit
Hilfe des Programms PCL1011 sinnvoll.
Wurden von PCL1011 zusätzliche
Verdichtungsstufen erzeugt, so
enthält die interne Schnittstelle
die neuen Verdichtungsstufen, die von
PCL1002 additiv verarbeitet werden,
d.h. die neuen Verdichtungsstufen
werden in die Summendatenbank(en) dazugeladen
oder auf seq. Datei(en) ausgegeben
(als Input für PCL1013, je nach
Vorlaufkartensteuerung) oder
es entstehen neue sequentielle Verdichtungsstufen.
Die Versionsnummer des betreffenden
Arbeitsgebietes wird in diesem Fall
nicht fortgeschrieben.
Unter Linux/Unix/Windows ist dies nicht empfehlenswert: Es wird die Option DATEI impliziert. Eine Folgeeinspeicherung ist die bessere Wahl, siehe weiter unten. |
| CHKP_PRIVAT | „private“ Checkpoint-Schreibung (siehe weiter unten). |
| V_ABGLEICH = AGNR | Abgleich von Vorgabewerten (Plandaten) unter Angabe der Nummer des Arbeitsgebiets. (siehe weiter unten). |
| E_ABGLEICH = AGNR | Abgleich von Erfasswerten unter Angabe der Nummer des Arbeitsgebiets. (siehe weiter unten). |
| LADEN | Laden der Summendatenbank(en) nach den Dienstprogrammen PCL1042 , PCL1051 und PCL1058 (Variante 1.B) |
| BESTANDSUEBERNAHME | Steuerung der Übernahme von Bestandswerten mit Anlieferungsart Bestand |
| ASSINFO | Ausgabe der maximalen Satzlänge von Verdichtungsstufen auf die Datei ASSINFO. |
| ASSINFO_CSV | Wie ASSINFO, Felder werden durch Semikolon getrennt. |
| ASSINFO_KOPF | Wie ASSINFO_CSV, mit Kopfsatz (Überschrift). |
| DOPPELT_WERT | Verarbeitung von internen Schnittstellen, die von PCL1011 mit dieser Option erzeugt wurden. |
| DOPPELT_DIR | Verarbeitung von internen Schnittstellen, die von PCL1011 mit dieser Option erzeugt wurden. |
| FB | Verarbeitung von internen Schnittstellen, die im festgeblockten Format vorliegen. Ber Summen-DB-Abzug wird dabei auch im festgeblockten Format erwartet. |
Beispiele:
- NOCELET1
- NUPDAT
- DATEI,NOCELET1
- NOPRUEF
- NOPRUEF,NOCELET1
- SONST
- DIREKTSP
- V_ABGLEICH=44
- E_ABGLEICH=44
Bei aktivem Arbeitscache muss nach erfolgter Einspeicherung das
PCL1046 laufen, da sonst die Auswertung nicht auf die aktualisierten Daten
zugreift.
Wurden bei der Einspeicherung auch Schluesselausprägungen
ergänzt, so muss bei aktiven Schluesselcaches außerdem noch
PCL1089 laufen.
Eine Verdichtungsstufe kann max. 2,14 Mrd. Sätze aufnehmen, bei Überschreiten dieser Grenze bricht PCL1002 ab.
„Private“ Checkpoint-Schreibung (PCL1002)
Checkpoints werden mit dem Programm MCL0699 geschrieben. Checkpoints werden nur dann geschrieben, wenn in der betreffenden Installation MCL0699 dafür ausgelegt ist. Die Checkpoint-Schreibung ist nur bei einem direkten UPDATE der Summendatenbank möglich, also bei gewähltem Parameter 'DIREKTSP' in der Vorlaufkarte. Die Aktivierung erfolgt dann über den weiteren Parameter 'CHKP_PRIVAT' in der Vorlaufkarte. Checkpoints können nach Zugriffen auf die Summendatenbank geschrieben werden.
Unterstützung von BMC Load Plus und Unload Plus für DL/I
Mit der Option BMC wird die Summendatenbank nicht direkt geladen,
sondern ein Ladebestand erzeugt, der mit Load Plus anschließend
geladen werden kann. Der Ladebestand für Load Plus ist identisch
mit dem sogenannten HSSR-Format für das Utility DFSURGL0, außer
dass der erste und letzte Satz fehlt.
Die Option BMC impliziert die Optionen DATEI und HSSR.
Entsprechend kann statt dem Dienstprogramm PCL1024 Unload Plus
benutzt werden. Dabei ist darauf zu achten, dass der Aufbau dem
HSSR-Format entspricht, außer dass der erste und letzte Satz fehlt.
Dieses Manko kann behoben werden, in dem der BMC-Abzug mit je einem
Dummy-Kopf- und Endesatz verkettet wird.
Besonderheiten für Windows/Linux
Neue Verdichtungsstufen können nicht direkt in einem Schritt
auf der Summendatenbank ergänzt werden.
Beim Aktivieren der Option VST_ERGAENZ erzeugt PCL1002 immer
einen Ladebestand auf Datei ($ASS/AG_SUM.UPD bzw.
$ASS/AUSnn).
Die Dateien mit den Ladebeständen enthalten immer nur die
Summensätze der entsprechenden neuen Verdichtungsstufen.
Mit dem Programm PCL1013 (Option VST_ERGAENZ) muessen die
neuen Verdichtungsstufen dann nachträglich auf die
Summendatenbanken gebracht werden.
Verteilen sich die zu ergänzenden Verdichtungsstufen auf
mehrere Summendatenbanken, so erstellt PCL1002 bei den
Optionen DATEI und VST_ERGAENZ unter Umständen mehrere
Dateien.
In der Datei $ASS/AG_SUM.UPD stehen dann die neuen Verdichtungsstufen
für die primäre Summendatenbank. Für jede betroffene sekundäre
Summendatenbank (Dummy-Arbeitsgebiet) stellt PCL1002 die neuen
Verdichtungsstufen in die Dateien $ASS/AUSnn. (nn = Ort der aktiven
Verdichtungsstufe) Diese Dateien müssen vor dem Laden mit PCL1013
immer in $ASS/AG_SUM.UPD umbenannt werden und das jeweilige nn muss
in der Vorlaufkarte von PCL1013 als Arbeitsgebietsnummer erscheinen.
Dabei empfiehlt es sich, zuerst die Datei mit dem Ladebestand für
die primäre Summendatenbank zu verarbeiten. Danach kann man
nacheinander die Ladebestände für die sekundären Summendatenbanken
einspielen. Da PCL1013 immer nur eine Eingabedatei verarbeiten kann,
müssen die Dateien $ASS/AUSnn jeweils in $ASS/AG_SUM.UPD umbenannt
werden.
Enthält das Arbeitsgebiet sequentielle Verdichtungsstufen, so müssen diese unter dem Namen $ASSDB/ASSCVnn im Datenbankverzeichnis $ASSDB zu finden sein.
Genaue Namenskonvention:
| Arbeitsgebietsnummer (=Ort der Verdichtungsstufe) | Name |
|---|---|
| nn = 01,...,99 | ASSCVnn |
| 100 | ASSCV00 |
| nnn = 101-200 | ASSCnnn |
Erfolgt bei der Einspeicherung eine Fortschreibung oder Neuanlage von sequentiellen Verdichtungsstufen, so stehen diese nach Ablauf von PCL1002 im Stammverzeichnis von ASS-PC unter dem Namen $ASS/ASSCOnn (nn wie oben). Erst wenn der Programmlauf von PCL1002 für richtig befunden wurde, sollten die neu erstellten sequentiellen Verdichtungsstufendateien $ASS/ASSCOnn in $ASS/ASSCVnn umbenannt werden (nn muss dabei selbstverständlich erhalten bleiben). Danach muss man die Dateien aus dem Stammverzeichnis $ASS in das Datenbankverzeichnis $ASSDB stellen, wo sie dann für die Auswertung verfügbar sind.
PCL1002 gibt die aktuelle Anzahl der Folgedateien der jeweiligen
Summendatenbank ins Protokoll und in die Datei ASSINFO.DAT aus,
jeweils unter dem Begriff „FILE“. Somit kann leichter kontrolliert
werden, wie nahe man der Obergrenze bereits gekommen ist. In
ASSINFO.DAT steht bei jeder Verdichtungsstufe die nach deren
Verarbeitung aktuelle Anzahl, d.h. die endgültige Anzahl ist die im
letzten Satz.
Die Obergrenze ist mit ASS 8.10 von 20 auf 40 (SST2264) vergrößert
worden.
2.3 Laden von Summendatenbanken PCL1013
Mit PCL1013 werden die von PCL1002 geschriebenen Summendaten (Datei "AUS" bzw. "AUSnn") in die betreffende Summendatenbank geladen. Außerdem können die Berichtsdatenbank, der Anforderungscache, die Pseudonym-DB, die Index-DB, die Log-DB sowie die mit PCL1231 erzeugte User-Exit-DB geladen werden, wenn sie zuvor mit PCL1024 abgezogen wurden.
Dateibeschreibung:
| DD-Name/PGM LINK-Name |
Dateiname ASS-PC | Beschreibung |
|---|---|---|
//DST001 //DST011 //DST012 //DST013 //DST002 //DST021 //DST022 //DST023 //DST003 //DST031 //DST032 //DST033 //DST007 //DST071 |
$ASSDB/DST001 - - - $ASSDB/DST002 - - - $ASSDB/DST003 - - - $ASSDB/DST007 - |
Werte-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Schlüssel-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Steuerungs-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Text-DB Primär-Index (nur DLI) |
| //ASSCO | $ASSVLK/T1013.VLK | Vorlaufkarte |
| //LADE | $ASS/AG_SUM.UPD | Ladebestand |
| //LADEFB | $ASS/AG_SUM.UPD | Ladebestand festgeblockt (Option FB) |
| //LISTE | $ASSPTK/PCL1013.PTK | Ablaufprotokoll PCL1002 |
| //DST110 //DST111 bis //DST600 //DST601 |
$ASSDB/DST110 ... | Summen-DB neu (FUER ARBEITSGEBIET 1) Index-DB neu (FUER ARBEITSGEBIET 1, DLI) bis Summen-DB neu (FUER ARBEITSGEBIET 50) Index-DB neu (FUER ARBEITSGEBIET 50, DLI) |
In der Vorlaufkarte muss angegeben werden, für welche Summendatenbank ein Ladelauf durchgeführt werden soll. Inhalt: AGNR=nn, wobei 01 <= nn <= 500 (bzw. <= Maximalzahl zulässiger Arbeitsgebiete). nn gibt die Nummer der zu ladenden DB an. Diese Nummer ist die jeweilige Arbeitsgebietsnummer, wenn nicht mit verteilten Summen-Datenbanken gearbeitet wird.
-
Beispiel für IBM/MVS:
//ASSCO DD *
AGNR=17 -
Beispiel für SIEMENS/BS2000:
/FILE dateiname,LINK=ASSCO
wobei die Datei mit Dateiname einen Satz mit dem Inhalt AGNR=17 enthält.
PCL1013 kann benutzt werden, wenn eine Summendatenbank vollständig neu geladen wird oder wenn mit VST_ERGAENZ erzeugte Verdichtungsstufen additiv zu einer Summendatenbank dazugeladen werden sollen.
ACHTUNG:
In einer PC-Umgebung (Windows / Unix) muss in dem Fall, wenn kein vollständiger Ladebestand auf der Eingabedatei steht (PCL1002 mit Option VST_ERGAENZ), das Programm PCL1013 ebenfalls mit der Option VST_ERGAENZ gestartet werden, da andernfalls kein additives Laden der Daten erfolgt, die Altdaten auf der Summendatenbank also gelöscht werden.
ACHTUNG:
Bei Folgeeinspeicherungen nach Variante 1 oder 2 ist darauf zu achten, dass die betreffende Summendatenbank vor dem Ladelauf leer ist. Dies kann mit DB-Systemabhängigen Utilities erreicht werden, z.b. DELETE/DEFINE CLUSTER bei DLI.
ACHTUNG bei ADABAS:
ADABAS-Summendatenbanken werden nicht mit PCL1013 geladen, sondern mit dem ADABAS-Utility ADAWAN. Hierbei ist darauf zu achten, dass beim USER-EXIT 6 das ASS-Programm MST0100 angegeben wird. Zuvor muss jedoch MST0100 übersetzt und gelinkt werden.
Vorlaufkarte:
Werden Summensätze geladen, die von einem anderen Betriebssystem
stammen als dem, unter dem PCL1013 läuft, so ist es u. U.
erforderlich, dass der Kopfsatz der Summendaten an einen anderen
Code (Translation) angepasst wird.
Hierfür stehen folgende Optionen bereit:
- BS2000_ANSI : Übersetzen von BS2000-EBCDIC nach ANSI (Unix)
- MVS_ANSI : Übersetzen von MVS-EBCDIC nach ANSI (Unix)
Im Kopfsatz müssen nur Ziffern angepasst werden (i.w. Datumsangaben). Daher ist das Translate-Problem vergleichsweise einfach: BS2000-EBCDIC und MVS-EBCDIC unterscheiden sich bei Ziffern nicht. Gleiches gilt für Windows und Unix.
Mit der Option FB wird festgelegt, dass die Summensätze aus einer Datei mit fester Satzlänge von 80 Byte gelesen werden sollen. Dies ist insbesondere bei Migrationen erforderlich: Summensätze werden am Host mit PCL1124 und der Option FB auf eine Datei mit fester Satzlänge von 80 Byte abgezogen, anschließend folgt ein File-Transfer und dann ein Ladelauf von PCL1013 mit den Optionen FB und z.B. BS2000_ANSI.
FB
Laden von LADEFB bzw. $ASS/AG_SUM.UPD in fester Länge 80 Damit können auch die List-, Anf-Cache-, Textierungs- und Pseudonym-Datenbank geladen werden, jedoch nicht die DSTTXT.
Damit kann auch wie folgtend die Keylänge der Listdatenbank angepaßt werden:
- PCL1024 mit FB
- in Copy SST1482 S1482-KEEXL-MAX-BR ändern und ASS umwandeln
- PCL1013 mit FB
2.4 Abziehen von Summendatenbanken HSSR / PCL1024/ PCL1124
Unter dem Abziehen einer Summendatenbank wird das vollständige sequentielle Lesen dieser Summendatenbank und das Schreiben aller Segmente (Sätze) in eine sequentielle Datei verstanden. Bei DLI-Datenbanken gibt es ein Utility (HSSR), das sehr schnell Datenbanken abziehen kann. Steht HSSR nicht zur Verfügung, können Summendatenbank-Abzüge mit dem Programm PCL1024 oder dem Programm PCL1124 oder dem DLI-Utility DFSURGU0 durchgeführt werden.
Hinweis:
Soll eine Summen-DB aus obigem Abzug mit PCL1013 neu geladen werden, so muss dieser
vorher mit dem Programm PCL1083 ins Ladeformat
transformiert werden.
Ausnahme: PCL1083 darf nicht laufen, wenn der Summen-DB-Abzug in fixer Blocklänge
(VLK-Option FB bzw. FBKO, s.u.) erstellt wurde. Dieser kann dann direkt mit PCL1013 geladen werden (mit VLK-Option FB).
Achtung: Bei den Sonder-Datenbanken (Berichts-DB, Anforderungs-Cache etc., s.u.) wird IMMER in
fixer Blocklänge ausgegeben, d.h. auch hier muss/darf nicht mit PCL1083 umformatiert werden.
Das Programm PCL1124 besitzt im Gegensatz zum Programm PCL1024
mehr Intelligenz und kann dazu benutzt werden, die Summensätze
zu Arbeitsgebieten abzuziehen, die auf mehrere Summendatenbanken
verteilt sind. In diesem Fall muss es auch benutzt werden.
Für die Folgeeinspeicherung empfiehlt es sich, stets PCL1124 statt
PCL1024 zu verwenden.
Summendatenbank-Abzüge werden vom Programm PCL1002 bei den
Varianten 2 und 5 benötigt (siehe 2.2).
Sollen die Summendatenbanken abgezogen werden, welche für die
Berichtsdatenbank, den Anforderungscache, die Pseudonym-DB, die Index-DB, die Log-DB oder die von PCL1231
erzeugte User-Exit-DB reserviert sind, so muss PCL1024
verwendet werden. Der Abzug kann dann mit PCL1013 wieder geladen
werden, z.B. um die Berichtsdatenbank zu reorganisieren.
Hinweis für Siemens:
Werden Summendaten während des ONLINE-Betriebes abgezogen, so sollte das betreffende Arbeitsgebiet vorher gesperrt werden, damit nicht parallel Auswertungen versucht werden. Das Sperren verhindert im Prinzip nur technische Fehlermeldungen (z. B. Fehlermeldungen beim Öffnen einer Datei). Auswertungen anderer Arbeitsgebiete sind möglich. Es ist darauf zu achten, dass in der JCL des PCL1024 die Parameterdatenbanken mit SHARUPD=YES, die Summendatenbanken dagegen mit SHARUPD=NO angegeben werden.
