
0 Vorbemerkung
Die Unternehmensberatung Arnold bietet Schulungen zur Anwendung von ASS in München an, auch eine Einweisung der Anwender vor Ort ist möglich. Außerdem gibt es eine umfangreiche Dokumentation, bestehend aus folgenden Handbüchern:
- SYSTEMDOKUMENTATION
Die Systemdokumentation enthält als einführende Schrift Grundlegendes über die ASS-Begriffswelt und Funktionsweise. Sie vermittelt Ihnen einen ersten Eindruck vom System und ist nützlich beim Einstieg in das ASS. - INSTALLATION und BETRIEB I
Hier werden die Schritte beschrieben, die bei der Erstinstallation, bei Release-Wechseln und sonstigen Änderungen (zum Beispiel die Aktivierung bisher nicht genutzter Leistungsmerkmale) erforderlich sind.
Zielgruppe: die Systemprogrammierung und die DV-Abteilung. - AUSWERTUNG
Die Dokumentation "Auswertung" stellt ASS aus Sicht der Anwender vor. Es liefert die entscheidenden Informationen zur Anforderung von ASS-Statistiken (sowohl Online als auch im Batch-Betrieb). - EINRICHTEN EINES ARBEITSGEBIETES (ST06)
Dieses Handbuch unterstützt Sie dabei, ein von Ihnen konzipiertes Arbeitsgebiet mittels Online-Dialog "ST06" auf den Datenbanken einzurichten. - BETRIEB II
In diesem Handbuch finden Sie Dienstprogramme, die viele nützliche und hilfreiche Funktionen im Batch abdecken. - FEHLERHANDBUCH 1 - 6
In ASS sind Meldungen (Warnungen, Hinweise und Fehlerfälle) mit Nummern versehen (ASS....). Treten Meldungen im Batch oder Online auf, können Sie an Hand der Nummer im Fehlerhandbuch weitere Informationen finden. Dort steht die Ursache der Meldung, und weitere Maßnahmen werden vorgeschlagen.
Dazu kommen Handbücher, die den unterschiedlichen Systemumgebungen entsprechen (z.B. Windows, Unix, DB2 etc.)
1 Zielsetzung von ASS
In der öffentlichen und privaten Wirtschaft werden vielfach Übersichten und Statistiken über verschiedene Bereiche in verschiedenen Darstellungsformen benötigt. Gelegentlich werden diese Übersichten noch in mühsamer Handarbeit aus unterschiedlichen Informationsquellen (z. B. Listen, Berichte) zusammengestellt, in der Regel jedoch mit Hilfe von Rechnerprogrammen erstellt.
Wenn die Geschäftsleitung eine Statistik benötigt, so muss oft die EDV ein neues Programm entwickeln oder ein bestehendes Programm modifizieren. So verstreichen mitunter Wochen, bis die neue Statistik vorliegt.
Wir haben ASS entwickelt, um Ihnen die genannten Arbeiten und lange Wartezeiten zu ersparen. ASS ermöglicht es dem Sachbearbeiter, die gewünschten Informationen selbst abzurufen und in geeigneter Form dargestellt zu bekommen, ohne dass er die Programmierung oder Systemverwaltung einschalten muss.
Das Medium, über das der Sachbearbeiter mit ASS kommuniziert, ist der Bildschirm. Mit einer leicht erlernbaren Sprache, die mit wenigen Grundbegriffen auskommt (Wert, Werteinhalt, Schlüssel, Schlüsselausprägung, Arbeitsgebiet) formuliert der Sachbearbeiter seine Wünsche. Die Auskunft erscheint dann in einer Liste, mit vom Sachbearbeiter vorgegebenem Aufbau. Oder sie erscheint sofort auf dem Bildschirm. Die Listenform eignet sich für umfangreiche Auskünfte. Bei Kurzauskünften reicht oft die Bildschirmausgabe.
Beispiel für eine ASS-Statistik:
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 01.00
I WERTE I I I
I PRODUKTIONSWERT I SOLL_PROD_WERT I ABWEICHUNG I
ORGANISATIONSDIREK I DM I DM I % I
--------------------------------------------------------------------
I I I I
OD HANNOVER VAB I 5.514.109 I 5.000.000 I 10,28 I
OD KOELN VAB I 18.822.944 I 18.000.000 I 4,57 I
OD KARLSRUHE VAB I 17.070.082 I 20.000.000 I 14,65-I
OD NORD VEI I 9.729.497 I 10.000.000 I 2,71-I
I I I I
ENDSUMME I 51.136.632 I 53.000.000 I 3,52-I
(Weitere Beispiele finden sich in Kap. 10.)
2 Begriffsdefinitionen
ASS verwendet Begriffe, die sehr stark an den Sprachgebrauch im Statistikwesen angelehnt sind, um sprachliche und gedankliche Klarheit zu schaffen. Auch die allgemeine Form des Statistikbildes orientiert an diesen Begriffen (vgl. Kap. 3. Allgemeine Statistikaufbau).
Die Begriffe aus 2.1 bis 2.10 sind hier nur kurz definiert, um einen Einstieg in die ASS-Begriffswelt an dieser Stelle zu ermöglichen. Eine ausführliche Begriffsdefinition einschließlich der Erläuterung der zugehörigen Attribute finden Sie im Handbuch EINRICHTEN EINES ARBEITSGEBIETES IM DIALOG.
2.1 Wert
Im Statistik-System ASS sind Werte diejenigen Begriffselemente, deren Inhalte Zahlen sind, also Größen mit Maßzahlen und Maßeinheiten.
Beispiel:
- LEISTUNG
- ABZUEGE
- ANZAHL LEISTUNGEN
- ANZAHL ABZUEGE
In der obigen Statistik sind beispielsweise die Werte
PRODUKTIONSWERT (Maßeinheit DM), SOLL_PROD_WERT
(Maßeinheit DM, gibt den Soll-Produktionswert an) und
ABWEICHUNG (Maßeinheit in %, gibt die relative
Abweichung des Produktionswertes vom Soll-Produktionswert
an) aufgeführt.
ABWEICHUNG ist ein Wert, der aus den beiden anderen Werten
erzeugt werden kann, weil folgende Beziehung besteht:
100 * (PRODUKTIONSWERT - SOLL_PROD_WERT)
ABWEICHUNG = ----------------------------------------
PRODUKTIONSWERT
ASS muss für diese Werte nicht erneut auf die Dateibestände zugreifen, sondern der Benutzer vereinbart sogenannte Werteformeln. Außerdem ist es möglich, einen solchen Wert als ableitbaren Wert zu definieren, besonders wenn er sehr häufig gebraucht wird (siehe auch Kapitel 8.5).
ASS verwendet Bestands- und Bewegungswerte. Sie unterscheiden sich darin, welche Art von Zeitbezug ein in den Summensätzen gespeicherter Wertinhalt repräsentiert: Das heißt, je nachdem, ob ein Wertinhalt stichtags- oder zeitraumbezogen zu interpretieren ist, spricht man von einem Bestands- oder einem Bewegungswert. Bei einem Bewegungswert werden nur die in einem bestimmten Zeitraum aufgetretenen Veränderungen festgehalten (relative Veränderung von einem Stichtag zum anderen). Bei einem Bestandswert dagegen wird der tatsächliche Bestand, der für einen bestimmten Tag ermittelt wurde, gespeichert (Absolutwert). Dieser neue Bestand ergibt sich aus der Summe aus dem ursprünglichen Bestand und den inzwischen aufgetretenen Bewegungen. ASS kennt zusätzlich zu den unabhängig auswertbaren Werten noch sogenannte Umrechnungswerte, die nur in Werteformeln in Zusammenhang mit unabhängigen Werten eingesetzt werden können. Sie enthalten bestimmte Umrechnungssätze, nach denen unabhängige Werte in den Auswertungen neu berechnet werden, z. B. Währungskurse.
2.2 Zeitraum
Der Zeitraum gibt an, auf welche zeitliche Grenze sich die Zählung bei Werten bezieht.
Beispiel:
Im Zeitraum vom 01.12.2000 bis 31.12.2000 wurden
273 Verträge neu abgeschlossen.
Zeitraum: 01.12.00 - 31.12.00
Wert : Anzahl Verträge / 273 Stück
Hinsichtlich der zeitlichen Komponente bestehen im ASS umfangreiche Gestaltungsmöglichkeiten:
- Angabe der gewünschten Zeiträume bei der Auswertung
für die zu erstellende Statistik.
Dabei können Sie bei einer Auswertung ein oder
mehrere Zeiträume angeben, die auch über
Zeitraumintervalle, Zeitraumformeln und relative
Angaben im Bezug zum aktuellen Datum angefordert
werden können.
Durch relative Zeitangaben können Auswertungen erstellt werden, die periodisch wiederkehrend unter Berücksichtigung des aktuellen Datums ausführbar sind. - Pflege zurückliegender Zeiträume (z. B. eine Historie der letzten 15 Jahre) und deren problemloses Einbeziehen in die Auswertungen.
- Durch geschickte Wahl von Werten (vgl. obiges Beispiel) können Sie Soll-Ist-Vergleiche durchführen.
2.3 Schlüssel
Ein Schlüssel bezeichnet stets eine Menge von Objekten der realen Welt. Er betrachtet Objekte unter einem bestimmten Aspekt und unterteilt somit in Rubriken (umgangssprachlich: aufSCHLUESSELn).
Beispiele :
Schlüssel ! Objekte
-------------------------------------------
!
REISETARIF ! 010, 015, 020, ...
!
ORT ! HAMBURG, MUENCHEN, ...
!
KREIS ! MUENCHEN-STADT, MUENCHEN-LAND,
!
LAND ! BAYERN, NIEDERSACHSEN, ...
Schlüssel können völlig unabhängig voneinander sein, zum Beispiel REISETARIF und KREIS.
Es kann aber auch Abhängigkeiten zwischen Schlüsseln geben, z.B. ORT, KREIS, LAND. Zu jedem ORT gehört ein bestimmter KREIS, und zu jedem KREIS gehört ein bestimmtes LAND.
Das sind dann sogenannte "hierarchische Schlüssel": der Schlüssel KREIS ist dem Schlüssel ORT hierarchisch übergeordnet und der Schlüssel ORT ist dem Schlüssel KREIS hierarchisch untergeordnet. Ebenso ist der Schlüssel LAND dem Schlüssel KREIS hierarchisch übergeordnet und der Schlüssel KREIS dem Schlüssel LAND untergeordnet.
2.4 Schlüsselausprägung
Alle Objekte der realen Welt, die unter einem Schlüssel zusammengefasst werden, sind die Schlüsselausprägungen dieses Schlüssels.
Beispiel:
Zusammenfassung der Reisetarife
unter dem Schlüssel REISETARIF
010, 015, 020, 025, 030, 040, 050, 055,
060, 065, 071, 072, 081, 082, 090, 100,
110, 120
Der Schlüssel REISETARIF besitzt also 18 Schlüsselausprägungen.
Die Anzahl der Schlüsselausprägungen ist keineswegs festgeschrieben. Jederzeit können neue Schlüsselausprägungen aufgenommen werden, ohne dass Reorganisationsmaßnahmen notwendig werden. Bei der Anlieferung von neuen Datenbeständen kann der Anwender sogar Schlüsselausprägungen, die bisher nicht existierten, automatisch nachtragen lassen. Jede Schlüsselausprägung besitzt einen Gültigkeitszeitraum, der bei Auswertungen berücksichtigt wird. Außerdem ist es möglich, Umbuchungen in der Historie nachträglich vorzunehmen.
Sie können im ASS die Ausprägungen eines Schlüssel auch in einer von der normalen Sortierung abweichenden Reihenfolge darstellen. Eine Möglichkeit ist es, die Ausprägungen zu Gruppen zusammenzufassen und über diese Gruppen summieren zu lassen. Die so definierten Gruppen sollen eventuell auf einer höheren Betrachtungsebene wiederum zu Gruppen zusammengefasst werden.
So ein Zusammenfassungs- und Anordnungsschema wird mit GRUPPIERUNG bezeichnet.
Bei der Einrichtung einer Gruppierung zu einem Schlüssel ist die Angabe erforderlich, welche Ausprägungen an welcher Stelle in der Gruppierung stehen und wo welche Zwischensummen erzeugt werden sollen. Eine derartige Aussage heißt Gruppenzugehörigkeit.
Die logische Reihenfolge der Ausprägungen wird durch die Abspeicherungsreihenfolge der Sätze zum Ausdruck gebracht.
Wenn Sie nach einer bestimmten Ausprägung Zwischensummen bilden wollen, dann vermerken Sie bei diesem Satz, wieviele Zwischensummen das System bilden soll. Zwischensummen werden standardmäßig mit Sternen gekennzeichnet, können aber auch durch geeignete Texte gekennzeichnet werden.
Weitere Möglichkeiten, Ausprägungen in einer anderen Reihenfolge anzufordern, sind die Angabe von
- Ausprägungsintervallen,
- Ausprägungsmaskierungen,
- Ausprägungsmengen,
- Ausprägungsformeln,
sowie das Einfügen von Leerzeilen und die Negativselektion von Ausprägungen.
Eine eingehende Beschreibung finden Sie im Handbuch AUSWERTUNG.
2.5 Arbeitsgebiet
Für ASS ist ein Arbeitsgebiet die größte logische Einheit für Statistikdaten, wobei gemeinsame Auswertungen über mehrere Arbeitsgebiete durchaus möglich sind. Der Benutzer kann sich nach seinen eigenen Erfordernissen Arbeitsgebiete einrichten.
Diese ASS-spezifische Einrichtung wurde geschaffen, um das unter einer angenommenen obersten Dateneinheit anfallende, für das gesamte Unternehmen nicht mehr in einem überschaubaren Rahmen zu vereinigende Datenmaterial zu proportionieren. Und es hinsichtlich der Anforderungen der modernen Datenverarbeitung geeignet zu gliedern.
Statistiken, die sich fachlich auf denselben Bereich beziehen, werden zu einem Arbeitsgebiet zusammengefasst und somit in der Betrachtungsweise von anderen Bereichen abgegrenzt. Das Arbeitsgebiet wird im wesentlichen durch ein Gerüst von verwendeten Schlüsseln und verwendeten Werten unter Einbeziehung der zeitlichen Dimension definiert und für eine oder mehrere Fachabteilungen eingerichtet.
Im Arbeitsgebiet wird beschrieben, welche Informationen in welchem Umfang gespeichert werden (sollen).
2.6 Verwendete Schlüssel im Arbeitsgebiet
Die Festlegung von Schlüsseln erfolgt arbeitsgebietsübergreifend. Wenn Sie auf einen bestimmten Schlüssel in einem Arbeitsgebiet für die Speicherung von Daten oder für eine Statistik-Auswertung Bezug nehmen wollen, legen Sie dieses in der Arbeitsgebietsdefinition fest. Das heißt im ASS-Sprachgebrauch: "Dieser Schlüssel wird im betreffenden Arbeitsgebiet verwendet."