Mehrere Summendatenbanken auf eine Datei abziehen PCL1124
Einem Arbeitsgebiet können mehrere Summendatenbanken zugeordnet
sein. Für jede Verdichtungsstufe mit Art '0' (aktiv) oder '3'
(nicht aktiv) wird die zugehörige Summendatenbank durch den Ort
definiert.
Mit PCL1124 ist es nun möglich, alle Summendatenbanken, die zu
einem Arbeitsgebiet gehören, auf eine Datei abzuziehen.
Dieser Abzug kann ganz analog wie der PCL1024-Abzug weiterverwendet
werden, z.B. zur Folgeeinspeicherung via PCL1002.
Abgezogen werden Verdichtungsstufen und Relationen, die folgende
Kriterien erfüllen:
- Die Art muss '0' oder '3' oder 'J' (Relation) sein.
- Die Anzahl der Sätze (laut AG) muss > 0 sein.
- Falls die Option NUR_AKTIV angegeben wird, muss die Verdichtungsstufe sich auf einer Summendatenbank befinden, die mindestens eine aktive Verdichtungsstufe enthält.
Verdichtungsstufen, die diese Kriterien nicht erfüllen oder gar nicht im Arbeitsgebiet definiert sind, sich aber auf einer Summendatenbank befinden, werden überlesen.
| DD-Name/PGM LINK-Name |
Format | Dateiname ASS-PC | Beschreibung |
|---|---|---|---|
| //ASSCO | FB 80 | $ASSVLK/T1024.VLK $ASSVLK/T1124.VLK | Vorlaufkarte |
| //DST002 | $ASSDB/DST002 | Schlüsseldatenbank | |
| //DST003 | $ASSDB/DST003 | Steuerungsdatenbankdatenbank | |
| //DSTxxx | $ASSDB/DSTxxx | Summendatenbanken, die abgezogen werden sollen | |
| //AUS | VB 10039 | $ASS/AG_SUM.EBC | Summendatenbank-Abzug |
| //AUSFB | FB 80 | $ASS/AG_SUM.EBC | Summendatenbank-Abzug bei VLK-Option FB und FBKO |
| //AUS2 | VB 10039 | $ASS/AG_SUMS.EBC | Summendatenbank-Abzug für die zu auszulagernden sekundären Summendatenbanken(s.u.) |
| //LISTE | FBA 133 | $ASSPTK/PCL1024.PTK $ASSPTK/PCL1124.PTK | Protokoll |
Optionen werden durch Kommata getrennt, Blanks werden überlesen, Semikolon bedeutet das Ende der Eingabe, nach dem Gleichheitszeichen muss eine numerische Eingabe kommen. Nur die ersten 72 Zeichen werden berücksichtigt.
Optionen für PCL1024 und PCL1124:
| Option | Bedeutung |
|---|---|
| AGNR = ... | Nummer des Arbeitsgebiets, dessen Summendatenban(en) abgezogen werden soll(en). Muss angegeben werden und zwischen 1 und CARNR_MAX (definiert im Include SST1127) liegen. |
| NUR_AKTIV | Nur aktive Summendatenbanken werden abgezogen, d.h. Summendatenbanken, die mindestens eine aktive Verdichtungsstufe enthalten. |
| FB | Es wird ein Abzug im festgeblockten Format (Satzlänge 80 Byte) erstellt (Host: DD-Name AUSFB; PC: $ASS/AG_SUM.EBC, wie ohne FB). Bei Berichts-DB etc. wird dies immer getan. |
| FBKO | Wie FB, aber die Daten enthalten zusätzlich einen HSSR-Kopfsatz und ein HSSR-Präfix vor jedem logischen Datensatz. |
| LEER | Es wird ein leerer Abzug erstellt. |
PCL1124 hat außerdem folgende Optionen:
| Option | Bedeutung |
|---|---|
| CHECK |
Zusätzliche Prüfungen bei Summensätzen (s.u.)
Ab ASS 9.00 obsolet, da Standardeinstellung. |
| CHECKW |
Warnungen statt Fehler.
Fehler in Kopf- und Summensätzen werden nur als Warnungen ausgegeben. |
| NO_CHECK | Keine zusätzlichen Prüfungen bei Summensätzen. |
| NUR_CHECK | Es wird keine Ausgabe erzeugt, d.h. es wird die Summen-DB auf Kopf- und Summensatzfehler geprüft. |
PCL1024 kann auch die folgenden Datenbanken abziehen. Dabei wird die Option FB impliziert.
- Berichts-DB (D A 56 AG-LISTDB)
- Anforderungscache-DB (D A 84 AG-ANF-CACHE-DB)
- User-Exit-DB (D A 87 AG-TEXTDB)
- Pseudonym-DB
- bis zu vier Index-DBs (D A 109 INDEX-TEXT-DB)
- bis zu fünf Log-DBs (D A 114 AG-LOGDB)
Beispiel:
AGNR = 13 , NUR_AKTIV
Stillgelegte Verdichtungsstufen verlagern PCL1124
Stillgelegte Verdichtungsstufen, die in der primären Summen datenbank gespeichert sind, belasten u.U. die Folgeeinspeicherung. Sie müssen bei jeder Folgeeinspeicherung (nicht DIREKTSP) abgezogen und wieder neu geladen werden. Befinden sich jedoch stillgelegte Verdichtungsstufen auf einer sekundären Summendatenbank und in der betreffenden Summendatenbank befinden sich nur stillgelegte Verdichtungsstufen, so können Folgeeinspeicherungen ohne Entladen/Laden dieser Verdichtungsstufen durchgeführt werden. Es leuchtet sofort ein, dass hierdurch Einsparungen bei der Folgeeinspeicherung erzielt werden können.
Mit Hilfe von PCL1124 steht ein Verfahren zur Verfügung, um stillgelegte Verdichtungsstufen von der primären Summendatenbank auf sekundäre Summendatenbanken zu verlagern.
In der Vorlaufkarte von PCL1124 wird angegeben, welche
stillgelegten Verdichtungsstufen verlagert werden sollen und
wohin. Es stehen hierfür zwei Möglichkeiten zur Verfügung:
VDST nr1 > ort (Mehrfachangabe)
oder
VDST_STILL > ort (Einzelangabe)
Mit der ersten Methode können eine oder mehrere stillgelegte
Verdichtungsstufen mit den Nummern nr1 auf eine sekundäre
Summendatenbank mit dem Ort ort verschoben werden und mit der
zweiten Methode können sämtliche stillgelegten Verdichtungsstufen
auf eine sekundäre Summendatenbank verschoben werden.
Es können nur Verdichtungsstufen mit mindestens einem Satz von der
primären Summendatenbank auf eine sekundäre Summendatenbank
verschoben werden.
Bei der Mehrfachangabe muss bei allen zu verlagernden
Verdichtungsstufen der gleiche Ort angegeben werden.
PCL1124 erzeugt zwei Abzugsdateien, AUS für die primäre Summendatenbank und AUS2 für die sekundäre Summendatenbank. Die erforderlichen Änderungen der Steuerungsdatenbank (Ort der stillgelegten Verdichtungsstufen anpassen und ev. ein DUMMY-Arbeitsgebiet anlegen) werden zunächst auf die Datei ASSUPD ausgegeben. Sie müssen zum Schluss noch mit PCL1032 auf die Steuerungsdatenbank gespielt werden (verzögerte Update).
Die Abzugsdateien können mit PCL1083 zum Beispiel für PCL1013 (ISAM) oder das DB2-Loadutility konvertiert werden. Anschließend werden die einzelnen Summendatenbanken geladen. Damit haben PCL1124 und PCL1083 nur lesenden Zugriff und das Arbeitsgebiet muss nur für PCL1032 und das Laden der einzelnen Summendatenbanken gesperrt werden.
Vereinfachter Ablaufplan:

Beispiel:
- AGNR = 13
- VDST 31 > 122
- VDST 32 > 122
Die beiden Verdichtungsstufen 31 und 32 des Arbeitsgebiets 13 sollen auf den Ort 122 (sekundäre Summendatenbank) ausgelagert werden.
CHECK
Mit der Vorlaufkartenoption „CHECK“ werden bei einem Abzug die Summendaten zusätzlich auf Konsistenz geprüft, u.a.:
- Datenbank-Keys (d.h. Schlüsselinhalte) der Summensätze sind aufsteigend
- Werte-/Zeitraum-Paare innerhalb eines Satzes aufsteigend
- Tag darf nur bei Tagesarbeitsgebieten gesetzt sein
Tritt hier ein Fehler auf, bricht das Programm ab.
2.5 Verzögerter UPDATE der Steuerungs- und Parameterdatenbanken PCL1032
Wie bereits erwähnt, kann man PCL1001, PCL1002 oder PCL1011 so laufen lassen, dass keine DB-Änderungen durchgeführt werden. Die erforderlichen Änderungen in der Steuerungs-DB werden dann nicht direkt auf die Steuerungs-DB geschrieben, sondern in die Datei ASSUPD. Die Änderungsanweisungen aus der Datei ASSUPD müssen dann zeitlich verzögert mit dem Programm PCL1032 nachgetragen werden. Die Änderungsanweisungen bestehen hauptsächlich aus der Änderung der Versionsnummer der Summendatenbank und der Anzahl der Sätze pro Verdichtungsstufe (Eintrag auf der Steuerungsdatenbank).
Unter Windows/Linux erstellen die Programme PCL1001, PCL1002 und PCL1011
die Datei fuer die Updates alle unter dem gleichen Namen:
$ASS/ASSUPD.DAT.
Laufen die genannten Programme hintereinander ab, z.B.
PCL1001 (Option NUPDAT) gefolgt von PCL1002 (Option NUPDAT),
so muss zwischendurch immer PCL1032 laufen, da sonst das
Nachfolgeprogramm die Updatedatei $ASS/ASSUPD.DAT
ueberschreibt.
PCL1032 kennt auch noch eine Vorlaufkartendatei. LINK-Name bzw. DD-Name ist ASSCO, bei Windows bzw. Unix wird der Name aus '$ASSVLK/T1032.VLK' gebildet. Das Dateiformat ist analog zur Vorlaufkartendatei von PCL1001. Die Vorlaufkartendatei ist nur im Zusammenhang mit dem Protokoll-Arbeitsgebiet sinnvoll (Siehe hierzu HSYSDOK). Sie sollte standardmäßig auf Dummy gesetzt werden.
3 Auswertungen im BATCH / Aufbau der Datei LDAT / PCL1016 (PCL1003)
Auswertungen im BATCH werden von dem Programmen PCL1016 durchgeführt. Bei Adressraumproblemen siehe Handbuch INSTALLATION, Area-Einstellungen für PCL1016.
PCL1016 wertet die Anforderungsdatenbank DST004 aus. PCL1003 führt Anforderungen, die in der ASS-Anforderungssprache erstellt wurden, aus. Das kann aber auch über PCL1016 mit der Option KARTE geschehen, deshalb ist PCL1003 als veraltet anzusehen, und nicht mehr zu empfehlen. Viele der unten angegebenen Optionen stehen nur für PCL1016 zur Verfügung.
Jede Anforderung wird für sich abgearbeitet. Das Abarbeiten einer Anforderung erfolgt in 3 Schritten:
-
Schritt:
Anforderung analysieren und auf programminternes Format bringen. -
Schritt:
Summendatenbanken lesen und Daten für die aktuelle Anforderung auf eine Workdatei schreiben (Workdatei 1), evtl. diese Workdatei sortieren. -
Schritt:
Die im 2. Schritt erstellte Workdatei druckaufbereiten und nach LISTE schreiben. In diesem Schritt werden auch alle Formeln aus der Anforderung abgearbeitet. Soll die Anforderung sortiert werden, wird eine Workdatei 2 erstellt, die dann sortiert und druckaufbereitet wird.
Arbeitet man mit Umrechnungswerten, so wird im 2. Schritt zusätzlich eine weitere Workdatei ( Workdatei 3 ) für die Umrechnungswerte erstellt. Sie wird nur benutzt, wenn Umrechnungswerte vorkommen.
Werden Anforderungen abgearbeitet, die bei Werte-Formel GESAMT-Operanden enthalten, so kann es passieren, dass bei großen Anforderungen nicht alle GESAMT-Werte im Arbeitsspeicher vorgehalten werden können. In diesem Fall werden Arbeitsdateien WORK10 und WORK11 benutzt. Sie sollten analog WORK1 stets in der JCL zugewiesen werden.
Auf den folgenden Seiten sind die Datenflusspläne der Auswertung dargestellt. Die BATCH-Auswertung kann hinsichtlich Rechenzeit, Zugriffszahlen, Listgrößen etc. durch Vorlaufkarten beeinflusst werden. Dies ist im Anschluss an die Ablaufpläne beschrieben.
Ablauf:
Dateibeschreibung:
| Lfd.-Nr. | DD-Name/PGM LINK-Name |
Dateiname ASS-PC | Bezeichnung |
|---|---|---|---|
| 100 | DUPV1 | - | Anlegen temporäre Workdatei 1 (im BS2000 nur ein FILE-Kommando) |
| 112 | DUPV2 | - | Anlegen temporäre Workdatei 2 (im BS2000 nur ein FILE-Kommando) |
| 110 | //WORK1 //WORK1 //WORK2 //WORK2 |
$ASSWK/WORKnn |
Temporäre Workdatei 1 (Ausgabe)
-"- 1 (Eingabe)
IBM: RecFm=VB, LRecl=6006
SNI: mindestens Standardblockung 3
Temporäre Workdatei 2 (Ausgabe)
-"- 2 (Eingabe)
IBM: RecFm=VB, LRecl=6006
SNI: mindestens Standardblockung 3 |
| 114 | DUPV3/4/5 | - | Anlegen temporäre Workdatei 3, 10 ,11 (im BS2000 nur ein FILE-Kommando) |
| 115 | //WORK3 //WORK3 //WORK10 //WORK10 //WORK11 //WORK11 |
$ASSWK/WORKnn |
Temporäre Workdatei 3 (Ausgabe)
-"- 3 (Eingabe)
Temporäre Workdatei 10 (Ausgabe)
-"- 10 (Eingabe)
Temporäre Workdatei 11 (Ausgabe)
-"- 11 (Eingabe)
IBM: RecFm=VB, LRecl=6006
SNI: mindestens Standardblockung 3 |
| 120 | //DST001 //DST011 //DST012 //DST013 //DST002 //DST021 //DST003 //DST031 //DST032 //DST033 //DST004 //DST041 |
$ASSDB/DST001 - - - $ASSDB/DST002 - $ASSDB/DST003 - - - $ASSDB/DST004 - |
Werte-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Schlüssel-DB Primär-Index (nur DLI) Steuerungs-DB Primär-Index (nur DLI) Sekundär-Index 1 (nur DLI) Sekundär-Index 2 (nur DLI) Anforderungs-DB Primär-Index (nur DLI) |
| 130 | //DST110 //DST111 bis //DST610 //DST611 usw. |
$ASSDB/DST110 ... | Summen-DB (Für Arbeitsgebiet 1)
Index-DB (Für Arbeitsgebiet 1, nur DLI)
bis
Summen-DB (Für Arbeitsgebiet 50)
Index-DB (Für Arbeitsgebiet 50, nur DLI) |
| 140 | //ASSCV01
bis
//ASSCV50 |
$ASSDB/ASSCVnn | Externe Verdichtungsstufen. Nur die
benötigten Dateien müssen zugewiesen
werden. Die letzten beiden Ziffern bezeichnen den Ort der Verdichtungsstufe. |
| 145 | //DST009 oder //DST009 //DST091 oder //DST600 oder entsprechende ADABAS-Files | $ASSDB/DST009 | Security-Datenbank |
| 150 | //KARTEI | $ASSVLK/KARTEI.VLK | In ASS-Anforderungssprache formulierte Listanforderung (Option KARTE) |
| - | //KARTE | $ASSVLK/KARTE.VLK | In ASS-Anforderungssprache formulierte Listanforderung (PCL1003), in PCL1016 Workdatei) |
| - | //KARTEO | $ASSVLK/KARTEO.VLK | Workdatei |
| 151 | //ASSCO | $ASSVLK/T1016.VLK(T1003.VLK) | Vorlaufkarte |
| 152 | //ASSDATE | $ASSVLK/ASSDATE.VLK | Bezugsmonat und Anforderungsvariable |
| - | //ASSALIA | $ASS/ASSALIA | Anforderungen, die nicht ausgeführt werden sollen |
| //ASSCO | $ASSVLK/T1016.VLK | Vorlaufkarte | |
| 170 |
//SORTWK01
bis
//SORTWKnn
//SORTWK1
bis
//SORTWKn |
$ASSWK/SORTNN |
Sortwork-Bereich01 -
bis > IBM
Sortwork-Bereichnn -
Sortwork-Bereich1 -
bis > SIEMENS
Sortwork-Bereichn - |
| 180 |
//LISTE
//LISTE01
.