Wenn Sie einen Schlüssel in mehreren Arbeitsgebieten verwenden, so kann es vorkommen, dass sich die Mengen der im jeweiligen Arbeitsgebiet zulässigen Schlüsselausprägungen unterscheiden. Deswegen kann für jedes Arbeitsgebiet festgelegt werden, welche der Schlüsselausprägungen des betreffenden Schlüssels im Arbeitsgebiet zulässig sein soll (sogenannter Schlüsselausschluss im Arbeitsgebiet).
2.7 Verdichtungsstufe
Die Datei, die nach Schlüssel und Zeiträumen unterteilt
die Werte für die Auswertung enthält, wird Summendatenbank
genannt und zerfällt in verschiedene Verdichtungsstufen.
Eine Festlegung, die zu jedem in einem Arbeitsgebiet
verwendeten Schlüssel aussagt, ob er in der zugeordneten
Summendatenbank verdichtet oder ausgeprägt gespeichert
werden soll, heißt Verdichtungsstufe.
Zu jeder Verdichtungsstufe muss noch gesagt werden, welche
Werte in ihr gepflegt werden sollen (siehe 2.8).
Zu jedem Arbeitsgebiet können mehrere Verdichtungsstufen
festgelegt werden. Die Verdichtung in einer Verdichtungsstufe
besteht darin, dass die Werte bezüglich der verdichteten
Schlüssel zusammengefasst (aufsummiert) werden.
Wird in einer Verdichtungsstufe kein Schlüssel verdichtet,
spricht man in diesem wichtigen Sonderfall auch von einer
Verdichtungsstufe, nämlich von Basisverdichtungsstufe.
Bei jeder Auswertung sucht sich das ASS-System die geeigneten Verdichtungsstufen aus, die die volle Information für die Auswertung zur Verfügung stellen und mit einer möglichst geringen Anzahl von internen Operationen erreichen.
2.8 Verwendete Werte im Arbeitsgebiet
Sollen zu einem bestimmten Wert Zahlen in einer Verdichtungsstufe (siehe 2.7) eines Arbeitsgebiets (siehe 2.5) gespeichert werden, so heißt das, dieser Wert wird in der betreffenden Verdichtungsstufe und damit auch im Arbeitsgebiet verwendet.
2.9 Speicherungsart
Die Daten, die zu einer Verdichtungsstufe in der zugeordneten Summendatenbank gespeichert sind, können z. B. auf Magnetband ausgelagert sein. Mit der Speicherungsart wird zum Ausdruck gebracht, wo die Daten der betreffenden Verdichtungsstufe gespeichert sind und auf welchen Zeitraum sich diese Speicherung bezieht.
2.10 Anforderung
Der Sachbearbeiter teilt ASS mit, wie seine Auswertung (Liste) aussehen soll. Dies geschieht im Dialog durch die Dialoganwendung ST31 oder im Batch mittels einer eigenen, leicht erlernbaren Sprache (die sogenannte "Batch-Anforderungssprache"). Die Erstellung einer Liste wird als "Anforderung" bezeichnet.
Eine Anforderung legt genau fest, was in der Statistik-Liste in welcher Form erscheinen soll.
3 Allgemeiner Statistikaufbau
Für das Listbild sind die drei folgenden Begiffe von zentraler Bedeutung:
- KOPF
(Listenkopf, bestehend aus Überschriften, die nach den Bedürfnissen der Anwender gefüllt werden können, und weiteren Angaben (Arbeitsgebiet, Kopfschlüssel etc.) - ZEILE
(Listenzeile) - SPALTE
(Listenspalte)
Es ist in diesem Zusammenhang auch üblich, das die drei Dimensionen einer Liste (KOPF, ZEILE, SPALTE) zu nennen.
Folgendes Bild veranschaulicht vereinfacht die Situation:
KOPF
Zeilenüberschrift(en) ! Spalte 1 ! Spalte 2 ! ...
------------------------!----------!----------!----
! ! !
Zeile 1 ! XXX ! XXX ! ...
Zeile 2 ! XXX ! XXX ! ...
Zeile 3 ! XXX ! XXX ! ...
. ! . ! . ! .
. ! . ! . ! .
. ! . ! . ! .
Werteinhalte werden nur in Spalten dargestellt (gekennzeichnet durch "XXX"). Werteinhalte entstehen durch Lesen (und evtl. Aufkumulieren) von Informationen aus Summendatenbanken oder durch Rechenoperationen.
SCHLUESSEL in Zusammenhang mit Statistik und Anforderung
In Bezug auf Statistikbild und Anforderungssprache fasst der Begriff SCHLUESSEL folgende Begriffe zusammen:
Analog zum in 2.3 gebildeten Begriff Schlüssel, kann der hier gebildete, erweiterte Schlüsselbegriff ebenfalls Ausprägungen (Inhalte) annehmen. Die Inhalte, die ein Schlüssel annehmen kann, hängen vom Typ des Schlüssels ab:
- Die Inhalte von Schlüsseln im Sinne von 2.3
- sind Schlüsselausprägungen im Sinne von 2.4.
- Schlüsselformeln
- Die Inhalte von Werteschlüsseln sind:
- Wert im Sinne von 2.1
- Wert mit Zeitraumangabe
- Wert mit Schlüsselangabe
- Wert mit Schlüssel- und Zeitraumangabe
- Werteformeln
- Die Inhalte von Zeitraumschlüsseln sind:
- Zeitraumangaben
- Zeitraumformeln
Schlüsselinhalte können im KOPF, in der ZEILE und in den Spaltenüberschriften stehen. Auf welche Schlüssel sich eine in den SPALTEN dargestellte Zahl bezieht, geht aus ihrer Position innerhalb der Liste hervor.
Um zu wissen, auf welche Werte beziehungsweise Zeiträume sich die dargestellten Zahlen beziehen, muss es genau einmal den Schlüssel WERT geben. Ist beim Schlüssel WERT kein Zeitraum angegeben, so muss es auch genau einmal den Schlüssel ZEITRAUM geben.
Kopf-, Zeilen-, und Spaltenschlüssel sind beliebig (mit obiger Einschränkung) wählbar. Widersprüchliche Kombinationen oder nicht sinnvolle Kombinationen (z. B. der Schlüssel ORT als Kopf- und als Zeilenschlüssel) weist die Auswertung ab.
Den gesamten Leistungsumfang des Auswertsystems finden Sie im Benutzerhandbuch AUSWERTUNG. Dort befinden sich auch umfangreiche Erläuterungen, wie sich durch die Anordnung von Schlüsseln (einschließlich WERTE und ZEITRAUM) der Statistikaufbau nach den eigenen Wünschen gestalten lässt.
4 ASS-Funktionsumfang
Aus Sicht der Systemverwaltung/Systembetreuung besteht ein installiertes ASS-System zum einen aus Programmen, zum anderen aus Datenbeständen (Datenbanken), in welche Statistik-Information eingespielt beziehungsweise aus denen Statistikinformationen ausgelesen werden.
Die Datenbestände teilen sich in drei Gruppen:
- Normierte (Externe) Schnittstelle
Hier handelt es sich um einfache sequentielle Dateien, in die die ASS-Anwender ihre Informationen, die später ausgewertet werden sollen, einspielen.
- Parameterdatenbanken
In diesen Datenbanken wird eingetragen, welche Informationen im ASS-Statistik-System in welcher Form zu speichern sind. Diese Datenbanken steuern die Verarbeitung der ASS-Auswert- und ASS-UPDATE-Programme.
- Summendatenbanken
In den Parameterdatenbanken werden sogenannte Arbeitsgebiete eingerichtet. Ein Arbeitsgebiet ist für ASS die größte logische Einheit für Statistikdaten (auch gemeinsame Auswertungen über mehrere Arbeitsgebiete sind möglich).
Pro Arbeitsgebiet wird eine ASS-Statistik-Datenbank (auch Summendatenbank genannt) eingerichtet. Sie enthält alle Statistikdaten zu einem Arbeitsgebiet. Da bei Statistikproblemen im allgemeinen sehr große Datenmengen anfallen, haben wir für das ASS ein spezielles Verdichtungsverfahren angewendet, das ASS in die Lage versetzt, auch sehr große Datenmengen zu verarbeiten (siehe 6.4).
Alle Programme, die zu ASS gehören, sind so konzipiert,
dass sie nur installiert, aber nicht modifiziert werden
müssen. Alle zum Ablauf erforderlichen Parameter
werden aus den bereits genannten Parameterdatenbanken
gelesen.
Die Programmierung muss nur die Programme bereitstellen,
die aus vorhandenen Datenbeständen die ASS-Schnittstelle
versorgen.
Die ASS-Programme lassen sich in folgende Programmkomplexe gliedern:
- ONLINE-Verwaltung der Paramterdatenbanken
- Folgeeinspeicherung
- Auswertungen im Batch
- Dienstprogramme
- Listanforderung im Dialog
Je nach Installationsumfang kann auf einzelne Komplexe verzichtet werden. Unbedingt erforderlich sind jedoch die ersten drei der oben genannten Komplexe und ein Minimum an Dienstprogrammen.
Welche Programme und Datenbanken in welchem Komplex erforderlich sind, ist in den Handbüchern 'INSTALLATION' und 'BETRIEB' beschrieben.
Die von standardisierten Schnittstellen angelieferten Daten aus den operationalen Beständen werden von ASS in Summendatenbanken verwaltet. Die Auswertung der Summendatenbanken erfolgt wahlweise über eine Anforderungssprache, über den ASS-Dialog (menügesteuert) oder über eine universelle Auswertungs-Schnittstelle, die auch für eine Weiterverarbeitung am PC geeignet ist. Die wesentlichen Funktionen in ASS sind in der folgenden Übersicht aufgeführt.
Verwaltung der Summendatenbank
- Erstes Laden eines Arbeitsgebietes
- Einspeicherung von Bewegungsdaten im BATCH
- Einspeicherung von Vorgabewerten im DIALOG
- Anlegen neuer Verdichtungsstufen
- Löschen vorhandener Verdichtungsstufen
- Beliebige zeitliche Historie in der Summendatenbank
- Monatsarbeitsgebiete auf Folgesätze bzw. Tagesarbeitsgebiete umstellen
- Speicherung wahlweise auf Basis verschiedener Verdichtungsstufen
- Verdichtung der Summensätze zur Platzersparnis
- Erweiterung von Arbeitsgebieten um zusätzliche Werte
- Erweiterung von Arbeitsgebieten um zusätzliche Schlüssel
- Löschung von Werten im Arbeitsgebiet
- Löschung von Schlüsseln im Arbeitsgebiet
- temporäre Speicherung von Verdichtungsstufen (für einmalige Auswertung)
- Wahlweise Speicherung von Verdichtungsstufen auf sequentiellen Datenträgern (keine Auswertung im DIALOG möglich)
- Fehlerprüfung bei der Einspeicherung
- Statistik über die in ASS angeforderten Statistiken
- Protokollarbeitsgebiet
Auswertung der Summendatenbank
- Anforderung der Listauswertung über BATCH
Wollen Sie Auswertungen nur im BATCH erstellen, so gibt es für diesen Zweck eine ASS-Anforderungssprache. Mit dieser Sprache können Sie Listanforderungen formulieren. Diese Anforderungen liest dann ein BATCH- Programm ein, interpretiert sie und führt sie aus. Ergebnis ist eine Datei, die eine druckaufbereitete Liste enthält. Die Beschreibung dieser Anforderungssprache finden Sie im Benutzerhandbuch AUSWERTUNG.
- Anforderung Listauswertung über DIALOG
- Auswertungen im DIALOG
- Berechnungsformeln in der Auswertung
- Ermittlung prozentualer Anteile bezogen auf Zwischen-/Endsummen
- Übersetzung von Schlüsseln in Texte
- Unterschiedliche Gruppierung von Schlüsselinhalten
- Beliebige Zwischensummenbildung (einschließlich der Textierung von Zwischensummenzeilen)
- Variabler Listkopf
- Variable Listaufbereitung
- Variable Werteaufbereitung
- USER-EXIT bei der Auswertung
- Parametersprache für die Listanforderung
- Zeitreihenuntersuchungen
- gemeinsame Auswertung mehrerer Arbeitsgebiete
- Abruf häufig wiederkehrender Statistiken aus der Parameter-DB
- Erstellung sequentieller Datenträger aus der Summendatenbank (Diskette, Band)
- Online-Dialog zur Pflege der Security (Zugriffsberechtigung)
- Auswahl von verschiedenen Druckerklassen bei der Batch-Auswertung
Systemtechnik
- Anlegen von Steuerungsparametern (im DIALOG)
- Ändern von Steuerungsparametern (im DIALOG)
- Anlegen von Schlüsseltabellen (im DIALOG)
- Ändern von Schlüsseltabellen (im DIALOG)
- Übersicht über die Steuerungsparameter und Schlüsseltabellen erstellen
- Übersicht über die Anforderungsdatenbank erstellen
- Sicherung gegen Handhabungsfehler (Doppellauf, falsche Version)
- Dienstprogramme zur Verwaltung der Anforderungsdatenbank
5 Die externe Schnittstelle
ASS ist ein in sich abgeschlossenes System. Es übernimmt Daten aus anderen Verfahren nur über die Externe Schnittstellendatei.
Die externe Schnittstelle ist also die zentrale Schnittstelle von ASS-fremden Datenbeständen zu ASS. Alle Statistikdaten, die in ASS-Summendatenbanken gespeichert und maschinell zur Verfügung gestellt werden können, müssen in externen Schnittstellendateien bereitgestellt werden, von wo aus sie im Rahmen der Folgeeinspeicherung in ASS-Summendatenbanken übernommen werden. Von der Externen Schnittstelle an übernimmt ASS in vollem Umfang die Verarbeitung der Daten.
Jede Schnittstellendatei beginnt mit einem Kopfsatz und endet mit einem Endesatz.
Eine Schnittstellendatei kann sich über mehrere Dateien erstrecken (Datei-Splitting). Nur die letzte Datei einer Schnittstellendatei wird mit einem Endesatz abgeschlossen. Zwischen Kopf- und Endesatz befinden sich die Summensätze. Alle Sätze der Externen Schnittstelle besitzen einen festen Anfangsteil, der Satzart, Ordnungsbegriff usw. enthält. Kopf- und Summensatz enthalten zusätzlich Schlüssel- und Wertetabelle, während der Endesatz noch die Anzahl der Summensätze (vom letzten Kopfsatz an gezählt) angibt.
Die Anlieferung von Sätzen in der Externen Schnittstellendatei kennt folgende Formate:
- langes Format
- kurzes Format
- Text - Format
in Kombination mit den beiden Möglichkeiten
- "ungeshrinkt"
- "geshrinkt" (möglich, sofern Software-Fremdprodukt EXPAND zur Verfügung steht)
In externen Schnittstellen werden Zeiten beim Wert i. a. in der Form JJMM angeliefert (s.u.). Es können jedoch auch Zeiten in der Form JJMMTT (z.B. für Tages-Arbeitsgebiete) angeliefert werden. In diesem Fall gilt für alle unten beschriebenen Satzformate von externen Schnittstellen (kurzes bzw. langes Schnittstellenformat):
- Die Satzarten von Kopf- bzw. Summensätzen sind um 20 zu vergrößern, um die Existenz des Tages anzukündigen.