.
.
//LISTE10 |
$ASSPTK/LISTE.PTK $ASSPTK/LISTEnn.PTK | Auswertung auf Liste |
| 190 | $ASS/LDAT | //LDAT | Auswertung auf eine seq. Datei, auf DUMMY Setzen und auf Anforderung aktivieren. |
| 200 | //ASSALI | $ASS/ASSALI | Mit 'NUPDAT' ausgeführte Listanford., die Markierung der Listanforderung als ausgeführt kann über das Dienstprogramm PCL1012 nachgeholt werden. feste Satzlänge von 80 |
| 205 | //ASSVT | $ASS/MAILFB.EBC | Anforderungsergebnis für E-Mail-Versand aus sequentiele Datei, auf Dummy Setzen und bei Bedarf aktivieren |
| 210 | //PWORK | $ASS/PWORK | Ausgabe der Statistiksätze (Protokoll der Anforderung, installationsabhängig, s.u.) |
| 220 | //LISTDB | $ASS/LISTDB | Ausgabe der Datei für die Berichts-DB |
Die Datei ASSDATE
Format: (siehe Include SST1122)
- IBM: Feste Satzlänge 80 Byte.
- SIEMENS: Variable Satzlänge 80 Byte.
Die Beschreibung ist im Auswertungshandbuch unter dem Kapitel "Übersteuerungsmöglichkeiten in der Batchauswertung" enthalten. In dieser Datei muss der erste Satz linksbündig den gewünschten Bezugsmonat in der Form JJMM oder JJMMTT enthalten.
Vorlaufkarten der BATCH-Auswertung:
Vorlaufkarten werden über ASSCO eingelesen. Format:
- IBM: Feste Satzlänge 80 Byte.
- SIEMENS: Variable Satzlänge 80 Byte.
Die Eintragungen in der Vorlaufkarte sind optional. ASSCO kann auf DUMMY gesetzt werden.
Die 1. Vorlaufkarte:
Die 1. Vorlaufkarte spielt eine Sonderrolle. Sie ist für die unten aufgeführten Optionen reserviert und kann auch leer sein.
| Inhalt | Bedeutung |
|---|---|
| MINUTEN=nnn | Begrenzung der Programmlaufzeit in Minuten je Anforderung |
| ZEILEN=mmm | Begrenzung der Listgröße |
| DRLIM=nnn | Begrenzung des Druckoutputs |
| ZUGRIFFE=ooo | Begrenzung der Anzahl Zugriffe zu Summendatenbanken |
| ANFORDERUNGEN=ppp | Begrenzung der Anzahl auszuführender Anforderungen |
| ENDE=hhmm | Begrenzung der Programmlaufzeit durch einen festen Endezeitpunkt |
| NUPDAT | Ausgeführte Anforderungen nicht markieren |
| NUPDATPR | Ausgeführte Anforderungen nicht markieren |
| NPRT | Von Anforderungen unabhängiges Protokoll unterdrücken |
| ANALYSE |
Anforderungen nur überprüfen, nicht ausführen
Ausführungsdatums wird berücksichtigt nur PCL1016 |
| ANALYSE_O_DAT |
Anforderungen nur überprüfen, nicht ausführen
Ausführungsdatums wird nicht berücksichtigt nur PCL1016 |
| FEHLER_ANALYSE | Anforderungen nur überprüfen, nicht ausführen |
| BIB=n | Selektion von Anforderungen, die ausgeführt werden sollen |
| NULLEN | Bei nicht berechenbaren Formeln wird in die PC-Datei 0 ausgegeben |
| KARTE | Anforderung(en) werden von KARTEI gelesen anstatt von der Anforderungsdatenbank |
| LOESCHEN | einmalig auszuführende Anforderungen werden unabhängig vom Ausführungsdatum durch PCL1016-Lauf gelöscht |
| NODEL | es werden keine Anforderungen gelöscht. |
| IGNORE_ANF | Das PC-Format wird standardmäßig über die optionale PC-Anweisung der Anforderung und falls diese nicht existiert über die Bibliothek G, H, I oder J bestimmt. Mittels IGNORE_ANF wird die optionale PC-Anweisung ignoriert. |
| NO_ASSDS | Beim Erzeugen von PC-Dateien wird grundsätzlich keine Beschreibungsdatei ASSDS erzeugt. |
| EHB | Erzeugen Ladeformat für PCL1095 (Berichtsdatenbank) für die Anzeige von Berichten unter ASS-Excel und ASS-Internet. |
| PROFIL, BENUTZER | Vorgeben, mit welchem Berechtigungsprofil und/oder ASS-Benutzer die Anforderungen ausgeführt werden sollen. |
| Ausgabe in sequentielle Datei für Folgeverarbeitung für die Versendung via E-Mail. Es werden nur Anforderungen ausgeführt, die einen entsprechenden Verteiler haben. Es kann zusätzlich maximal eins der Ausgabeformate HTML, HTML_HOCH, HTML_QUER, PDF_HOCH oder PDF_QUER angegeben werden. Voreingestellt ist das normale Listenformat. | |
| EMAIL_PLUS | Anforderungen mit Verteiler werden wie bei EMAIL behandelt. Anforderungen ohne Verteiler werden wie bei einem "normalen" Lauf von PCL1016 ausgeführt. |
| HTML | Ausgabe des Anforderungsergebnis im HTML-Format, wie eine Auswertung in ASS-Internet |
| HTML_HOCH | Ausgabe des Anforderungsergebnis im HTML-Format, wie die HTML-Druckausgabe in ASS-Internet (Hochformat) |
| HTML_QUER | analog zu HTML_HOCH, aber im Querformat |
| PDF_HOCH | Ausgabe des Anforderungsergebnis im PDF-Format. Hierbei werden die einzelnen Seiten für das Drucken im Hochformat vorbereitet. |
| PDF_QUER | analog zu PDF_HOCH, allerdings werden hier die einzelnen Seiten für das Drucken im Querformat vorbereitet. |
| PDF_OHNE_KUERZEN | Werden bei einer Anforderung für die PDF- (und HTML-) Ausgabe die Spaltenbreiten fix aus dem Bereicheblatt übernommen (Option "Zeilenhöhen/Spaltenbreiten übernehmen" unter Zusätze => HTML), so werden (außer den Werten) alle zu langen Tabelleninhalte abgeschnitten. Durch die VLK-Option "PDF_OHNE_KUERZEN" unterbleibt dies. Es kann dabei dann allerdings zu Überlagerungen von Tabelleninhalten kommen. |
| OHNE_ZEITSTEMPEL | Zeitstempel im Dateinamen bei Erzeugung von PDF- oder HTML-Datei entfällt, d.h. der Dateiname besteht nur noch aus Bibliothek und Anforderungsname (z.B. 'B.ANF01.pdf'). Vorsicht: Von einem vorherigen Lauf erzeugte Dateien werden (bei gleicher Bibliothek und Anforderung) ggf. überschrieben. Auch sollten diese nicht z.B. im Acrobat Reader geöffnet sein, da PCL1016 dann diese Datei nicht überschreiben darf und mit Fehler abbricht. |
| PDF_OHNE_SEITENR | Blendet im PDF die standardmäßig in der rechten oberen Ecke angedruckte Seitennummer aus. |
| PDF_RAHMEN | Zieht im PDF einen Rahmen um die Datentabelle, d.h. um den Spaltenüberschriftbereich und die Datenzeilen. |
| PDF_RAHMEN_SE | Wie PDF_Rahmen, nur wird der Rahmen bis zum Seitenende durchgezogen. |
| JOIN_ERG_REL_MAX = ... | Das über die Text-DB-Variable JOIN-ERG-MAX gesteuerte Tuning-Verfahren kann manchmal bei Schlüsselrelationen den gegenteiligen Effekt einer Performance-Verschlechterung haben. Deshalb kann der Text-DB-Wert hier für Relationen übersteuert werden, insbesondere lässt sich das Tuning für Relationen über die Angabe JOIN_ERG_REL_MAX = 0 ganz abstellen. |
| OS2_ANSI | Bei Erzeugung der PC-Schnittstelle oder wird der ANSI-Zeichensatz verwendet statt des Microsoft Konsolenzeichensatzes OEM 858 |
| DATEIERZEUGUNG | LDAT stets erstellen |
| PC_KY_VAR | Bei der Erzeugung der PC-Schnittstelle werden hintere Leerzeichen bei Schlüsselausprägungen entfernt, um ggf. Platz zu sparen. Nur für die Formate EXCEL, EXCELOK und DBASE. |
| NO_GRU_EL_PROT |
Gruppierungen im Protokoll nicht auflösen
nur PCL1016 |
| AREA_TEXTDB=1016nn |
Beispiel:
MINUTEN=10000,ZUGRIFFE=500000,ZEILEN=20000,ENDE=0315
Beschreibung der einzelnen Optionen:
MINUTEN:
Existiert in der 1. Vorlaufkarte die Angabe MINUTEN=nnn, so bewirkt dies eine Einschränkung der Programmlaufzeit. Nach der Prüfung der Anforderung wird ermittelt, wieviel Zeit die Abarbeitung der Anforderung voraussichtlich braucht. Zum anderen wird errechnet, wieviel Zeit noch zur Verfügung steht (Restlaufzeit = vorgegebene Zeit - verbrauchte Zeit). Reicht die Restlaufzeit aus, so wird die Anforderung ausgeführt. Andernfalls wird mit der nächsten Anforderung weitergemacht. Wichtig: die Laufzeit wird je Anforderung neu berechnet.
ZEILEN:
Durch diesen Parameter kann der Druckoutput, der pro Anforderung entstehen kann, begrenzt werden. Jede Anforderung hat eine theoretische Höchstzeilenzahl. Diese Zeilenzahl errechnet sich aus dem Produkt der Anzahl Ausprägungen über alle Kopf- und Zeilenschlüssel.
Beispiel:
Folgende Anforderung sei gegeben:
| KS: | ZEITRAUM=(0187,0287,0387); /* 3 Ausprägungen */ |
| ZS: | GESCHLECHT=(M,W), /* 2 Ausprägungen */ |
| TARIF; /* der TARIF habe 100 Ausprägungen */ |
Dies ergibt 3 * 2 * 100 = 600 Zeilen.
Gegen die so errechnete Zeilenzahl wird geprüft. Übersteigt diese Zeilenzahl das vorgegebene Limit, so wird die aktuelle Anforderung nicht ausgeführt. Es wird mit der nächsten Anforderung weitergemacht.
DRLIM:
Durch diesen Parameter kann der Druckoutput, der pro Anforderung entstehen kann, begrenzt werden. Während bei ZEILEN eine Schätzung durchgeführt wird und die Anforderung ev. überhaupt nicht ausgeführt wird, wird bei DRLIM gezählt, wie viele Druckzeilen pro Anforderung tatsächlich geschrieben werden. Wird der Grenzwert, der bei DRLIM angegeben ist, überschritten, dann wird in der betreffenden Liste am Ende ein entsprechender Hinweis geschrieben und kein weiterer Druckoutput für diese Anforderung erzeugt. Die betreffende Anforderung gilt als korrekt ausgeführt.
ZUGRIFFE:
Durch diese Angabe kann die Anzahl der Zugriffe zu Summendatenbanken limitiert werden, die für die Abarbeitung einer Anforderung maximal zulässig ist. Übersteigt die Anzahl das vorgegebene Limit, so wird die aktuelle Anforderung nicht ausgeführt. Es wird mit der nächsten Anforderung weitergemacht.
ANFORDERUNDEN:
Durch diese Angabe kann man die Anzahl der Anforderungen, die in einem Lauf ausgeführt werden, begrenzen. Gezählt werden nur die erfolgreich ausgeführten Anforderungen.
NUPDAT:
Normalerweise werden die Anforderungen, die von PCL1016 erfolgreich ausgeführt wurden, in der Anforderungsdatenbank als ausgeführt markiert. Dies hat zur Folge, dass PCL1016 nicht mehr ein rein lesendes Programm ist. Läuft PCL1016 beispielsweise nachts im operatorlosen Betrieb, und man möchte, dass PCL1016 nur liest, so kann das durch die Angabe NUPDAT erreicht werden. Die erforderlichen Änderungen werden dann in die Datei ASSALI geschrieben. Diese Änderungsanweisungen können dann zeitversetzt mit PCL1012 nachgetragen werden.
NUPDATPR:
Die Option entspricht im wesentlichen der Option NUPDAT. Alle Sätze der Datei ASSALIA werden nach ASSALI kopiert. Bevor eine Anforderung ausgeführt wird, wird geprüft, ob sie in der Datei ASSALIA enthalten ist. Hierdurch kann erreicht werden, dass das Programm PCL1016 mehrfach hintereinander ohne UPDATE ausgeführt werden kann, ohne dass eine Anforderung mehrfach ausgeführt wird. Z.B. im 1. Lauf entsteht eine Datei ASSALI, die im 2. Lauf als ASSALIA benutzt wird. ASSALI des 2. Laufs wird als ASSALIA des 3. Laufs benutzt usw.
Da durch diese Methode ASSALI immer größer wird, sollte einmal täglich ASSALI mit PCL1012 in die Anforderungs-DB eingearbeitet werden. Hierbei wird ASSALI geleert. Elegant lässt sich die obige Situation mit GDG-Dateien lösen. Eine allerste Datei ASSALI erhält man, wenn man PCL1016 mit der Option NUPDAT ausführt.
NPRT:
Die Option bewirkt, dass die erste und letzte Seite des Protokolls unterdrückt wird. Wurden in einem Programmlauf keine Anforderungen bearbeitet, so entsteht somit kein Output mehr.
ANALYSE:
Die Option bewirkt, dass die Anforderungen nicht vollständig ausgeführt werden. Die Anforderungen werden auf Syntax und Semantik überprüft und außerdem das Zugriffsverhalten auf die Summendatenbank und die Bearbeitungszeit ermittelt. Es wird auch das entsprechende Protokoll erstellt. Nicht ausgeführt werden die Zugriffe auf die Summendatenbank und es unterbleibt eine Aufbereitung der Liste. Mehrfachanforderungen, Join-Anforderungen und verkettete Anforderungen werden nicht analysiert. Es werden nur Anforderungen analysiert, die bezüglich des Ausführungsdatum (einmalig und periodisch) auch ausführbar wären. ANALYSE_O_DAT ignoriert das Ausführungsdatum.
ANALYSE_O_DAT:
Diese Option entspricht der Option ANALYSE, außer daß das Ausführungsdatum ignoriert wird.
FEHLER_ANALYSE:
Wie die Option ANALYSE, es werden jedoch nur die Anforderungen protokolliert, bei denen ein Fehler entdeckt wurde.
ENDE:
Existiert in der Vorlaufkarte die Eingabe der Form ENDE=hhmm, so bewirkt dies eine Einschränkung der Programmlaufzeit. (hh = Stunden, mm = Minuten ) Mit der Option ENDE kann ein Zeitpunkt angegeben werden, über den das Programm nicht mehr mit der Abarbeitung von Anforderungen fortfahren soll. Der Endezeitpunkt errechnet sich aus dem aktuellen Tagesdatum und der über die mit der Vorlaufkarte angegebenen Zeit wie folgt:
- Liegt die Startzeit des Programms nach der Endezeit der Vorlaufkarte, bezieht sich die Endezeit auf den nachfolgenden Tag.
- Ansonsten wird das Endedatum gleich dem Tagesdatum gesetzt.
Den Vorteil dieser Regelung erläutert folgendes Beispiel:
Das Programm PCL1016 soll über Nacht laufen und wird am 30.06.14 um 22.00 Uhr mit der Vorlaufkarte ANFORDERUNGEN=100,ENDE=0230 gestartet. Das Programm darf also maximal bis zum 01.07.14 um 02.30 Uhr laufen. Wäre das Endedatum nicht vom 30. Juni auf den 01. Juli einen Tag weiter geschaltet worden, hätte das Programm überhaupt keine Anforderungen verarbeitet.
Es bestehen folgende Unterschiede zur Option MINUTEN:
- Das Kriterium, wann keine Anforderungen mehr ausgeführt werden, ist unabhängig von der Laufzeit der jeweiligen Anforderung.
- Ist das Endekriterium erfüllt, wird nicht mit der nächsten Anforderung fortgefahren, sondern das gesamte Programm mit entsprechender Fehlermeldung abgebrochen.
Die Abbruchgenauigkeit liegt bei etwa 5 Minuten.