- Statt 4-stelliger Zeitangaben sind beim Wert stets 6-stellige Zeitangaben der Form JJMMTT anzuliefern.
Eine Schnittstellendatei darf nur ein Datumsformat enthalten (entweder die Form JJMM oder die Form JJMMTT).
5.1 Das lange Schnittstellenformat
Der nachfolgende Teil dieses 5. Kapitels, der den physikalischen Aufbau der externen Schnittstelle beschreibt kann beim ersten Lesen übersprungen werden.
Schnittstellendateien sind sequentielle Dateien variabler Satzlänge.
Jede Schnittstellendatei beginnt mit einem Kopfsatz (Satzart = H'0000' bzw. H '0002' bzw. H'0004') und endet mit einem Endesatz (Satzart = H'0099').
Zwischen Kopf- und Endesatz befinden sich die Summensätze. Eine Schnittstellendatei kann sich über mehrere Dateien erstrecken (Datei-Splitting). Nur die letzte Datei einer Schnittstellendatei enthält einen Endesatz. Jede Datei kann mit einem Kopfsatz beginnen - muss aber nicht. Enthält bei Datei-Splitting eine Schnittstellendatei mehrere Kopfsätze, so müssen die Inhalte dieser Kopfsätze identisch sein.
Kopf- und Summensätze haben den gleichen Aufbau (siehe unten). Jeder Satz beschreibt seinen Aufbau. Der Variable Teil 'TAB' enthält am Anfang soviele Schlüsseleinträge (Schlüsselnummer und Schlüsselinhalt), wie in 'SCHL_ZAHL' angegeben ist. Dahinter folgen soviele Werteeinträge (Wertenummer, Werteinhalt, Wertedatum), wie in 'WERTE_ZAHL' angegeben ist.
Der Kopfsatz gibt an, welche Information in den folgenden Summensätzen zu erwarten ist (Schlüsselnummer, Wertenummer, Wertedatum). Wird ein Wert als Bewegung angeliefert und gibt es zu diesem Wert mehrere Zeiträume in der betreffenden Schnittstellendatei, so reicht es aus, im Kopfsatz den kleinsten möglichen und den größten möglichen Zeitraum anzukündigen. Die Felder für Schlüsselinhalt und Werteinhalt müssen gelöscht sein (Ausnahme Satzart H'0004', siehe unten).
In den Summensätzen müssen alle Felder für Schlüssel- und Werteeinträge belegt sein.
ANMERKUNG:
In der nachfolgenden Beschreibung wird oft Assembler-Notation benutzt. Beispielsweise bedeutet H'0004'
- in COBOL : PIC S9(4) COMP VALUE +4
- in PLI : BIN FIXED(15) INIT(4)
Enthält eine Schnittstelle Werte vom Typ BEWEGUNG, die in einer Summendatenbank als BESTAND gespeichert werden, so sind LADEN und FORTSCHREIBEN zu unterscheiden. Vor der Fortschreibung ist ein Ladelauf erforderlich, in dem die oben genannten Werte als Bestandswerte angeliefert werden (Einzelheiten hierzu siehe weiter unten).
Bei der Satzart H'0004' wird im Kopfsatz angegeben, in welcher Form die Werte in den Summensätzen angeliefert werden, und zwar wird dies im Werteinhalt ausgedrückt:
- WERTEINHALT = 0 :
Der betreffende Wert wird in den nachfolgenden Summensätzen als BESTAND angeliefert. - WERTEINHALT = 1 :
Der betreffende Wert wird in den nachfolgenden Summensätzen als BEWEGUNG angeliefert.
Werte mit der Werteart '1' (BEWEGUNG) dürfen nur als BEWEGUNG angeliefert werden, Werte mit der Werteart '0' (BESTAND) müssen bei der Ersteinspeicherung als BESTAND angeliefert werden (LADEN) und können anschließend über Bewegungen fortgeschrieben werden (FORTSCHREIBEN) oder immer wieder als BESTAND angeliefert werden. Diese Regelung gilt auch für Vorgabewerte, wenn diese im BATCH eingespeichert werden.
Es gibt unterschiedliche Satzarten für Kopfsätze, die im Laufe der Entwicklung von ASS nacheinander entstanden. Aus Kompatibilitätsgründen bleiben diese Kopfsatzarten weiterhin gültig. Bei Programmierung von neuen Schnittstellen empfehlen wir Ihnen, nur noch die neueste Satzart H'0004' zu benutzen, weil sich dann die Schnittstelle selber beschreibt und weil Sie dann unabhängig von der manuellen Pflege der Parameterdatenbanken sind. Bei den eigentlichen Summensatzarten verhält es sich ähnlich. Künftig sollten hier nur noch die Satzarten '0005' bzw. '0015' Anwendung finden.
Anmerkung zum SHRINK:
Das im folgenden gelegentlich angesprochene Softwareprodukt
SHRINK ist Fremdsoftware. Sollte im Rechenzentrum SHRINK nicht
zur Verfügung stehen, so erübrigen sich die zu diesem Thema
gemachten Aussagen.
Bitte beachten Sie
- Werte sind chronologisch aufsteigend anzuliefern. Bei Werten, die als BEWEGUNG angeliefert werden, können Sie die Chronologie-Bedingung durch eine Verarbeitungsoption in der Folgeeinspeicherung ausschalten (Option 'MAXDATGLEICH' oder 'NMAXDAT').
- In einem Lauf der Folgeeinspeicherung können mehrere Schnittstellendateien für ein Arbeitsgebiet verarbeitet werden (Dateiverkettung, nur bei IBM).
- Eine Schnittstellendatei, die in ein bestimmtes Arbeitsgebiet einfliessen soll, muss mindestens einen Wert enthalten, der im betreffenden Arbeitsgebiet verwendet wird.
- Ein Wert mit derselben Wertenummer und demselben Wertedatum darf in einem Schnittstellensatz höchstens einmal vorkommen.
- Eine Schnittstellendatei, die in ein bestimmtes Arbeitsgebiet
einfliessen soll, muss alle verwendeten Schlüssel der
betroffenen Verdichtungsstufen enthalten mit folgender
Ausnahme:
Ist ein Schlüssel (z. B. KREIS) einem anderen (z. B. ORT) hierarchisch übergeordnet und werden die Ausprägungen des untergeordneten Schlüssels (ORT) gegen die Schlüsseldatenbank geprüft (KEPRKZ = '0'), so braucht der übergeordnete Schlüssel (KREIS) nicht in der Schnittstellendatei enthalten zu sein, er wird in der Folgeeinspeicherung automatisch ergänzt, falls die folgende Bedingung erfüllt ist:
Zu jeder Ausprägung des untergeordneten Schlüssels darf es einen Eintrag und somit nur eine Zuordnung zu einer übergeordneten Ausprägung in der Schlüsseldatenbank geben. Einzelheiten hierzu sind im Handbuch "Einrichten Arbeitsgebiet im Dialog" beschrieben.
Beispiel
! Verwendete Schlüssel !
! im Arbeitsgebiet !
Verdichtungsstufe ! ! Verwendete Werte
! S_1 S_2 S_3 S_4 !
-------------------------------------------------------------
! !
1 ! + + + + ! W_1
! !
2 ! + + ! W_1 W_2
! !
3 ! + + ! W_2 W_3
Werden nun im Kopfsatz die Werte W_2 und W_3 angekündigt, so sind für die Einspeicherung nur die Verdichtungsstufen 2 und 3 betroffen. Also brauchen im Kopfsatz und damit auch in den Summensätzen nur die Schlüssel S_1, S_2 und S_3 angeliefert werden.
Es sei nun der Schlüssel S_1 hierarchisch dem Schlüssel S_2 untergeordnet. Werden die Ausprägungen von S_1 nicht gegen die Schlüsseldatenbank geprüft (KEPRKZ gleich '1' oder '2'), so muss der Schlüssel S_2 unbedingt angeliefert werden. Wenn dagegen die Ausprägungen von S_1 gegen die Schlüsseldatenbank geprüft werden (KEPRKZ gleich '0'), so ist die Anlieferung von S_2 freigestellt. Bei dieser Betrachtung ist es unerheblich, ob die Ausprägungen von S_2 gegen die Schlüsseldatenbank geprüft werden oder nicht. Diese Aussagen gelten nur, wenn keine Ausprägungsduplikate vorkommen (siehe oben).
HINWEIS: Alle verwendeten Schlüssel des Arbeitsgebiets können angeliefert werden. Darüber hinaus können sogar Schlüssel angeliefert werden, die nicht im Arbeitsgebiet zu den verwendeten Schlüsseln zählen. Wichtig ist nur, dass sämtliche im Kopfsatz angekündigten Schlüssel auch in jedem Summensatz enthalten sind.
Die Behandlung zeitabhängiger Schlüssel in der Schnittstelle
Bei der Folgeeinspeicherung können Sie grundsätzlich mit und ohne Berücksichtigung des Zeitaspekts bei Schlüsselinhalten arbeiten. Standardmäßig ist die Zeitprüfung ausgeschaltet. Wenn Sie mit dieser Einstellung eine Einspeicherung vornehmen, so geht ASS davon aus, dass alle Schlüsselausprägungen in der Schlüsseldatenbank unbegrenzt gültig sind, ohne Rücksicht auf das mit der Schlüsselausprägung gespeicherte Gültigkeitsintervall.
Wird dagegen mit aktivierter Zeitprüfung eingespeichert, so wird bei der Verarbeitung nicht nur das Vorhandensein der betreffenden Ausprägungen, sondern auch ihre zeitliche Gültigkeit berücksichtigt. Beim Versuch zu einer Ausprägung, deren Gültigkeit abgelaufen ist, Werte anzuliefern, verweigert das System die Annahme dieser Werte.
Werden in der Schnittstelle Ausprägungen einer Schlüsselhierarchie angesprochen, so wird nicht nur die Gültigkeit der einzelnen Ausprägungen für sich, sondern auch die zeitliche Validität der mitangesprochenen Ausprägungsbeziehungen geprüft.
ACHTUNG:
Bestehen zu einer Ausprägung Duplikate, d.h. die Ausprägung geht mehrere, in der Regel zeitlich verschiedene Beziehungen zu übergeordneten Ausprägungen ein, so müssen in der Schnittstelle sämtliche Ausprägungen mitangeliefert werden. Eine automatische Ergänzung der übergeordneten Ausprägungen durch ASS ist dann nicht mehr möglich.
Zulässige Kombinationen von Satzarten
| Satzart im Kopfsatz |
Zulässige Satzart im Summensatz |
|---|---|
| 0 | 1 , 11 |
| 2 | 3 , 13 |
| 4 | 5 , 15 |
Es folgen die Satzaufbauten im Detail:
Die Längenangaben verstehen sich, wenn nichts anderes gesagt
ist, in Bytes. Eine Bemerkung zum Format:
| Format | Assembler | COBOL | PLI |
|---|---|---|---|
| H | H | PIC S9(4) COMP | BIN FIXED(15) |
| F | F | PIC S9(9) COMP | BIN FIXED(31) |
| CH | CLn | PIC X(n) | CHAR (n) |
Beschreibung der für alle Satzarten gleichen Anfangselemente
| Name | Länge | Format | Beschreibung |
|---|---|---|---|
| Satzlänge | 4 | Das übliche Satzlängenfeld (Achtung: hier ist das Satzlängenfeld gemeint, das vom Betriebssystem benutzt wird. In COBOL hat man hierauf im allgemeinen keinen Zugriff). | |
| SCHNITTST_NR | 2 | H | Nummer der Schnittstelle |
| EDATUM | 6 | CH | Erstellungsdatum JJMMTT |
| SATZ_ART | 2 | H | Satzart
H'0000': Kopfsatz Laden/Abgleich
H'0001': Summensatz Laden/Abgleich
H'0011': Summensatz Laden/Abgleich
Satz ist "geshrinkt"
H'0002': Kopfsatz Bestand/Bewegung
entsprechend Werte-Anlieferung
von der Wertedatebank
H'0003': Summensatz Bewegung
H'0013': Summensatz Bewegung
Satz ist "geshrinkt"
H'0004': Kopfsatz, Wertanlieferungsart
ist im Satz beschrieben
H'0005': Summensatz zu H'0004'
H'0015': Summensatz zu H'0004'
Satz ist "geshrinkt"
H'0099': Endesatz |
Es folgen nun - gesondert nach den einzelnen Satzarten - die übrigen, nicht für alle Satzarten identischen Bestandteile der Schnittstellensätze.
Restlicher Satzaufbau für Satzart H'0000', H'0002', H'0004'
| Name | Länge | Format | Beschreibung |
|---|---|---|---|
| ORD_BEGR | 30 | CH | Ordnungsbegriff im Ausgangsbestand Wird von ASS bei fehlerhaften Schnittstellensätzen im Protokoll angedruckt, dient somit der Fehlerermittlung. |
| SCHL_ZAHL | 2 | H | Anzahl Schlüssel in TAB |
| WERT_ZAHL | 2 | H | Anzahl Werte in TAB |
| TAB | VAR | Tabelle mit Schlüsseln und Werten SCHL_ZAHL gibt an, wieviele Schlüsseleinträge in TAB enthalten sind (Index läuft von 1 bis SCHL_ZAHL). WERT_ZAHL gibt an, wieviele Werteeinträge in TAB enthalten sind (Index läuft von SCHL_ZAHL + 1 bis SCHL_ZAHL + WERT_ZAHL). Jeder Tabelleneintrag ist 14 Byte lang, bei Werten mit der Zeit in der Form JJMMTT ist ein Werteeintrag 16 Byte lang.
Aufbau eines Schlüsseleintrags:
- Schlüsselnummer H
- Schlüsselinhalt 12 Byte CH
linksbündig
in Kopfsätzen auf
Blank gelöscht.
Aufbau eines Werteeintrags:
- Wertenummer H
- Werteinhalt 8 Byte gepackt
Bei Satzart H'0000' und H '0002'
gelöscht auf 0.
Bei Satzart H'0004'
0 : Betreffender Wert wird als
BESTAND angeliefert.
1 : Betreffender Wert wird als
BEWEGUNG angeliefert.
- Wertedatum 4 Byte CH Format JJMM
oder 6 Byte Format JJMMTT |
Restlicher Satzaufbau für Satzart H'0001', H'0003', H'0005'
| Name | Länge | Format | Beschreibung |
|---|---|---|---|
| ORD_BEGR | 30 | CH | Ordnungsbegriff im Ausgangsbestand Wird von ASS bei fehlerhaften Schnittstellensätzen im Protokoll angedruckt, dient somit der Fehlerermittlung. |
| SCHL_ZAHL | 2 | H | Anzahl Schlüssel in TAB |
| WERT_ZAHL | 2 | H | Anzahl Werte in TAB |
| TAB | Var | Tabelle mit Schlüsseln und Werten
analog zu Kopfsätzen
Jeder Tabelleneintrag ist 14 Byte lang
Aufbau eines Schlüsseleintrags:
- Schlüsselnummer H
- Schlüsselinhalt 12 BYTE CH
linksbündig
Aufbau eines Werteeintrags:
- Wertenummer H
- Werteinhalt 8 Byte gepackt
- Wertedatum 4 Byte CH Format JJMM
oder 6 Byte CH Format JJMMTT |
Restlicher Satzaufbau für Satzart H'0011, H'0013', H'0015'
Sätze der Satzart H'0011', H'0013', H'0015' sind wie Sätze der Satzart H'0001', H'0003', H'0005' aufgebaut, sie sind jedoch ab dem Feld "ORD_BEGR" einschließlich "geshrinkt" (siehe Hinweis weiter unten).