Standardeinstellungen:
- MINUTEN=10000 für PCL1003
- MINUTEN=300 für PCL1016
- Keine Begrenzung bei ZEILEN
- Keine Begrenzung bei ZUGRIFFE
- Keine Begrenzung bei ENDE
- ANFORDERUNGEN=100
- Nicht NUPDAT
- Nicht ANALYSE
BIB=E / BIB=P / BIB=G / BIB=H / BIB=I / BIB=J / BIB=B:
Anforderungen, die ausgeführt werden sollen, können nach dem Bibliothekstyp selektiert werden. BIB=E bedeutet, dass einmalig auszuführende Anforderungen ausgeführt werden. BIB=P bedeutet, dass periodisch auszuführende Anforderungen ausgeführt werden. Diese Option ist wahlfrei. Wird diese Option nicht angegeben, werden einmalige und periodische Anforderungen ausgeführt.
BIB=G, ... , BIB=J sprechen installationsabhängige Listanforderungsbibliotheken an. Diese Angaben sind nur sinnvoll, wenn die entsprechenen Bibliotheken eingerichtet sind. Siehe auch Handbuch Installation.
BIB=B bedeutet, dass Anforderungen, die nur sichergestellt wurden, bearbeitet wurden. Hier ist zu beachten, dass diese nicht fehlerfrei sein müssen. Außerdem werden keine Updates auf die Anforderungsdatenbank durchgeführt. Diese Angabe sollte nur zu Testzwecken verwendet werden.
NULLEN:
Bei Erstellung von PC-Dateien aus dem PCL1016 heraus, wird bei nicht berechenbaren Formeln 0 (anstatt Blank) in die Datei geschrieben.
KARTE:
Bei Angabe dieser Option werden die auszuführenden Listanforderungen anstatt von der Anforderungsdatenbank von der sequentiellen Datei KARTEI gelesen. Analog zum PCL1003 besteht die Einschränkung, dass keine verketteten oder Join-Anforderungen verarbeitet werden können.
LOESCHEN:
Diese Option bewirkt, dass bereits ausgeführte, einmalig auszuführende Anforderungen im angegebenen Namensintervall unabhängig vom Ausführungsdatum von der Anforderungsdatenbank gelöscht werden.
NODEL:
Diese Option bewirkt, dass bereits ausgeführte, einmalig auszuführende Anforderungen nicht von der Anforderungsdatenbank gelöscht werden, auch wenn dass das Ausführungsdatum lange zurückliegt.
EHB:
Diese Option bewirkt, dass Anforderungsergebnisse und -protokolle
auf eine Ladedatei für PCL1095 ausgegeben werden.
Damit stehen die Anforderungsergebnisse unter ASS-EXCEL
und ASS-Internet in einer Anforderungsbibliothek 'Z'
zur Verfügung.
Bemerkung: gleiches geschieht, wenn bei der Anforderung
die Option LISTDB auf 'B' gesetzt wird.
PROFIL, BENUTZER:
Standardmäßig wird eine Anforderung mit dem Berechtigungsprofil des Erstellers (bzw. letzten ändernden Users) ausgeführt. Bei Auswertungen von KARTE gilt, falls vorhanden, das unter PR angegebene Profil. Dies kann durch die Angabe von PROFIL = ... durch ein beliebiges anderes Berechtigungsprofil für alle ausgeführten Anforderungen übersteuert werden. Auch der ASS-Benutzer kann übersteuert werden, dies wirkt sich aber höchstens auf dokumentarische Ausgaben aus, z.B. den Schlüssel ANFORDERER im AG "Statistik über Statistik".
EMAIL:
Diese Option bewirkt, dass nur Anforderungen ausgeführt
werden, denen ein (E-Mail-)Verteiler zugeordnet wurde.
Das Anforderungsergebnis wird auf eine sequentielle
Datei geschrieben, die auf einem PC (eventuell nach
Filetransfer) via PCL1125 weiterverarbeitet werden kann.
PCL1125 versendet die Anforderungsergebnisse an die
bei der Anforderung unter dem Verteiler zusammengefassten
Empfänger (vergleiche HAUSWERT und HST09).
Das Anforderungsergebnis kann folgende Formate haben
-
Liste:
es wird nur die Liste versendet, keine Protokolle -
PC-DATEI:
gilt für Anforderungen auf einer der Sonderbibliotheken G, H, I, J oder für Anforderungen, bei denen die Option Datei angegeben ist. Im letzteren Fall muss vorab noch das Programm PCL1038 mit der Option EMAIL gestartet werden. -
HTML-Format:
Erzeugen des List-Outputs im HTML-Format
DATEIERZEUGUNG:
Wird diese Option angegeben, so wird zu jeder Anforderung, die ausgeführt werden soll und bei der bei korrekter Ausführung das Anforderungsergebnis in die Datei LDAT geschrieben wird, ein "fehlerhaftes" Ausführungsergebnis in die Datei LDAT geschrieben. Dieses "fehlerhafte" Ausführungsergebnis wird, falls aus der Datei LDAT eine PC-Datei erzeugt wird, in die entsprechene PC-Datei weitergereicht und dort entsprechend gekennzeichnet. Einzelheiten hierzu siehe Handbuch HBETRIE2, 4.3 PCL1038.
Die Option DATEIERZEUGUNG ignoriert LDAT-EMPTY. Es werden auch fehlerhafte und leere Anforderungen auf die LDAT ausgegeben. Fehlerhaft setzt voraus, daß die Anforderung von der Anforderungsdatenbank gelesen wird und eine der Optionen DATEI oder DATEIOP hat. Leer meint die Meldung „*** Die Anforderung ist leer: Es gibt keine darzustellenden Zahlen ***“.
NO_GRU_EL_PROT:
Enthält eine Anforderung Gruppierungen, so werden diese samt Inhalt im Protokoll ausgegeben, ebenso eventuell darin enthaltene Gruppierungen. Das kann mitunter viel Platz im Protokoll einnehmen, wodurch die Übersichtlichkeit leidet. Deshalb können Gruppierungsinhalte im Protokoll durch die Vorlaufkartenoption „NO_GRU_EL_PROT“ unterdrückt werden. Es werden dann nur die explizit in der Anforderung angesprochenen Gruppierungen ausgegeben, nicht deren Inhalte oder darin enthaltene weitere Gruppierungen.
AREA_TEXTDB:
Die Area-Einstellungen für PCL1016 werden
standardmäßig aus Satznummer 42 der Text-DB gelesen.
Für Sonderläufe ist u.U. eine andere Einstellung
günstiger. Diese können unter der bei AREA_TEXTDB
angegebenen Satznummer angegeben werden.
Siehe hierzu auch Handbuch HINSTALL.
Beispiel: AREA_TEXTDB = 101601
Die Angaben bei AREA_TEXTDB überschreiben die
Angaben der Satznummer 42, fehlende Angaben werden aus
Satznummer 42 übernommen.
Vorlaufkarten 2 bis N (N maximal 50):
Diese Vorlaufkarten können Selektionskriterien für Anforderungsnamen enthalten:
Inhalt:
Ab Spalte 1 Name einer Listanforderung oder Intervall von Namen von Listanforderungen, durch Bindestrich getrennt.
Beispiel:
- HUGO
- A - D
Im 1. Beispiel werden alle Anforderungen, deren Name mit HUGO beginnt, ausgeführt. Im 2. Beispiel werden alle Anforderungen, deren Name im Intervall von A bis D liegt, ausgeführt.
Existieren mehr als zwei Vorlaufkarten, so werden zuerst die Anforderungen aus der 2. Vorlaufkarte, dann die Anforderungen aus der 3. Vorlaufkarte usw. ausgeführt. Existiert nur die erste Vorlaufkarte, so werden alle Anforderungen, deren Ausführdatum erreicht ist, ausgeführt.
ACHTUNG:
Die angeforderten Namensmengen der Vorlaufkarten 2 bis N dürfen sich nicht überlappen, da es dann zu einer mehrfachen Ausführung einer Anforderung kommen könnte. Existieren Überlappungen, bricht das Programm PCL1016 mit einer entsprechenden Fehlermeldung ab.
Hinter der Angabe eines Anforderungsintervalls kann ein Verteiler angegeben werden. Diese Angabe wird nur bei Verwendung der Option EMAIL verwendet. Hierdurch werden Verteiler-Angaben, die bei den (Einzel-)Anforderungen u.U. existieren, übersteuert.
Syntax/Beispiel: A - D, VERTEILER: HUGO
Die Verteiler-Angabe wird durch ',' vom Anforderungsintervall abgetrennt und durch das Schlüsselwort VERTEILER: (oder VT:) eingeleitet.
Satzaufbau von LDAT (OPT=DATEI):
DCL LDAT_KARTE CHAR(80);
DCL 01 LDAT_KOPF1 BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* STETS 01 */
05 LFDNR PIC'99', /* STETS 01 */
05 EDATUM CHAR(6), /* ERSTELLUNGSDATUM */
05 UE CHAR(70); /* UEBERSCHRIFT */
DCL 01 LDAT_KOPF2 BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* STETS 01 */
05 LFDNR PIC'99', /* STETS 02 */
05 ANZ_AG PIC'99',
05 CARNR(5) PIC'999', /* ANGEFORDERTE AG'S */
05 BIART CHAR(1), /* ANGEFORDERTE BIBLIOTHEK */
05 BINAME CHAR(8), /* ANGEFORDERTEs ELEMENT */
05 KZ_KEBEZI PIC'(5)9';
DCL 01 LDAT_PARAM BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* STETS 20 */
05 LFDNR PIC'99', /* n AUS &&LDAT_SPn */
05 PARINHALT CHAR(60); /* AKTUELLER PARINHALT */
DCL 01 LDAT_KOPF3 BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* STETS 01 */
05 LFDNR PIC'99', /* 03, 04, ... */
05 ANZ_WENR PIC'99', /* ANZAHL WERTENUMMERN */
/* IM AKTUELLEN SATZ */
05 WERT_EL (2),
10 WENR PIC'(5)9',/* WERTENUMMER */
10 WEEXL PIC'99' ,/* WERTELAENGE */
10 WEKST PIC'9' ,/* KOMMASTELLEN */
10 WEBEZ CHAR(20) ;/* BEZEICHNUNG */
DCL 01 LDAT_KOPF4 BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* STETS 03 */
05 LFDNR PIC'99', /* 01, 02, ... */
05 ANZ_KSZS PIC'99',/*ANZAHL KOPF/ZEILENSCHLUESSEL*/
/*IM AKTUELLEN SATZ */
05 KSZS_EL (2),
10 LTH PIC'99' ,/* FELDLAENGE */
10 BEZ CHAR(20) ,/* BEZEICHNUNG */
05 KSZS_LTH_L (2),
10 LTH_L PIC'999' ;/* BEI LTH = 0: LANGE FELD- */
/* LAENGE (AUS MCL0097) */
DCL 01 LDAT_KOPF5 BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* 3 + X <--> X. SS */
05 LFDNR PIC'99', /* 01, 02, ... */
05 ANZ_SS PIC'99', /* ANZAHL SCHLUESSEL */
/* IM AKTUELLEN SATZ */
05 SS (1),
10 ART PIC'9' ,/* 1 SCHL, 2 WERT, 3 ZEIT */
10 NR PIC'(5)9',/* KENR / WENR */
10 LTH PIC'99' ,/* FELDLAENGE */
10 KST PIC'9' ,/* KOMMASTELLEN */
10 BEZ CHAR(60) ;/* BEZEICHNUNG */
DCL 01 LDAT_SUSATZ1 BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* STETS 02 */
05 LFDNR PIC'99', /* 01, 02, ... */
05 ANZ_KS PIC'99', /* ANZAHL KOPFSCHLUESSEL */
/* IM AKTUELLEN SATZ */
05 ANZ_ZS PIC'99', /* ANZAHL ZEILENSCHLUESSEL*/
/* IM AKTUELLEN SATZ */
05 KSZS (2),
10 ART PIC'9', /* 1: SCHLUESSEL */
/* 2: WERT */
/* 3: ZEITRAUM */
10 NR PIC'99999', /* SCHLUESSELNUMMER ODER*/
/* WERTENUMMER */
10 INHALT CHAR(20); /* KEINH ODER FOBEZ ODER*/
/* ZEITRAUM ODER WEBEZ */
DCL 01 LDAT_SUSATZ1_50 BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* STETS 02, 30, 31 */
05 LFDNR PIC'99', /* 01, 02, ... */
05 ANZ_KS PIC'99', /* ANZAHL KOPFSCHLUESSEL */
/* IM AKTUELLEN SATZ */
05 ANZ_ZS PIC'99', /* ANZAHL ZEILENSCHLUESSEL */
/* IM AKTUELLEN SATZ */
05 ART PIC'9',
05 NR PIC'99999', /* SCHLUESSELNUMMER ODER */
/* WERTENUMMER */
05 INHALT CHAR(50), /* KEINH ODER FOBEZ ODER */
/* ZEITRAUM ODER WEBEZ */
05 LTH_AKT PIC'99'; /* NUR BEI SA 30, 31 */
/* Werden vom USER-EXIT MCL0097 lange Inhalte zurueckgegeben, */
/* so wird der betreffende Inhalt auf mehrere Karten verteilt.*/
/* Die erste Karte enthaelt dann die SA = 30, die Folgekarten */
/* die SA = 31. LTH_AKT drueckt aus, wie lang der Inhalt */
/* in der aktuellen Karte gefuellt ist (LTH_AKT <= 50). */
DCL 01 LDAT_SUSATZ2 BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* STETS 10 */
05 LFDNR PIC'99', /* 01, 02, ... */
05 ANZ_SS PIC'99', /* ANZAHL SPALTEN */
/* IM AKTUELLEN SATZ */
05 SSTAB (4),
10 INHALT PIC'S(15)9';
DCL 01 LDAT_SUSATZ3 BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* STETS 11 */
05 LFDNR PIC'99', /* 01, 02, ... */
05 ANZ_SS PIC'99', /* ANZAHL SPALTEN */
/* IM AKTUELLEN SATZ */
05 SSTAB (4),
10 KST PIC'9', /* KOMMASTELLEN */
10 INHALT PIC'S(15)9';
DCL 01 LDAT_ENDESATZ BASED(ADDR(LDAT_KARTE)),
05 SA PIC'99', /* 98 bzw. 99 */
05 LFDNR PIC'99'; /* STETS 01 */
Erklärungen zu LDAT
Jede Datei beginnt mit zwei bis n Kopfsätzen und endet mit einem Endesatz. Im Endesatz wird gekennzeichnet, ob die betreffende Anforderung korrekt ausgeführt wurde:
-
SA im Endesatz = 99
Anforderung korrekt ausgeführt -
SA im Endesatz = 98
Anforderung fehlerhaft ausgeführt, d.h. die Summen-Daten in der Datei LDAT zu der betreffenden Anforderung fehlen oder sind unvollständig.
Gibt es in der aktuellen Anforderung Parameter mit Namen &&LDAT_SPn = ... , so werden die Parameterinhalte zu diesen Parametern in Sätzen mit SA = 20 und LFDNR = n ausgegeben.
Jede "echte" Listenzeile wird mit Sätzen LDAT_SUSATZ1, LDAT_SUSATZ1_50, LDAT_SUSATZ2 oder LDAT_SUSATZ3 beschrieben.
Sätze vom Typus LDAT_KOPF3 (altes Format, LDAT_ERWEITERT_V640
auf '0'b) und LDAT_KOPF5 beschreiben die Spaltenschlüssel. Hierbei
werden die Aufbereitungsangaben aus der betreffenden Anforderung
übernommen. Bei Nachkommastellenangaben A, B, C, ... wird als
Kommastelle Null ausgegeben.
Werden Werte errechnet und konnte ein bestimmter Wert nicht
korrekt ermittelt werden (z.B. Division durch Null), so enthält
der entsprechende Eintrag in SSTAB Blanks.
Sätze vom Typus LDAT_KOPF4 dienen dazu, Formatbeschreibungen
erstellen zu können. Sie werden in LDAT aufgenommen, wenn im
Include SST1253 der Schalter LDAT_ERWEITERT auf '1'B gesetzt
wurde. Sie werden zwischen die Sätze vom Typ LDAT_KOPF2
und vom Typ LDAT_KOPF3 bzw. LDAT_KOPF5 eingefügt.
Das Karten-Format der Datei LDAT hat zur Konsequenz, dass diese Datei sehr groß werden kann. Via Text-Datenbank kann ein verdichtetes Lesen/Schreiben dieser Datei eingerichtet werden (siehe Hinstall). Um die Daten einzelner Anforderungen trennen zu können, wird am Ende der Daten einer Anforderung ein zusätzlicher Satz '<<<<< ENDE DER ANFORDERUNG >>>>>' eingefügt.
Die Option SPTEXTPC
Wird die Option SPTEXTPC gesetzt, so orientieren sich die Ausgaben auf die Datei LDAT stärker am Listbild. Es soll hierdurch i. w. erreicht werden, dass die aus der Datei LDAT erzeugten PC-Schnittstellen an das Listbild angepasst werden. Dies bedeutet im einzelnen:
- Es werden die Kopf-, Zeilenüberschriften aus dem Listbild übernommen.