Restlicher Satzaufbaus für Satzart H'0098'
Sätze dieser Satzart werden bei der Schnittstellenverarbeitung überlesen.
| Name | Länge | Format | Beschreibung |
|---|---|---|---|
| ORD_BEGR | 30 | CH | Ordnungsgegriff im Ausgangsbestand Wird von ASS bei fehlerhaften Schnittstellensätzen im Protokoll angedruckt, dient somit der Fehlerermittlung. |
| SUMSAETZE | 4 | F | Anzahl der Summensätze von Anfang bis einschließlich dieser (Teil-) Datei |
Restlicher Satzaufbau für Satzart H'0099'
| Name | Länge | Format | Beschreibung |
|---|---|---|---|
| ORD_BEGR | 30 | CH | Ordnungsbegriff im Ausgangsbestand (für Fehlerhinweise) |
| SUMSAETZE | 4 | F | Anzahl der Summensätze in der Schnittstellendatei |
5.2 Das kurze Schnittstellenformat
Sollte der Platzbedarf einer externen Schnittstelle einmal zu groß werden, so gibt es auch die Möglichkeit, mit einer "kurzen" ASS-Schnittstelle zu arbeiten. Die kurze Schnittstelle wird verarbeitet, wenn Sie in der Vorlaufkarte von PCL1001 'EXIT=KURZ' angeben. Einzelheiten hierzu sind im Handbuch 'BETRIEB' beschrieben.
Struktur der "kurzen" ASS-Schnittstelle
Generell gilt:
Die Position der Felder Satzart und Schnittstellennummer wird für alle Satzarten vertauscht.
- Kopfsatz (Satzart = 0, Satzart = 2, Satzart = 4):
Kopfsätze werden in der "langen" Form verarbeitet, es werden jedoch einige Felder anders belegt:
- Ordnungsbegriff: Byte 29 und Byte 30:
Länge des Ordnungsbegriffs in den nachfolgenden Summensätzen H (HALBWORT). Zulässiger Inhalt:
0 <= Länge <= 30 - Schlüsselinhalt: Byte 1 und Byte 2:
Länge des Schlüsselinhaltes in den nachfolgenden Summensätzen H (HALBWORT). Zulässiger Inhalt:
1 <= Länge <= 12 Byte 3 bis Byte 12 gelöscht auf Blank.
- Ordnungsbegriff: Byte 29 und Byte 30:
- Summensatz (Satzart = 1, Satzart = 3 , Satzart = 5):
- Satzart : wie bisher
- Erstellungsdatum entfällt
- Schnittstellennummer entfällt
- Ordnungsbegriff : In der Länge, wie im Kopfsatz angekündigt (entfällt bei Länge 0).
- Anzahl-Schlüssel entfällt
- Anzahl-Werte :
- Byte Art der Wertetabelle binär
- Byte Anzahl Werte binär
- Schlüsselnummer entfällt
- Schlüsselinhalt jeweils in der Länge, wie im Kopfsatz angekündigt. Schlüsselinhalte müssen in der im Kopfsatz angekündigten Reihenfolge geliefert werden.
- Aufbau der Wertetabelle in Abhängigkeit
vom 1. Byte des Feldes Anzahl-Werte:
- X'00' : wie in der langen Form.
- X'10' : Wertenummer: H, nicht ausgerichtet
Inhalt : 8 Byte gepackt
Zeitraum : aus Kopfsatz, Zeitraum muss in der ganzen Schnittstelle konstant sein. Länge eines Tabelleneintrages: 10 Byte. - X'20' : Wertenummer : H, nicht ausgerichtet
Lth : Bit (08) Länge des nachfolgenden Werteinhaltes in Bytes.
Inhalt : Gepackt in der Länge von Lth,
Beispiel:
DEC FIXED(7) (PLI) bzw. PIC S9(7) COMP-3 (COBOL) entspricht der Länge 4.
Zeitraum : aus Kopfsatz, Zeitraum muss in der ganzen Schnittstelle konstant sein. Länge eines Tabelleneintrages 3 + Lth Byte.
ACHTUNG: In einem Summensatz dürfen maximal 255 Werteeinträge vorhanden sein.
- Summensatz geshrinkt (Satzart = 11, Satzart = 13, Satzart = 15):
Satz wird wie unter 2. aufgebaut. "geshrinkt" wird ab Ordnungsbegriff (einschließlich), im Prinzip wie bisher (siehe Hinweis weiter unten).
- Endesätze (Satzart = 98, Satzart = 99):
Wie bisher (jedoch wie bereits oben gesagt sind die Felder für Schnittstellennummer und Satzart vertauscht).
HINWEIS zum "Shrinken":
Es gibt einen kleinen Unterschied beim "Shrinken" der (Standard-)Schnittstelle und der "kurzen" Schnittstelle. Der "geshrinkte" Satz der (Standard-)Schnittstelle enthält nach der Satzart das vom "Shrink" gelieferte RDW (RECORD-DESCRIPTION-WORD).
Bei der "kurzen" Schnittstelle wird ab Ordnungsbegriff "geshrinkt".
Der Satzaufbau ist wie folgt:
RDW, Satzart, "geshrinkter" Teil des Summensatzes.
Beispiel für eine externe Schnittstelle, langes Format
1. Kopfsatz
8 7 1 0 0 2 G E N E R I E R T E
008400000011F8F7F1F0F0F20004C7C5D5C5D9C9C5D9E3C540
. . . .05 . . . .10 . . . .15 . . . .20 . . . .25
S C H N I T T S T E L L E _
E2C3C8D5C9E3E3E2E3C5D3D3C540404040404000020004076D
. . . .30 . . . .35 . . . .40 . . . .45 . . . .50
40404040404040404040404007964040404040404040404040
. . . .55 . . . .60 . . . .65 . . . .70 . . . .75
_ 8 6 0 1 >
40076D000000000000001CF8F6F0F1076E000000000000001C
. . . .80 . . . .85 . . . .90 . . . .95 . . . 100
8 6 0 1 ? 8 6 0 1
F8F6F0F1076F000000000000001CF8F6F0F107700000000000
. . . 105 . . . 110 . . . 115 . . . 120 . . . 125
8 6 0 1
00001CF8F6F0F1
. . . 130 . .
2. Summensatz
8 7 1 0 0 2 G E N E R I E R T E
008400000011F8F7F1F0F0F20005C7C5D5C5D9C9C5D9E3C540
. . . .05 . . . .10 . . . .15 . . . .20 . . . .25
S C H N I T T S T E L L E _
E2C3C8D5C9E3E3E2E3C5D3D3C540404040404000020004076D
. . . .30 . . . .35 . . . .40 . . . .45 . . . .50
1 1 1 1 1
F1F1404040404040404040400796F1F1F14040404040404040
. . . .55 . . . .60 . . . .65 . . . .70 . . . .75
_ 8 6 0 1 > <
40076D000000000000103CF8F6F0F1076E000000000000104C
. . . .80 . . . .85 . . . .90 . . . .95 . . . 100
8 6 0 1 ? * 8 6 0 1
F8F6F0F1076F000000000000105CF8F6F0F107700000000000
. . . 105 . . . 110 . . . 115 . . . 120 . . . 125
% 8 6 0 1
00106CF8F6F0F1
. . . 130 . .