- Bei Spaltenüberschriften werden die spaltenorientierten Spaltenüberschriften übernommen. Gibt es keine, so wird eine Spaltenüberschrift generiert.
- Mit &&KSin unterdrückte Kopfschlüssel werden nicht ausgegeben.
- Existieren Spaltensequenzen, so werden nur die Spalten der ersten Sequenz in der entsprechenden Reihenfolge ausgegeben.
Die Option NOSUMPC
Wird die Option NOSUMPC gesetzt, so werden keine Sternzeilen (Summenzeilen) ausgegeben. Bei Join-Anforderungen ist folgende Besonderheit zu beachten: Wird bei einer Einzelanforderung die Ausgabe von Summenzeilen angefordert (durch eine entsprechende Option), so gelten diese Zeilen in der Präsentation nicht als Sternzeilen und werden daher immer ausgegeben.
Satzaufbau von LISTDB (OPT=LISTDB):
DCL LISTDB_SATZ CHAR(5002);
DCL 01 LISTDB_KOPF BASED(ADDR(LISTDB_SATZ)),
05 SL BIN FIXED(15), /* SATZLAENGE */
05 KOPF_KZ CHAR(1), /* KOPFKENNZEICHEN */
/* 'K' FUER KOPFSATZ */
/* ASCI-ZEICHEN SONST */
05 BIBANFNAME CHAR(8), /* ANFORDERUNGSNAME */
05 BIBNR BIN FIXED(15) /* STETS '00' */
UNALIGNED,
05 BIBART CHAR(1), /* BIBLOTHEKSART */
/* 'A':ANFORD.-PROT. */
/* 'L':LISTE */
05 KENR BIN FIXED(15) /* SCHLUESSELNUMMER */
UNALIGNED,
05 KEINH CHAR(26), /* SCHLUESSELINHALT */
05 BIBLFDNR BIN FIXED(31) /* STETS '00' */
05 EDATUM PIC'(6)9', /* ERSTELLDAT. JJMMTT */
05 EZEIT PIC'(6)9', /* ERST.-ZEIT HHMMSS */
05 LDATUM PIC'(6)9', /* STETS '000000' */
05 VDATUM PIC'(6)9', /* STETS '000000' */
05 VZEIT PIC'(6)9', /* STETS '000000' */
05 PRKLASSE BIN FIXED(15) /* PROTOKOLLKLASSE */
UNALIGNED, /* AUS ANFORDERUNG */
05 LIKLASSE BIN FIXED(15) /* LISTKLASSE */
UNALIGNED, /* AUS ANFORDERUNG */
05 VERARBKZ1 CHAR(1), /* VERARBEITUNGSKENN- */
/* ZEICHEN STETS ' ' */
05 KOPIEN BIN FIXED(15) /* ANZAHL KOPIEN */
UNALIGNED, /* STETS '00' */
05 VERARBKZ2 CHAR(1), /* VERARBEITUNGSKENN- */
/* ZEICHEN STETS ' ' */
05 VERARBKZ3 CHAR(1), /* VERARBEITUNGSKENN- */
/* ZEICHEN STETS ' ' */
05 VERARBKZ4 CHAR(1), /* VERARBEITUNGSKENN- */
/* ZEICHEN STETS ' ' */
05 VERARBKZ5 CHAR(1), /* VERARBEITUNGSKENN- */
/* ZEICHEN STETS ' ' */
05 RESERVE CHAR(20); /* RESERVE STETS ' ' */
DCL 01 LISTDB_DATENSATZ BASED(ADDR(LISTDB_SATZ)),
05 SL BIN FIXED(15), /* SATZLAENGE */
05 CTLASA CHAR(1), /* DRUCKSTEUERZEICHEN */
05 DATEN CHAR(5001); /* DATENTEIL */
Erklärungen zu LISTDB Jede Datei ist folgendermaßen organisiert: Zunächst kommt der Kopfsatz für die Anforderung. Die weiteren Sätze sind das Protokoll der Anforderung. Danach kommen die einzelnen Berichte zu der Anforderung, wobei vor jedem Bericht wieder ein Kopfsatz steht.
Log-Datei PCL1016 (nur PC)
Bei Auswertungen am PC mit PCL1016 und PCL1016A werden zu jeder verarbeiteten Anforderung Einträge zu Verarbeitungsbeginn und -ende in die Datei $ASS/ASSAKTUELL.LOG geschrieben. Es handelt sich um semikolonseparierte Sätze mit folgendem Aufbau:
| Feld | Inhalt |
|---|---|
| 1 | Programmname (PCL1016 oder PCL1016A) |
| 2 | zufällige Prozess-ID (Nummer) |
| 3 | Datum (JJJJMMTT) |
| 4 | Uhrzeit (hhmmss + Hundertstel) |
| 5 | Art (J = Join, V = verkettet, M = Mehrfach) |
| 6 | Bibliothek |
| 7 | Anforderungsname |
| 8 | A (Anfang) oder E (Ende) |
Gerade wenn mehrere Anforderungen hintereinander verarbeitet werden, kann es interessant sein, an welcher Stelle sich die Auswertung momentan befindet.
4 Einsatz der Berichtsdatenbank
ASS bietet die Möglichkeit, eine sogenannte
Berichtsdatenbank einzurichten. Sie dient dazu, im Batch
ererstellte Berichte (PCL1016) im Online zu verwalten und
auch anzuzeigen.
Dabei werden die Verwaltungsangaben in der Transaktion
ST31 gesetzt (s. Handbuch AUSWERTUNG, Kap. 3.4) und mit
dem Dienstprogramm PCL1094 im Batch abgearbeitet. Zum
Laden der Berichte dient das Programm PCL1095. Dazu muss
bei der Anforderung die Option LISTDB angegeben werden,
damit die Berichte auf eine ladefähige sequentielle
Datei ausgegeben werden (vgl. Kap. 3).
In der Berichtsdatenbank vorhandene Berichte können im
Online angezeigt werden. Damit können auch umfangreichere
Anforderungen, die Online nicht auswertbar
sind, im Dialog angeschaut werden.
Die Berichtsdatenbank wird auch benötigt, wenn mittels
Empfängern/Empfängerlisten Listpakete erstellt werden
sollen (s. Handbuch PAKETIERTE LISTAUSGABE).
Zum DV-technischen Einrichten der Berichtsdatenbank
siehe Handbuch INSTALLATION, Kap. 1.
4.1 Verwaltung der Berichtsdatenbank PCL1094
Das Dienstprogramm PCL1094 dient dazu, die in der
Transaktion ST31 gesetzten Verarbeitungskennzeichen
abzuarbeiten. Dabei können Berichte gedruckt, auf eine
sequentielle Datei abgezogen und/oder gelöscht werden.
Beim Drucken eines Berichts wird die entsprechende
List-(bzw. Protokoll-)klasse berücksichtigt. Außerdem
können mehrere Kopien gedruckt werden.
Die sequentielle Datei, auf die die Berichte abgezogen
werden, hat ladefähiges Format, d.h. sie kann später
wieder als Eingabedatei für PCL1095 verwendet
werden. In diesem Zusammenhang ist zu beachten, dass
alle Berichte, die in einem Lauf von PCL1094 von der
Berichtsdatenbank abgezogen werden, auf dieselbe sequ.
Datei geschrieben werden.
In einem Lauf von PCL1094 werden alle Berichte von der
Berichtsdatenbank gelöscht, bei denen das Löschkennzeichen
gesetzt wurde oder bei denen das Löschdatum
abgelaufen ist.
Sind bei einem Bericht mehrere Verarbeitungskennzeichen
gesetzt worden, so arbeitet das Programm PCL1094 sie
in der Reihenfolge Drucken, Auslagern, Löschen ab.
Es besteht außerdem noch die Möglichkeit, den Lauf von PCL1094 auf Teile der Berichtsdatenbank einzuschränken, indem man in Vorlaufkarten bis zu 10 Namensintervalle angibt. Während des Programmlaufs werden dann nur die Berichte bearbeitet, deren Name in den vorgebenen Intervallen liegt.
Es besteht weiterhin die Möglichkeit, nach Abarbeitung des Verarbeitungskennzeichens aus der ST31, alle Berichte eines angegebenen Namensintervalls aus der Berichtsdatenbank zu löschen. Hierzu ergänzt man bei der betreffenden Intervallangabe in der Vorlaufkarte ,LOESCHEN. Überlappen sich Intervallangaben aus Vorlaufkartenangaben, so erfolgt eine Löschung nur, wenn bei allen diesen Intervallen ,LOESCHEN angegeben wird.
PCL1094
Beispiele:
- SU - VR
- - AK Vom Anfang bis zu AK......
- ER Alle Berichte, deren Name mit ER beginnt
- VO - ,LOESCHEN Von VO...... bis Ende bearbeiten und löschen
ABLAUF:
| Nr. | DD-Name | Dateiname ASS-PC | Beschreibung |
|---|---|---|---|
| 1 | DSTnnn | $ASSDB/DSTxxx | Berichtsdatenbank |
| 2 | $ASSVLK/T1094.VLK | ASSCO | Vorlaufkarte |
| 3 | $ASS/LISTDB | LISTDB | sequentielle Datei für ausgelagerte Berichte |
| 4 | LISTE LISTE01 ... LISTE10 |
$ASSPTK/LISTE.PTK $ASSPTK/LISTEnn.PTK |
Listklassen |
| 5 | ASSLIST | $ASSPTK/PCL1094.PTK | Protokoll |
PCL1094
Die Option PAKET_LOESCHEN:
Auf die Berichtsdatenbank werden auch Anforderungen und Listen gestellt, die für die paketierte Listausgabe benötigt werden. Durch die Option PAKET_LOESCHEN werden alle diese Listen und Anforderungen gelöscht, wenn sie bereits zu den Listpaketen verarbeitet wurden. Eine Einschränkung auf Namensintervalle ist nicht möglich. Die Option PAKET_LOESCHEN kann nicht zusammen mit anderen Vorlaufkarten verwendet werden. Auch verarbeitet das Programm PCL1094 bei dieser Option nicht die 'normalen' Berichte der Berichtsdatenbank. Es müssen alle Dateizuweisungen wie oben beschrieben in der Jobcontrol erfolgen.
4.2 Laden von Berichten auf die Berichtsdatenbank PCL1095
Mit dem Dienstprogramm PCL1095 können Berichte von einer sequentiellen Datei in die Berichtsdatenbank geladen werden. Diese sequentielle Datei wird vom Auswertungsprogramm PCL1016 (PCL1003) erzeugt, falls in der Anforderung die Option LISTDB angegeben wurde. Auch sequentielle Dateien, die mit PCL1094 ausgelagerte Berichte enthalten, können wieder zurückgeladen werden.
Da unter demselben Namen mehrere Berichte vorhanden sein können, erhalten diese intern verschiedene Bibliotheksnummern. Beim Laden wird die niedrigste Nummer unter dem betreffenden Namen ermittelt und der zusätzliche Bericht mit der um 1 reduzierten Nummer in die Berichtsdatenbank geladen. Falls nicht mehr genug Platz auf der Berichtsdatenbank ist (Nummer nahe 0), so erscheint im Ablaufprotokoll ein Hinweis, der eine Reorganisation der Berichtsdatenbank für Berichte des entsprechenden Namens anrät (s. 4.3).
Optional kann eine Vorlaufkarte angegeben werden mit dem Inhalt ERSETZEN. Existiert in diesem Fall bereits mindestens ein Bericht unter dem Namen, den auch der zu ladende Bericht hat, so wird vor dem Laden des neuen Berichtes zunächst ein alter gelöscht. Gibt es mehrere alte Berichte unter demselben Namen, so wird der mit der kleinsten Nummer (d.h. der jüngste alte) gelöscht.
Wird ein Bericht mittels PCL1095 auf die Berichtsdatenbank geladen, wird dieser automatisch mit einem Löschdatum versehen. Standardmäßig werden hierfür 14 Tage auf das Datum zur Laufzeit addiert. Mit der Option „SP-TAGE = n“ können 1 <= n <= 9998 Tage vorgegeben werden. Mit „SP-TAGE <Berichtname> = n“ kann eine übersteuernde Vorgabe für den Bericht <Berichtname> gemacht werden.
ABLAUF:
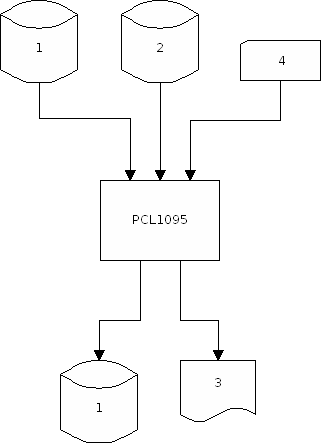
| Nr. | DD-Name | Dateiname ASS-PC | Beschreibung |
|---|---|---|---|
| 1 | DSTnnn | $ASSDB/DSTxxx | Berichtsdatenbank |
| 2 | LISTDB | $ASS/LISTDB | sequentielle Datei mit Ladebestand |
| 3 | ASSLIST | $ASSPTK/PCL1095.PTK | Protokoll |
| 4 | ASSCO | $ASSVLK/T1095.VLK | Vorlaufkarte |
4.3 Reorganisation der Berichtsdatenbank
Von dem Dienstprogramm PCL1095 kann in dem Ablaufprotokoll für Berichte mit einem bestimmten Namen eine Reorganisation angeraten werden. Diese Situation tritt dann auf, wenn für diese Berichte nicht mehr genügend freie (interne) Bibliotheksnummern zur Verfügung stehen. Da diese Nummern beim Laden fortlaufend vergeben werden und ältere Berichte wieder gelöscht werden, gibt es freie Bibliotheksnummern, die jedoch nicht von PCL1095 erkannt werden können.
Durch die angeratene Reorganisation werden diese Lücken wieder geschlossen. Um dies zu erreichen, sind folgende zwei Schritte durchzuführen:
- Schritt: Die betroffenen Berichte müssen alle von der Berichts-DB abgezogen und dort gelöscht werden. (In der Transaktion ST31 die entsprechenden Verarbeitungskennzeichen setzen und anschließend PCL1094 laufen lassen oder direkt mit PCL1094 und der Vorlaufkartenangabe LOESCHEN, s.o.).
- Schritt: Der im ersten Schritt erstellte Abzug mit den Berichten mit dem Programm PCL1095 wieder in die Berichtsdatenbank laden.
5 Dienstprogramme
Die Dienstprogramme erfüllen ein großes Spektrum von Aufgaben. Ihre Behandlung würde den Rahmen dieser Dokumentation sprengen. Das Betreiben der Dienstprogramme wird daher in einem eigenen Handbuch BETRIEB II - Erweiterte Funktionen beschrieben.
6 Listanforderung im DIALOG
Listanforderungen, die ausgeführt werden sollen,
werden in der Datenbank DST004 gespeichert.
Es gibt nun zwei Möglichkeiten, diese in DST004
festgehaltene Anforderung auszuführen.
Der einfachste Weg ist die Ausführung über das
Programm PCL1016, das unmittelbar auf DST004
zugreift.
Daneben besteht die Möglichkeit, die Anforderung
über das Programm PCL1012 auf eine sequentielle
Datei abzuziehen, um sie dann über das Programm
PCL1003 auszuführen.
Dieses Verfahren ist jedoch nicht empfehlenswert,
da PCL1003 nur "einfache" Anforderungen ausführen
kann (keine verketteten Anforderungen, keine
Join-Anforderungen, keine Mehrfach-Anforderungen).
6.1 DLI
Alle erforderlichen Datenbanken (siehe unten) müssen ONLINE zugreifbar sein und die Transaktion ST31 muss gestartet sein.
DST001
DST011
DST012
DST013
DST002
DST021
DST022
DST023
DST003
DST031
DST032
DST033
DST004
DST041
DST005 nicht in CICS-Umgebung
DST007
DST071
DST009
DST091 ,nur falls ASS-Online-Security installiert
worden ist, siehe Handbuch 'Installation',
Kapitel 1.1 und 5.8
|
DST100 DST101 DST110 DST111 . . . DST600 DST601 usw. |
 |
siehe PSB PCL0031 und Handbuch 'Installation', Kap. 3.7 |
6.2 ADABAS
ADABAS muss aktiv sein und die erforderlichen ADABAS-Files müssen im JOB, in dem die Transaktion ST31 abläuft, zugeordnet sein, ST31 muss gestartet sein.
6.3 BS2000-ISAM
Die Isam-Dateien für die Datenbanken
DST001 DST002 DST003 DST004 DST005 DST006 DST007 |
DST110 . . . DST600 usw. |
 |
Summendatenbanken |
Achtung:
DST600 kann auch als Security-Datenbank installiert worden sein und wird dann benötigt, siehe Handbuch 'Installation', Kapitel 1.1 und 5.8
Von den Summendatenbanken müssen nur die tatsächlich benötigten dem entsprechenden UTM-Prozess per FILE-Kommando zugeordnet werden. An dieser Stelle ist achtzugeben, mit wie vielen Prozessen die UTM-Anwendung betrieben wird. Ist die Anzahl der Prozesse größer als 1, so muss mit ISAM SHARUPD=YES gearbeitet werden. Da i.a. jedoch nur wenige Benutzer mit der ST31 arbeiten, sollte überlegt werden, ob nicht ein Prozess ausreicht und auf SHARUPD=YES verzichtet werden kann, da ja SHARUPD=YES auch zusätzliche Betriebsmittel beansprucht.
7 Einrichten ARBEITSGEBIET
Beim Einrichten eines neuen Arbeitsgebietes sind folgende Maßnahmen durchzuführen:
- Schlüssellänge der Summendatenbank des neuen Arbeitsgebietes ermitteln (Summe der internen Längen aller verwendeten Schlüssel plus 2, oder Arbeitsgebiet mit PCL1006 dokumentieren lassen. Schlüssellänge wird dort ermittelt und im Protokoll ausgedruckt).
- Summendatenbank in der erforderlichen Größe
mit der oben ermittelten Schlüssellänge
bereitstellen.
Diese Aktivität richtet sich nach dem
eingesetzen DB-System:
Die ST31 (i.a. PCL0031) und folgende Batch-Programme greifen auf Summen-Datenbanken zu:- PCL1002
- PCL1003
- PCL1007
- PCL1013
- PCL1016
- PCL1019
- PCL1024
- PCL1051
- PCL1055
- PCL1058
- PCL1097
- PCL1124
- PCL1224
- PCL1304
- PCL1333 (ASS-Server, falls installiert)
Je nach DB-Umgebung sind verschiedene Maßnahmen erforderlich (natürlich nur für die Programme, die im Einsatz sind):
DLI : DELETE/DEFINE CLUSTER und DBD's generieren. PSB's anpassen.
ISAM-BS2000 : Entsprechendes File-Kommando
- JOB-CONTROL aktualisieren
7.1 Verteilte Summendatenbanken
ASS bietet die Möglichkeit die Verdichtungsstufen eines
Arbeitsgebiets nicht nur auf verschiedene sequentielle Dateien
abzuspeichern, sondern zusätzlich auch auf mehrere
Summendatenbanken aufzuteilen. Dabei wird zwischen der
primären und den sekundären Summendatenbanken unterschieden.
Die primäre Summendatenbank entspricht der optionalen
bisherigen Summendatenbank.
Verteilte Summendatenbanken bieten sich also bei sehr großen
Datenbeständen an (Limitierung der physischen Größe einer
Datenbank) und für stillgelegte Verdichtungsstufen die für
Auswertungen im Dialog gebraucht werden.
Die verteilten Summendatenbanken sind wie folgt in ASS
realisiert worden. Bei den Summendatenbanken kann entsprechend
den sequentiellen Verdichtungsstufen ein Verdichtungsstufenort
angegeben werden (siehe ST06). Dieser Verdichtungsstufenort
bezeichnet ein Dummy-Arbeitsgebiet, welches dann für ASS
nicht mehr zur Verfügung steht, da dessen Summendatenbank als
sekundäre Summendatenbank genutzt wird. Ist bei einer
direkten Verdichtungsstufe kein gültiger Ort angegeben worden,
so wird standardmäßig die primäre Summendatenbank
angenommen.
Schlüsselrelationen werden auf der primären
Summendatenbank abgespeichert.
In Verbindung mit sequentiellen Verdichtungsstufen gibt es
bezüglich verteilter Summendatenbanken keine Restriktionen.
Bei der Auswertung (ST31 und PCL1016) gibt es für den Endbenutzer keine Besonderheiten, außer dass die sekundären Summendatenbanken den Anwendungen bekannt gemacht werden müssen. Bei der Einspeicherung und diversen Dienstprogrammen, die einen Summendatenbankabzug benötigen, ist zu beachten, dass dieser Abzug sämtliche Summendatenbanken des betreffenden Arbeitsgebietes enthält. Folglich muss bei verteilten Summendatenbanken statt des Dienstprogrammes PCL1024 das Dienstprogramm PCL1124 benutzt werden. Der Einfachheit halber kann aber das Dienstprogramm PCL1024 stets durch PCL1124 ersetzt werden. Bei dem Dienstprogramm PCL1124 ist es möglich, nur die Summendatenbanken abzuziehen, die mindestens eine aktive Verdichtungstufe enthalten. Da das Dienstprogramm PCL1124 wie PCL1024 nur eine sequentielle Abzugsdatei erzeugt, können verschiedene ASS-fremde Utilities wie zum Beispiel DFSURGU0 nicht mehr benutzt werden, falls die Abzugsdatei mehrere Summendatenbanken enthalten sollte. Dagegen werden die Summendatenbanken aber durch die Dienstprogramme PCL1002 und PCL1013 einzeln geladen. Somit kann statt des Dienstprogrammes PCL1013 auch wie gewohnt ein ASS-fremdes Utility wie zum Beispiel DFSURGL0 oder ADACMP/ADALOD eingesetzt werden.
ADABAS:
Bei dem Datenbanksystem ADABAS ist zu beachten, dass nicht mehrere Summendatenbanken auf einem ADABAS-File abgespeichert werden können. Werden in einem Lauf von PCL1002 mehrere Summendatenbanken verändert, so sollte nicht mit DIREKTSP gearbeitet werden. Wird auf eine zweite Summendatenbank zugegriffen, so wird vorher die erste geschlossen. Bricht danach das Programm PCL1002 ab, so können die Änderungen der ersten Summendatenbank nicht mehr zurückgesetzt werden. Im genannten Fall muss also auf eine vorher durchgeführte Sicherung zurückgegriffen werden, bevor das Programm PCL1002 wiederanlaufen kann.
Existieren in einem Arbeitsgebiet stillgelegte Verdichtungsstufen (siehe Verdichtungsstufenmengen), so besteht u.U. der Wunsch, diese Verdichtungsstufen in sekundären Summendatenbanken zu speichern, um insbesondere die Folgeeinspeicheurng zu entlasten. Siehe hierzu 2.4 Abziehen von Summendatenbanken.
8 Statistik über Statistiken PCL1054
Mit Hilfe von Statistik über Statistik soll es ermöglicht
werden festzustellen, wer wann welche Elemente von ASS
(Arbeitsgebiete, Schlüssel, Werte, Verdichtungsstufen ...)
benutzt hat und wie stark die Nutzung der betreffenden
Elemente überhaupt ist. Diese Nutzungsdaten werden in
einem speziellen ASS-Arbeitsgebiet verwaltet und stehen
somit der ASS-Auswertung zur Verfügung.
ASS-Arbeitsgebiete werden über externe Schnittstellen
gepflegt. Die Aufgabe von PCL1054 ist es, externe Schnittstellen
für das Arbeitsgebiet für Statistik über
Statistik zu erzeugen.
Um auch feststellen zu können, welche Elemente von ASS
wenig oder gar nicht benutzt werden, kann in das
betreffende Arbeitsgebiet auch gespeichert werden, welche
Elemente überhaupt zur Verfügung stehen.
PCL1054 kennt daher zwei grundsätzlich verschiedene Arbeitsweisen:
- Erzeugung von externen Schnittstellen, die die zur Verfügung stehenden Elemente von ASS enthalten (UMGEBUNG=DST003 bzw. UMGEBUNG=DST004, s.u.).
- Erzeugung von externen Schnittstellen, die die Information enthalten, wer wann welche Anforderungen ausgeführt hat und wie oft (UMGEBUNG=BATCH bzw. UMGEBUNG=ONLINE, s.u.).
Sollen Statistiken über Statistiken erzeugt werden, so müssen in bestimmten Zeitabständen mit Hilfe von PCL1054 die erforderlichen externen Schnittstellen erstellt und eingespeichert werden, um anschließend die gewünschten Auswertungen durchführen zu können.
FUNKTIONSBESCHREIBUNG:
UMGEBUNG=DST003 bzw. UMGEBUNG=DST004
Diese Optionen können jederzeit eingesetzt werden.
Es wird eine externe Schnittstelle erzeugt, die die
zur Verfügung stehenden Arbeitsgebiete, Schlüssel,
Werte und Verdichtungsstufen (UMGEBUNG=DST003)
bzw. die zur Verfügung stehenden Anforderungen, Anwendungen
Schlüssel-Gruppierungen, Werte-Gruppierungen und
Formeln enthält (UMGEBUNG=DST004).
Die ASS-Zeit wird durch die Option MONAT= ... (s.u.)
festgelegt.
Es wird der aktuelle Zustand der DST003 bzw. DST004
abgebildet. Läufe von PCL1054 zu unterschiedlichen
Zeitpunkten mit gleicher MONATsoption haben daher i.a.
unterschiedliche externe Schnittstellen zur Folge.
In der zugehörigen Summen-Datenbank werden die
ermittelten Informationen aufkumuliert. Es ist also
möglich zu erkennen, welche Elemente von PCL1054
bei irgendeinem Lauf von PCL1054 gefunden wurden.
Es werden nur Arbeitsgebiete betrachtet, die eingespeichert
sind und deren Prüfkennzeichen nicht auf NEIN steht.
UMGEBUNG=ONLINE bzw. UMGEBUNG=BATCH
Die Auswertung protokolliert, wer wann welche Anforderung ausgeführt hat (wenn diese Funktion aktiviert ist). Online ausgeführte Anforderungen werden in der DST004, im Batch ausgeführte Anforderungen werden in der Datei PWORK protokolliert. Diese Protokolle werden von PCL1054 gelesen und in externe Schnittstellen umgeformt.
Ist ASS in einer Linux-Umgebung installiert, so kann festgelegt werden, dass auch die Informationen von Online-Auswertungen in PWORK gespeichert werden. Hierzu ist auf der Textdatenbank auf Seite D A 28 der Schalter STAT-STAT-DST004 = N zu setzen. Diese Variante hat u.a. den Vorteil, dass bei Auswertungen keine Schreibzugriffe auf die Anforderungsdatenbank erfolgen müssen.
Ablauf:
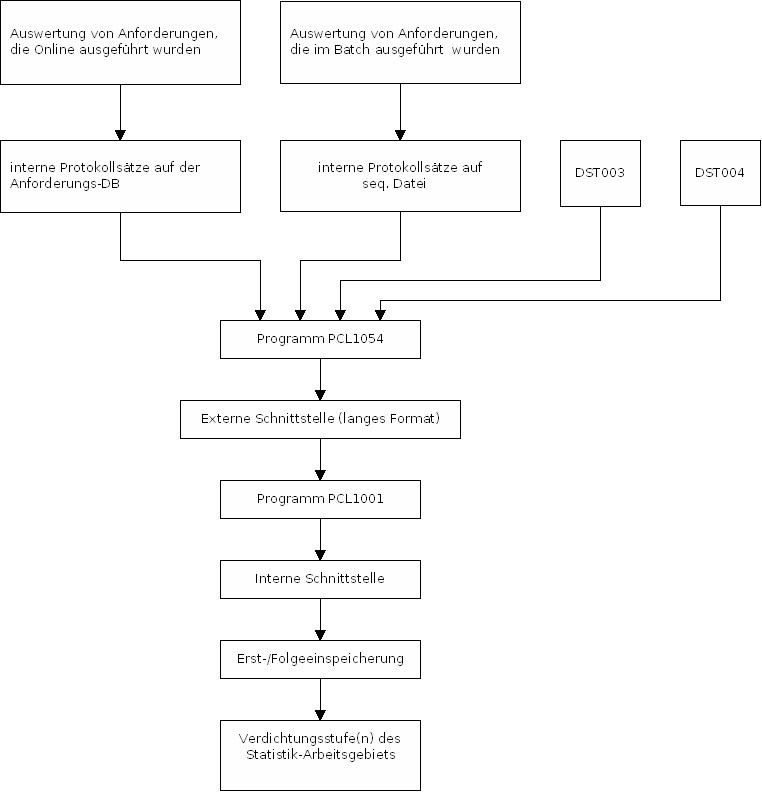
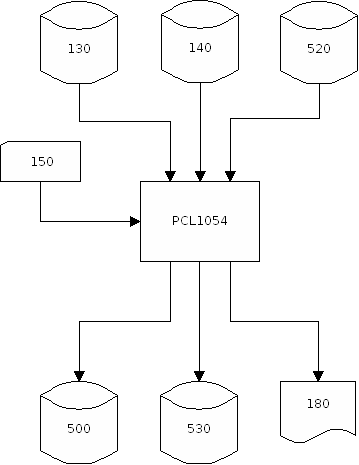
| LFD.-NR. | DD-NAME/PGM | Dateiname ASS-PC | BESCHREIBUNG |
|---|---|---|---|
| 130 | //DST003 //DST031 //DST032 //DST033 | $ASSDB/DST003 | Steuerungsdatenbank (nur DLI) (nur DLI) (nur DLI) (nur Option 'DST003') |
| 140 | //DST004 //DST041 | $ASSDB/DST004 | Anforderungsdatenbank (nur DLI) (nur Optionen 'DST004' oder, falls unter Linux nicht anders installiert, 'ONLINE') |
| 150 | //ASSCO | $ASSVLK/T1054.VLK | Vorlaufkarten |
| 180 | //LISTE | $ASSPTK/PCL1054.PTK | Protokoll und Fehlermeldungen |
| 500 | //ASSIN01 | $ASS/ASSIN01 | Externe Schnittstellensätze |
| 520 | //PWORK | $ASS/PWORK | Eingabe der im Batch geschriebenen Statistiksätze (Standard: nur Option 'BATCH'; unter Linux installationsabhängig auch ONLINE) |
| 530 | //ASSFEHL | $ASS/ASSFEHL | Fehlerhafte Protokollsätze |
Die Datei PWORK:
Die Behandlung der Datei PWORK ist im Handbuch 'INSTALLATION' beschrieben.
Besonderheiten bei UMGEBUNG=BATCH bzw. UMGEBUNG=ONLINE:
Werden Schnittstellensätze aus der Anforderungs-Datenbank erzeugt, so werden die verarbeiteten Sätze aus der Anforderungs-Datenbank gelöscht.
Läuft die Batch-Auswertung (PCL1003/PCL1016) über Mitternacht bei Monatswechsel (z.B. in der Nacht vom 31.8. zum 1.9.), so enthält eine Datei PWORK Protokollangaben zu unterschiedlichen Monaten. Werden mehrere Dateien PWORK zu einer Datei zusammengefasst, so kann diese zusammenfassende Datei ebenfalls Protokollangaben zu unterschiedlichen Monaten enthalten. In beiden Fällen muss die betreffende Datei mehrfach von PCL1054 mit unterschiedlichen MONATsangaben in der Vorlaufkarte verarbeitet werden.
Datenmenge bei UMGEBUNG=BATCH bzw. UMGEBUNG=ONLINE:
Die Protokollsätze enthalten in kompakter Form, wer was wann angefordert hat. Da aus Anforderungen verschiedene Statistiken über Statistiken versorgt werden können, kann die Anzahl der erzeugten Schnittstellensätze auch ziemlich groß werden. Diese Anzahl hängt von der Größe und Komplexität der Anforderung ab. Ein Verhältnis von 1:20 bis 1:50 dürfte am häufigsten vorkommen.
Vorlaufkarte:
| PARAMETER | BEDEUTUNG / AUSWIRKUNG |
|---|---|
| PROGRAMM=PCL1054 | Zur Kontrolle wird geprüft, ob die Vorlaufkarten-Datei zum Programm PCL1054 gehört. Diese Option muss angegeben werden. |
| UMGEBUNG=ONLINE | Es werden die Protokollsätze von den
Anforderungen, die in der Anforderungs-Datenbank (DST004)
stehen, verarbeitet. Falls unter Linux STAT-STAT-DST004=N (s.o.), wird statt der DST004 die Datei PWORK verarbeitet. Dann werden sowohl Sätze aus Online- als auch aus Batch-Anforderungen in einem Lauf verarbeitet. UMGEBUNG=ONLINE und UMGEBUNG=BATCH sind dann also äquivalent! |
| UMGEBUNG=BATCH | Es werden die Protokollsätze von den
Anforderungen, die in der Datei PWORK
stehen, verarbeitet. Falls unter Linux STAT-STAT-DST004=N (s.o.), werden auch die Online-Auswertungen in PWORK protokolliert. Es werden dann also Sätze aus Online- und aus Batch-Anforderungen in einem Lauf verarbeitet. UMGEBUNG=ONLINE und UMGEBUNG=BATCH sind dann also äquivalent! |
| UMGEBUNG=DST003 | Die Steuerungs-Datenbank wird auf die externe Schnittstelle abgebildet |
| UMGEBUNG=DST004 | Die Anforderungs-Datenbank wird auf die externe Schnittstelle abgebildet |
| MONAT=JJMM MONAT=AKT MONAT=ALLE |
Die Angabe des Monats in der Form
JJMM gibt an, welche Protokollsätze
verarbeitet werden sollen.
Protokollsätze anderer Monate werden
überlesen. Diese Angabe ist optional. Falls die Angabe des Monats nicht erfolgt, wird der Monat vor dem aktuellen Kalendermonat gesetzt. Die Angabe AKT bewirkt, dass nicht der Vormonat, sondern der aktuelle Monat behandelt wird. Die Angabe ALLE (nur für Umgebung ONLINE und BATCH) bewirkt, dass alle Protokollsätze verarbeitet werden. Sie bietet sich inbesondere bei STAT-STAT-DST004=N (s.o.) an, da dann die gesamte PWORK in einem Lauf verarbeitet wird und neu aufgesetzt werden kann. Bei Umgebung = DST003 oder ... = DST004 wird mit Monat = die ASS-Zeit der externen Schnittstelle festgelegt. ACHTUNG: Bei AKT und ALLE sollten aktuell keine Auswertungen ausgeführt werden, da diese nur unvollständig verarbeitet werden können! |
| LOESCHEN | Zusätzlich zu der normalen Verarbeitung werden alle Protokollsätze auf der Anforderungsdatenbank, die vor dem zu verarbeitenden Monat liegen, bei Verarbeitung der Umgebung ONLINE gelöscht. |
| USERID=SUBSTR (USERID,von,laenge) |
Die UserID (d.h. die Inhalte von ANFORDERER und PROFIL)
wird ab der Position "von" in
der Länge "laenge" auf die externe
Schnittstelle ausgegeben. Falls dabei
nur Blanks übrigbleiben wird
stattdessen wie auch sonst die
Dummy-Ausprägung 000000000000
ausgegeben. Bspl.: SUBSTR(USERID,1,3) gibt nur die ersten drei Zeichen aus. |
| CSV CSVFIX |
Die externe Schnittstelle wird im Textformat erzeugt (EXIT_TEXT in PCL1001). Bei CSV steht in jedem Summensatz immer nur ein Wert, bei CSVFIX werden immer alle Werte im Satz ausgegeben, wobei dann immer nur einer nicht 0 ist. Für die Einspeicherung sind beide Varianten äquivalent. Bei CSVFIX ist die Schnittstelle aber ggf. leichter maschinell manipulierbar. |
| FELD_LEER_OK |
ASS7427 CSV MIT UNZULAESSIGER AUSPRAEGUNG
als Warnung statt Fehler. Die Folgeverarbeitung muß gegebenenfalls angepaßt werden. Bitte informieren Sie Ihren Administrator für eine Problemübermittlung. |
Vorlaufkartenbeispiele
Erzeugung der externen Schnittstellensätze für die Einträge des Monats September 1988 auf der Anforderungsdatenbank:
PROGRAMM=PCL1054,UMGEBUNG=ONLINE,MONAT=8809
Erzeugung der externen Schnittstellensätze für die Einträge der Batch-Programmläufe des Monats Juli 1988:
PROGRAMM=PCL1054,UMGEBUNG=BATCH,MONAT=8807
Erzeugung der externen Schnittstellensätze im Monat September 1988 für die Einträge der Online-Programmläufe des Vormonats August 1988:
PROGRAMM=PCL1054,UMGEBUNG=ONLINE
Erzeugung der externen Schnittstellensätze im Monat September 1988 für die Einträge der Online-Programmläufe für den Monat September 1988:
PROGRAMM=PCL1054,UMGEBUNG=ONLINE,MONAT=AKT
Erzeugung der externen Schnittstellensätze für die zur Verfügung stehenden Arbeitsgebiete, Schlüssel, Werte und Verdichtungsstufen und für die zur Verfügung stehenden Anforderungen, Anwendungen, Schlüsselgruppierungen, Wertegruppierungen und Formeln:
- PROGRAMM=PCL1054
- UMGEBUNG=DST003
- UMGEBUNG=DST004
- MONAT=AKT
9 Betrieb der ASS-Online-Security
Falls eine Security-Lösung mittels der Online-Transaktion ST09 angestrebt wird, müssen die genannten Datenbanken für Online-Verarbeitung zugreifbar sein und die Transaktion ST09 gestartet sein (siehe Kap. 9.1 ff).
9.1 DLI
Die ASS-Security-Datenbanken müssen ONLINE zugreifbar sein, die Transaktion ST09 gestartet sein.
- DST007
- DST071
- DST009
- DST091
9.2 ADABAS
ADABAS muss aktiv sein und die erforderlichen ADABAS-Files müssen im JOB, in dem die Transaktion ST09 abläuft, zugeordnet sein, ST09 muss gestartet sein.
9.3 BS2000-ISAM
Die Transaktionen ST06, ST31 und ST09 sind in einer UTM-Anwendung zusammengefasst, siehe daher 6.3.
10 Tuning
10.1 Interner Ablauf einer Auswertung
Wird eine Anforderung bearbeitet, so werden die folgenden Schritte durchlaufen:
- Prüfen auf formale Richtigkeit
Als erstes wird die Anforderung daraufhin überprüft, ob sie formal richtig ist (z.B. sind Werte angefordert, sind die Zeiten richtig angefordert etc.). Diese Syntaxprüfung erfolgt im Programm MCL0016. - Prüfen auf logische Richtigkeit
Im zweiten Schritt wird geprüft, ob die Anforderung logische Fehler enthält (Semantikprüfung). Gleichzeitig werden interne Tabellen aufgebaut, in denen die benötigten Informationen über Schlüssel, Ausprägungen, Werte, Zeiten etc. abgelegt werden. Diese Informationen müssen aus den Parameterdatenbanken gelesen werden. Dies kann bei größeren Arbeitsgebieten und bei Massenschlüsseln zu einer großen Anzahl von Datenbank-Zugriffen führen und dadurch die Performance gerade bei Online-Auswertungen stark beeinträchtigen. Deswegen besteht die Möglichkeit, Arbeitsgebiets- und Schlüsselcaches einzurichten, die die Datenbankzugriffe reduzieren (siehe Kap. 10.3). Dafür ist das MCL0017 mit Unterprogrammen zuständig. - Verarbeitung der Summensätze festlegen
Als nächstes wird die Verarbeitung der Summensätze festgelegt. Es wird bestimmt, welche Verdichtungsstufen mit welcher Lesestrategie zu verarbeiten sind (siehe Kap. 10.4). Dies geschieht im MCL0008. - Lesen der Summensätze
Weiter werden dann im MCL0009 die Summensätze gelesen und in eine interne Tabelle verteilt. Dabei werden nur die 'echten' Werteeinträge berücksichtigt. - Berechnungen durchführen
Formeln, Sternsummen, Funktionen etc. werden danach im MCL0010 (und Unterprogrammen) berechnet. Dabei wird die interne Tabelle (aus MCL0009) strikt von oben nach unten abgearbeitet. - Statistik aufbereiten
Zuletzt wird die berechnete Statistik aufbereitet (Anzeige von Bezeichnung, Abkürzung, Spaltenbreiten festlegen etc.) und ausgegeben (MCL0006).
10.2 Ausprägungsergänzung bei Online-Auswertungen
Steht nicht mehr zur Verfügung.
10.3 Die Schlüssel- und Arbeitsgebietscaches
10.3.1 Aufbau und Aufgabe der Schlüsselcaches
ASS bietet dem Benutzer die Möglichkeit, sogenannte Schlüssel- oder Ausprägungscaches anzulegen. Diese Caches sind Massen- bzw. Sammelspeicher für die Ausprägungen eines Schlüssels. Dementsprechend werden sie in der Schlüsseldatenbank (in den Segmenten SST015CK und SST016CL) abgelegt, und zwar sind sie dem Schlüssel logisch untergeordnet. Die Caches werden je nach der Informationsmenge, die sie enthalten, als kurzer und langer Cache bezeichnet.
Schlüsselcaches sind bei Schlüsseln mit interner Länge 3 oder 4 nicht möglich. Das unten beschriebene Zugriffsverhalten auf Schlüsselausprägungen gilt nur für Schlüssel der internen Länge 1 oder 2. Bei Schlüsseln der internen Länge 3 oder 4 wird ganz anders zugegriffen.
Der prinzipielle Aufbau der Caches sei nun am kurzen
Cache beschrieben: In ihm wird nur der verdichtete
Schlüsselinhalt und der Schlüsselinhalt in variabler
Länge zusammen mit einem Längenfeld abgespeichert. Im
Anschluss folgen die entsprechenden Informationen der
nächsten Ausprägung. Dies geschieht solange, bis die
maximale Satzlänge des Segments erreicht wird. Die
folgenden Ausprägungen werden dann im nächsten Segment
abgelegt.
Der lange Cache enthält darüber hinaus noch
Informationen über Inhaltsbezeichnung, Inhaltskurzbezeichnung,
Gültigkeitsdaten und bei hierarchischen Schlüsseln die
übergeordnete Ausprägung, teilweise auch wieder in
verkürzter Form. Der prinzipielle Aufbau ist derselbe
wie beim kurzen Cache.
Die Caches dienen dazu, während einer Auswertung die Performance zu verbessern. Dies sei am besten an einem Beispiel erläutert: In manchen Situationen, wie z.B. bei der Behandlung von Ausprägungsmengen oder dem Aufsammeln von Ausprägungen, müssen ohne den Cache sämtliche Ausprägungen zu einem Schlüssel gelesen werden. Bei einem Schlüssel mit 20000 Ausprägungen (z.B. Kundennr.) sind also 20000 Lesezugriffe auf die Schlüsseldatenbank nötig. Dieselbe Information kann aber unter Verwendung des (z.B.) kurzen Caches bereits in einigen hundert Sätzen der Schlüsseldatenbank abgelegt werden. Die Anzahl der Lesezugriffe zur Schlüsseldatenbank kann damit deutlich reduziert werden.
Da bekanntlich Zugriffe auf eine Datenbank relativ viel Zeit brauchen, kann dadurch in kürzerer Zeit eine Auswertung ausgeführt werden. Dies macht sich insbebesondere im Online-Betrieb positiv bemerkbar.
Die Schlüsselcaches werden von ASS nicht automatisch gepflegt, d.h. der Benutzer muss selbst entscheiden, ob zu einem Schlüssel die Caches angelegt werden sollen. Bei Änderungen bei den Ausprägungen wird der zugehörige Cache ungültig.
Ob Caches angelegt oder gelöscht werden sollen, wird ASS in der Transaktion ST06 mitgeteilt. (s. entsprechendes Handbuch). Diese Information wird in der Schlüsseldatenbank abgelegt. Die Caches müssen mit dem Programm PCL1089 angelegt bzw. gelöscht werden (s.u.). Das Einrichten eines Caches für einen Schlüssel lohnt sich praktisch nur, um Online-Auswertungen zu beschleunigen.
Der Cache beschleunigt folgende Auswertungstypen:
- es werden alle Ausprägungen angefordert.
- es wird mit Ausprägungsmengen oder mit ?-Maskierung gearbeitet.
Gibt es Änderungen bei den Ausprägungen, wird von ASS
eine Kennzeichnung in der Schlüsseldatenbank mitgepflegt,
aus der ersichtlich ist, ob die Caches noch dem
aktuellen Stand der Ausprägungen entsprechen. Diese
Kennzeichnung kann ebenfalls über die Transaktion ST06
abgerufen werden. Sind die Caches nicht auf dem aktuellen
Stand, so können sie wieder mit dem Programm PCL1089
aktualisiert werden.
Wird also z.B. bei einem Schlüssel mit automatischer
Ausprägungsergänzung gearbeitet, so empfiehlt es sich,
nach jeder Folgeeinspeicherung PCL1089 laufen zu lassen.
10.3.2 Erzeugen und Löschen der Schlüsselcaches PCL1089
FUNKTIONSBESCHREIBUNG:
Mit dem Programm PCL1089 können Schüsselcaches erzeugt oder gelöscht werden. Die Information, ob zu einem Schlüssel Caches erzeugt bzw. gelöscht werden sollen, entnimmt das Programm der Schlüsseldatenbank (Segment SST011KY) (siehe auch Handbuch ST06).
Ist das Kennzeichen auf 'T' oder 'A' gesetzt, so werden zu dem betreffenden Schlüssel der lange und der kurze Cache erzeugt. Beim Kennzeichen 'D' werden die Caches gelöscht. Außerdem wird die Kennzeichnung dem neuen Zustand der Caches angepasst.
Es empfiehlt sich, PCL1089 immer dann laufen zu lassen, wenn sich in der Schlüsseldatenbank bei den Schlüsselausprägungen etwas geändert hat.
Dies ist in folgenden Fällen möglich:
- bei Änderungen im Dialog mit Transaktion ST06
- bei Folgeeinspeicherungen
- beim Zurückladen eines Arbeitsgebiets mit PCL1005
- beim Erfassen von Ausprägungen mit PCL1036
- beim Löschen von Ausprägungen mit PCL1055
- bei der Reorganisation der internen Schlüsselinhaltsnummern mit PCL1058
ABLAUF:

| Nr. | DD-Name | Dateiname ASS-PC | Beschreibung |
|---|---|---|---|
| 1 2 | DST002 DST021 DST022 DST023 | $ASSDB/DST002 | Schlüssel-DB Primärindex 1. Sekundär- 2. index (nur DLI) |
| 3 | PROTO | $ASSPTK/PCL1089.PTK | Protokoll |
10.3.3 Cache für Arbeitsgebiete PCL1046
Der Cache für Arbeitsgebiete dient zur Verbesserung
der Performance beim lesenden Zugriff auf die
Steuerungsdatenbank im Rahmen der Auswertung.
Die Optimierung wird dadurch erreicht, dass mehrere
Sätze der Steuerungsdatenbank zu einem neuen Satz
zusammengefasst werden. Dies wird durch das
Dienstprogramm PCL1046 erledigt. Jede Änderung eines
Arbeitsgebiets (z.B. durch ST06, Plandaten/Vorgabewerte
in der ST31 und Batchprogramme) wird also erst
nach einem erneuten Lauf von PCL1046 wirksam.
Soll der Cache benutzt werden, so sollte er
täglich kurz vor Beginn des ONLINE-Betriebs neu mit
PCL1046 erstellt werden.
Zur Zeit ist der Cache für Arbeitsgebiete nur in einer
DLI-, DB2- oder VSAM-Installation verfügbar.
Bei PC-Isam(Windows) wird standardmäßig mit dem Cache für
Arbeitsgebiete gearbeitet.
Der Cache für Arbeitsgebiete liegt physisch auf der
SPA-Datenbank (DST005) und wird dort von dem
Dienstprogramm PCL1046 aktualisiert. Im Cache werden
die verwendeten Schlüssel, Verdichtungsstufen, Werte
und gegebenenfalls der Schlüsselausschluss
gespeichert. Da der Cache pro Arbeitsgebiet in der
Größe beschränkt ist, listet das Dienstprogramm
PCL1046 zu jedem Arbeitsgebiet an, zu welchem
Prozentsatz der Cache gefüllt ist. Ist für ein
geprüftes Arbeitsgebiet der Cache zu klein, so bricht
das Programm mit einer entsprechenden Meldung ab und ab
diesem Arbeitsgebiet einschließlich ist der Cache nicht
mehr vorhanden.
Im Handbuch "Installation" ist beschrieben wie die
Größe des Cache berechnet werden kann und wie er
gegebenenfalls vergrößert werden kann. Im Protokoll
des Dienstprogramms PCL1046 wird auch angelistet zu
wieviel Prozent der Cache pro Arbeitsgebiet belegt wird.
Wie der Cache wirksam wird, steht ebenfalls im
Handbuch "Installation".
Ablauf von PCL1046
Dateibeschreibung:
ASSLIST $ASSPTK/PCL1046.PTK Protokoll
Eine Vorlaufkarte gibt es nicht.
10.4 Lesen von Verdichtungsstufen
10.4.1 Lesestrategien auf die Summendatenbank
Um die Bearbeitungszeit von ASS während einer Auswertung niedrig zu halten, müssen die Informationen aus den Verdichtungsstufen möglichst effizient, d.h. mit wenigen Zugriffen, gelesen werden. Aus diesem Grund kennt ASS fünf verschiedene Lesestrategien:
- Sequentielles Lesen
Das sequentielle Lesen ist die einfachste Form, eine
Verdichtungsstufe auszuwerten. Hierbei werden alle
Sätze einer Verdichtungsstufe sequentiell gelesen und
verarbeitet. Diese Methode wird angewandt, wenn z.B.
keine Ausprägungen selektiert werden oder die Daten der
betreffenden Verdichtungsstufe auf einer sequentiellen
Datei gespeichert sind. Sie wird darüber hinaus immer
dann verwendet, wenn die nachfolgend beschriebenen
Lesestrategien nicht möglich sind.
Die Zahl der erforderlichen Zugriffe ist gleich der
Anzahl der Sätze in der Verdichtungsstufe. Bei
umfangreichen Verdichtungsstufen ist somit eine
Online-Auswertung nicht möglich.
- Direktes Lesen mit Schlüsselvariation
Werden in einer Anforderung einzelne Ausprägungen eines
Schlüssels selektiert, kann die Anzahl der erforderlichen
Zugriffe meist durch direktes Lesen mit
Schlüsselvariation deutlich verringert werden. Hierbei wird zu
jedem Schlüssel der Verdichtungsstufe eine Ausprägung
ausgewählt, wobei man sich jedoch bei angeforderten
Schlüsseln auf die gewünschten Ausprägungen
beschränkt. Diese werden dann verknüpft und als Index
zum direkten Lesen der Verdichtungsstufe verwendet. Dies
wird für alle möglichen Kombinationen der zu den
jeweiligen Schlüsseln gehörenden Ausprägungen
durchgeführt.
Dementsprechend erhält man die Anzahl der
erforderlichen Zugriffe, indem man für jeden Schlüssel der
Verdichtungsstufe die Zahl der Ausprägungen miteinander
multipliziert. Dazu ein
Beispiel:
| Schlüssel | Niederl. | Produkt | Kundengr. |
|---|---|---|---|
| Zahl Ausprägungen | 50 | 20 | 5 |
| Ausprägungen | NL1 | P1 | KG1 |
| . | . | . | |
| . | . | . | |
| NL50 | P20 | KG5 |
In dieser Verdichtungsstufe seien 4000 Sätze vorhanden, d.h von den 5000 möglichen Ausprägungskombinationen gibt es zu 1000 keine Werte. Weiter liege folgende Anforderung vor:
Niederlassung=(NL3,NL15), Produktgruppe=(PG5,PG6,PG7)
Damit ergibt sich die Zahl der Zugriffe aus
Ausprägungen(Niederl.)xAuspr(Produkt)xAuspr(Kundengr)
also Zugriffe = 2 x 3 x 5 = 30
Dieses Produkt ist oft größer als die Anzahl der Sätze in der Verdichtungsstufe, weil meistens nicht für alle Ausprägungskombinationen Werte vorhanden sind.
- Positionieren auf den 'linkesten' Schlüssel (stückweise sequentielles Lesen)
Als weitere Lesestrategie ist das stückweise sequentielle Lesen der Verdichtungsstufe möglich. Bei dieser Strategie wird für den Schlüssel, der am weitesten links in der Verdichtungsstufe steht und ausgeprägt ist, eine gewünschte Ausprägung als Index verwendet und mit dieser in der Verdichtungsstufe direkt positioniert. Danach wird solange sequentiell gelesen, bis in der Verdichtungsstufe eine neue Ausprägung für den 'linkesten' Schlüssel auftritt. Bei dieser Zugriffsvariante wird die Zahl der erforderlichen Zugriffe mit folgender Formel geschätzt:
In dieser Schätzung wird davon ausgegangen, dass die Ausprägungen (*) in der Verdichtungsstufe gleichmäßig verteilt sind. Es gibt jedoch Fälle, in denen diese Annahme verletzt wird. Es gibt z.B. bei einem Schlüssel 'Vertreter' 10000 Ausprägungen, in dem Arbeitsgebiet werden aber für nur 1000 Ausprägungen Werte gepflegt. In solchen Fällen liefert die Schätzung zu kleine Zahlen für die Zugriffszahl. Dies hat längere Laufzeiten zur Folge, die im Online-Betrieb nicht gewünscht werden. Um dies berichtigen zu können, kann (*) in der Formel überschrieben werden. Dazu ist in der Transaktion ST06 die ungefähre Anzahl der im Arbeitsgebiet verwendeten Ausprägungen eines Schlüssels anzugeben (s. Handbuch ST06).
Positionieren auf die 'linkesten' Schlüssel mit Schlüsselvariation
Diese Methode kombiniert die Methode der Schlüsselvariation mit der Methode des stückweise sequentiellen Lesens. Diese Methode wird am besten an einem Beispiel verdeutlicht:
Es wird das Beispiel aus der Schlüsselvariation betrachtet. Die betrachtete Verdichtungsstufe enthalte rechts von der Kundengruppe noch weitere Schlüssel, so dass eine reine Schlüsselvariation nicht mehr in Betracht kommt.
Es liege folgende Anforderung vor:
Niederlassung=(NL3,NL15), Kundengruppe=(KG1)
Folgende Datensätze können Information enthalten:
| NL3 | P1 | KG1 |
| NL3 | P2 | KG1 |
| . | ||
| . | ||
| . | ||
| NL3 | P20 | KG1 |
| NL15 | P1 | KG1 |
| NL15 | P2 | KG1 |
| . | ||
| . | ||
| . | ||
| NL15 | P20 | KG1. |
Es gibt also insgesamt 2 * 20 * 1 = 40 Kombinationen. Da nicht bekannt ist, welche Ausprägungen rechts von der Kundengruppe vorkommen, wird jede der genannten Kombinationen stückweise sequentiell ausgewertet. Hierbei ist zu beachten, dass nicht nur über den linkesten, sondern über die drei linkesten Schlüssel positioniert wird (compound key). Im obigen Beispiel wird also 40-mal stückweise sequentiell gelesen.
Die Schätzformel für die Anzahl der Zugriffe ist
eine Kombination aus der Anzahl Zugriffe für die
Variation mit der Schätzung fürs stückweise sequentielle
Lesen.
Die obige Methode kann auch zum Einsatz kommen,
wenn zwischen Niederlassung und Kundengruppe
verdichtete Schlüssel enthalten sind. Ebenso kann
diese Methode zum Einsatz kommen, wenn "linkeste"
Schlüssel einer Verdichtungsstufe nicht angefordert
werden, sie jedoch so wenig Ausprägungen besitzen,
dass eine Variation noch möglich ist.
Ausnutzung von Schlüsselrelationen
Sobald in einer Fragestellung zu einem selektierten Schlüssel, der nicht linkester Schlüssel einer Verdichtungsstufe ist, alle zugehörigen Ausprägungen des linkesten Schlüssels angefordert werden, ist eine Dialogauswertung mit den bisher bekannten Lesevarianten im Normalfall nicht möglich.
Es empfiehlt sich dann, mit Schlüsselrelationen zu arbeiten, die technisch ähnlich wie Verdichtungsstufen in einem Arbeitsgebiet definiert werden. In einer Schlüsselrelation werden zwischen zwei und zehn Schlüssel des Arbeitsgebietes in einer bestimmten Reihenfolge definiert, die von der üblichen Hierarchiefolge völlig abweichen kann.
Im Unterschied zu den Verdichtungsstufen werden bei Schlüsselrelationen keine Werteverwendungen definiert und auch keine Summendaten gespeichert, sondern lediglich die in den Summendaten enthaltenen Schlüsselkombinationen.
Betrachtet man das obige Beispiel, so könnte man in einer Relation die Schlüssel PRODUKT und NIEDERLASSUNG in dieser Reihenfolge definieren.
Nur die in den Summendaten vorkommenden Schlüsselkombinationen werden gespeichert:
| PRODUKT | NIEDERLASSUNG |
|---|---|
| P1 | NL1 |
| NL5 | |
| P2 | NL7 |
| NL20 | |
| P3 | NL5 |
Möchte man jetzt die Werte für das Produkt P1 in allen Niederlassungen ermitteln, liefert die Relation nur die beiden in den Summendaten enthaltenen Niederlassungen NL1 und NL5.
Mit diesen beiden Ausprägungen des jetzt bekannten, linkesten Schlüssels der Verdichtungsstufe können die Daten wiederum stückweise sequentiell oder auch direkt gelesen werden, wenn alle Schlüssel des Arbeitsgebietes in der Relation beschrieben sind.
Unter diesen fünf Lesestrategien einer Verdichtungsstufe wählt ASS sich die günstigste aus. Oft ist es jedoch für eine Auswertung nötig, mehrere Verdichtungsstufen zu lesen, z.B. wenn Werte aus verschiedenen Arbeitsgebieten angefordert werden. In diesem Fall wird für jede Verdichtungsstufe die effektivste Lesestrategie ausgewählt. Die Anzahl der Zugriffe ergibt sich dann als Summe der Zugriffszahlen für die einzelnen Verdichtungsstufen.
Durch geschickte Vergabe der Hierarchienummern und durch geeignete Festlegung von Verdichtungsstufen sowie deren Schlüsselreihenfolgen beim Einrichten eines Arbeitsgebietes (Transaktion ST06) kann der Anwender erreichen, dass die verschiedenen Lesestrategien vorteilhaft eingesetzt werden. Dabei sollten z.B. häufig benutzte Schlüssel mit vielen Ausprägungen, von denen i.a. nur einige angefordert werden, möglichst weit nach links gestellt werden, also niedrige Hierarchienummern im Arbeitsgebiet erhalten oder gezielt durch Änderung der Schlüsselreihenfolge betroffener Verdichtungsstufen.
10.4.2 Auswahl von Verdichtungsstufen in der Auswertung
Die Verdichtungsstufen, die für eine Auswertung gelesen werden müssen, werden nach folgendem Verfahren ermittelt:
- Zunächst werden für jeden angeforderten Wert die Verdichtungsstufen ermittelt, die prinzipiell in Frage kommen. Dies bedeutet, dass die (zu dem Wert) eingespeicherten Zeiten zumindest einen Teil der angeforderten Zeiten abdecken und dass alle angeforderten Schlüssel in der Verdichtungsstufe ausgeprägt sind.
- Für die unter 1. ermittelten Verdichtungsstufen werden die Zugriffszahlen ermittelt. Dabei werden die unter 10.4.1 beschriebenen Lesestrategien durchgetestet und die Zugriffszahl der günstigsten Strategie festgehalten.
- Pro angeforderten Wert werden aus den unter 1) ermittelten Verdichtungsstufen die Mengen zu einer logischen Verdichtungsstufe zusammengefasst, wobei die Zugriffe der einzelnen Verdichtungsstufen einer Menge aufaddiert werden. Danach werden die Mengen nach den Zugriffszahlen sortiert, um die Verdichtungsstufen (-mengen) mit den kleinsten Zugriffszahlen bevorzugen zu können.
- Die angeforderten Werte werden nach ihrer (nach 3.) günstigsten Verdichtungstufe absteigend sortiert, d.h. der Wert, dessen beste Verdichtungsstufe die größte Zugriffszahl besitzt, kommt an die erste Stelle. TOTAL-Operanden werden an die Spitze dieser Tabelle gesetzt.
- Jetzt werden die zu benutzenden Verdichtungsstufen ermittelt. Zunächst werden für den ersten Wert die Verdichtungsstufen nach der Reihenfolge ihrer Zugriffszahlen (s. 3.) ausgewählt, so dass alle angeforderten Zeiten befriedigt werden können. Für die folgenden Werte wird erst geprüft, ob eine bereits ausgewählte Verdichtungsstufe verwendet werden kann. Ansonsten werden analog zum ersten Wert die Verdichtungsstufen ausgewählt.
- Für jede der ausgewählten Verdichtungsstufen
wird die optimale Lesestrategie ermittelt:
Sequentielle Verdichtungsstufen und Verdichtungsstufen für TOTAL-Operanden werden sequentiell gelesen. Bei Verdichtungsstufen auf der Summendatenbank wird zunächst auf stückweise sequentielles Lesen geprüft. Danach wird festgestellt, ob Lesen mittels Relation möglich ist. Anschließend wird auf Compound-Key-Lesen getestet, und zwar der Reihe nach über die zwei, drei, vier, etc. linkesten Schlüssel. Zum Schluss wird noch die Schlüsselvariation getestet. Verbessert sich die Zugriffszahl gegenüber einer zuvor getesteten Strategie, so wird auf die neue Leseregel geschaltet. Die Anzahl der Zugriffe für eine Auswertung ist die Summe der Zugriffe auf die benötigten Verdichtungsstufen.
Stichwortverzeichnis
A B C D E F G H K L P R S T U V Z
- A
- Ablauf einer Auswertung 10.1
- Abziehen von Summendatenbanken (HSSR/PCL1024/PCL1124) 2.4
- Anforderungen ausführen
- ASS-Systemumgebungen 0
- ASSAU (PCL1001) 2.1
- Aufsammeln von Ausprägungen 10.2
- Ausgabeschnittstellen 3 3 4 4.1 4.2 4.3
- Ausprägungstabellen (PCL1001) 2.1
- B
- Batch-Auswertung (PCL1003) 3
- Batch-Auswertung (PCL1016) 3
- Berechtigung 9
- Berichtsdatenbank
4
- Reorganisation 4.3
- D
- Dateneinspeicherung 2 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1 2.1.1 2.2 2.2 2.2 2.2 2.2 2.3 2.4 2.5
- Datensicherung 2.4
- Direktes Lesen mit Schlüsselvariation 10.4.1
- DIREKTSP
- Verarbeitungsoption PCL1002 2.2
- E
- Einrichten Arbeitsgebiet (Technik) 7
- Einspeicherung in Schlüssel mit interner Länge > 2 2.1
- Ergänzung von Ausprägungen (PCL1001 KEYLUECKE) 2.1
- Erzeugen und Löschen Schlüsselcache (PCL1089) 10.3.2
- G
- Generierbare Verdichtungsstufe 2.1
- Generierung von Indizes/Relationen (PCL1001 INDEX_GEN=n) 2.1
- Generierung von Verdichtungsstufen (PCL1001) 2.1
- H
- HSSR
- Abziehen von Summendatenbanken 2.4
- L
- Laden von Berichten auf die Berichts-DB (PCL1095) 4.2
- Laden von Summendatenbanken (PCL1013) 2.3
- Ladevarianten (PCL1002) 2.2
- Laufzeitprobleme (PCL1001) 2.1
- LDAT
- Satzaufbau 3
- Lesestrategien auf die Summendatenbank 10.4
- Listanforderung im Dialog (Technik) 6
- LISTDB
- Satzaufbau 3
- P
- Parameterdaten
- Allgemein
- Schlüssel-DB 7
- Allgemein
- PCL1001
- Verarbeiten der externen Schnittstelle 2.1
- PCL1002
- Verarbeiten der internen Schnittstelle 2.2
- PCL1003
- Batch-Auswertung 3
- PCL1013
- Laden von Summendatenbanken 2.3
- PCL1016
- Batch-Auswertung 3
- PCL1024
- Abziehen von Summendatenbanken 2.4
- PCL1032
- Verzögerter UPDATE für PCL1002 2.5
- PCL1054
- Statistik-Arbeitsgebiet 8
- PCL1083
- Summendatenbankabzug ins Ladeformat bringen 2.4
- PCL1089
- Erzeugen und Löschen Schlüsselcache 10.3.2
- PCL1094
- Verwaltung der Berichtsdatenbank 4.1
- PCL1095
- Laden von Berichten auf die Berichts-DB 4.2
- PCL1124
- Abziehen von Summendatenbanken 2.4
- Platzbedarf für Dateien (PCL1001) 2.1
- Positionieren auf den 'linkesten' Schlüssel 10.4.1
- R
- Reorganisation 4.3
- S
- Schlüssel via Vorlaufkarte (PCL1001) 2.1
- Schlüssel-Cache 10.3
- Schlüsselrelationen (Lesevariante) 10.4.1
- Security 9
- Sequentielles Lesen 10.4.1
- SORTMAX-Parameter (PCL1001) 2.1
- Statistik-Arbeitsgebiet (PCL1054) 8
- Steuerung der Generierung von Verdichtungsstufen 2.1
- Stückweise sequentielles Lesen 10.4.1
- Stückweise sequentielles Lesen mit Variation 10.4.1
- Summendatenbankabzug ins Ladeformat bringen (PCL1083) 2.4
- T
- Tuningmaßnahmen 10
- V
- Verarbeiten der externen Schnittstelle (PCL1001) 2.1
- Verarbeiten der internen Schnittstelle (PCL1002) 2.2
- Verdichtungsstufenmenge 2.1
- Verteilte Summendatenbanken 7.1
- Verwaltung der Berichtsdatenbank (PCL1094) 4.1
- Verzögerter UPDATE für PCL1002 (PCL1032) 2.5
- Vorlaufkarte (PCL1001) 2.1
- Vorlaufkarte (PCL1002) 2.2
- Vorlaufkarte (PCL1003/PCL1016) 3
- Vorlaufkarte (PCL1054) 8
- VORVERDICHTEN
- Schreib-Cache-Verfahren PCL1001 2.1