3. Endesatz
8 7 1 0 0 2 G E N E R I E R T E
003000000011F8F7F1F0F0F20063C7C5D5C5D9C9C5D9E3C540
. . . .05 . . . .10 . . . .15 . . . .20 . . . .25
S C H N I T T S T E L L E
E2C3C8D5C9E3E3E2E3C5D3D3C540404040404000000001
. . . .30 . . . .35 . . . .40 . . . .45 . . .
 Anzahl Summensätze
Anzahl Summensätze
5.3 Textformat mit Line-Sequentiell
Die Vorteile des Textformates liegen einerseits in der Lesbarkeit der Schnittstelle, da sie mit einem einfachen Texteditor angezeigt, bearbeitet und erstellt werden kann.
Außerdem gibt es hier erweiterte Funktionen, da beim Textformat die strikte Längenbegrenzung für Schlüsselinhalte fehlt:
- Schlüsselrelationen können direkt versorgt werden, statt deren Teilschlüssel gesondert anzuliefern
- Indexschlüssel (und -relationen) können mit langen Texten beliefert werden
Wie bei anderen Formaten der externen Schnittstelle (ASSINxx für PCL1001) üblich, beginnt diese mit einem Kopfsatz und endet mit einem Endesatz. Dazwischen befinden sich die eigentlichen Daten auf 0 bis n Summensätze verteilt. Technisch können Kopfsatz, Summensätze und Endesatz auf verschiedenen Dateien abgespeichert sein, die durch die Angabe von ASSIN=n (n = 1,2,...,40) in der Vorlaufkarte zu PCL1001 konkateniert werden.
Beispiel:
Kopfsatz auf Datei ASSIN01
Summensätze auf Datei ASSIN02
Endesatz auf Datei ASSIN03
Durch Angabe von ASSIN = 3, werden diese Dateien hintereinander abgearbeitet.
Die einzelnen Sätze der externen Schnittstelle bestehen aus
verschiedenen Feldern. Einzelne Einträge werden dabei
durch ein Semikolon separiert. Dürfen die Inhalte zu
einzelnen Einträgen fehlen (siehe unten), so folgen
dementsprechend unter Umständen mehrere Semikola
aufeinander.
Soll statt des Semikolons der Tabulator verwendet werden,
so ist in der Vorlaufkarte von PCL1001 die Option TAB
anzugeben.
Mit Ausnahme bei Schlüsselinhalten werden
führende und nachfolgende Leerzeichen toleriert. Bei
Feldern, deren Inhalte Zahlenangaben sind, dürfen
Vorzeichenangaben vor oder hinter der Ziffernfolge stehen.
Fehlt das Vorzeichen, so gilt die Zahl als positiv. Aufbau
und Bedeutung der einzelnen Felder lehnen sich an die
kurze Schnittstelle an.
Die Werteinhalte haben kein Komma. Damit liefert man zum Beispiel
Euro in Cent an, falls der entsprechende Wert zwei Nachkommastellen
hat.
Die ASS-Zeit kann in der Form JJMM oder JJMMTT angeliefert
werden. Das Format muss jedoch in einer Schnittstellendatei
einheitlich sein.
Aufbau Kopfsatz
Das erste Feld im Kopfsatz ist der Ordnungsbegriff. Dieser
muss mit "KOPFSATZ" beginnen, kann danach aber noch Zeichen
enthalten, die dann als eigentlicher Ordnungsbegriff im
Ablaufprotokoll bei den Kopfsatzinformationen angezeigt werden.
Dem Ordnungsbegriff folgt das Feld Erstelldatum mit dem
Aufbau JJMMTT, anschließend das Feld Nummer der
Schnittstelle (Arbeitsgebietsnummer). Die Inhalte dieser
beiden Felder können fehlen. In diesem Fall ist in der
Vorlaufkarte von PCL1001 eine Angabe zum Arbeitsgebiet
zu machen.
Es folgen die Felder 'Anzahl Schlüsseleinträge' und
'Anzahl Werteeinträge'.
Danach kommen so viele Schlüsselnummern, wie in Anzahl
Schlüsseleinträge angekündigt werden. Hierbei kann es sich
auch um Relationsnummern handeln, diesen muss allerdings ein
"R" vorangestellt werden (z.B. "R123"). Nummern von
Indexschlüsseln bzw. -relationen können außerdem mit einem
"I" bzw. "J" versehen werden (z.B. "I234" bzw. "J345"), um
festzulegen, dass für sie keine Langtexte, sondern normale
Schlüsselinhalte (Indizes) angeliefert werden.
Abschließend folgen die Werteeinträge. Jeder Werteeintrag besteht dabei aus einem Triple aus Wertenummer, Anlieferungsart (0 entspricht Bestandsanlieferung, 1 entspricht Bewegungsanlieferung) und Wertedatum (in der Form JJMM oder JJMMTT). Analog zur kurzen Schnittstelle müssen im Kopfsatz nur minimales und maximales Wertedatum der in den Summensätzen vorkommenden Werte angekündigt werden. Wird nur genau ein Zeitaspekt eingespeichert, so existiert zu dem betreffenden Wert nur ein Werteeintrag.
Formaler Aufbau
Ordnungsbegriff;
Erstelldatum;
Nummer der Schnittstelle;
Anzahl Schlüsseleinträge;
Anzahl Werteeinträge;
Schlüsselnummer Schlüssel 1;
.
.
.
Schlüsselnummer Schlüssel n; (mit n='Anz. Schlüsseleinträge')
Wertenummer Wert 1;
Anlieferungsart Wert 1;
Wertedatum Wert 1;
.
.
.
Wertenummer Wert m; (mit m='Anzahl Werteeinträge')
Anlieferungsart Wert m;
Wertedatum Wert m
Beispiel
KOPFSATZ;000421;3;2;4;4711;4712;5711;1;0001;5711;1;
0004;5712;1;0004;5713;1;0001
Aufbau Summensatz
Jeder Summensatz beginnt mit einem Ordnungsbegriff,
dessen Inhalt fehlen darf. Es folgen die Schlüsselinhalte zu
den im Kopfsatz angekündigten Schlüsselnummern. Dabei
müssen Anzahl und Reihenfolge mit dem Kopfsatz
harmonieren.
Bei einer Relation sind die zusammengesetzten Inhalte
anzuliefern. Sie werden dann programmintern anhand der
externen Längen der Teilschlüssel der Relation "zerlegt"
und diese damit versorgt.
Bei Indexschlüsseln/-relationen sind die zu indizierenden
Texte anzuliefern, es sei denn, sie wurden im Kopfsatz
mit "I" oder "J" markiert (s.o.).
Anschließend folgt eine beliebige Anzahl Werteeinträge,
wobei analog zum Kopfsatz jeder Werteeintrag aus einem
Tripel von Feldern besteht: Wertenummer, Werteinhalt,
Wertedatum. Jede Wertenummer / -datum-Kombination
muss durch den Kopfsatz angekündigt werden, wobei dort
pro Wert die Angabe von minimalem und maximalem Datum
genügt (siehe Kopfsatz).
Beispiel (entsprechend Beispiel für Kopfsatz):
;Nord;Detmold;5711;+1000;0001;5713;-112;0004
Summensatz;Sued;Muenchen;5711;8000+;0004;5712;1234-
;0004;5713;112;0004
Bemerkung: Der Begriff 'Summensatz' in obigem Beispiel ist ein Beispiel für einen Ordnungsbegriff.
Achtung: Bei Schlüsselinhalten sind führende Leerzeichen zu beachten. Die Inhalte 'Nord' und ' Nord' sind im ASS verschieden.
Aufbau Endesatz
Der Endesatz besteht nur aus einem Ordnungsbegriff mit dem fixen Inhalt ENDESATZ.
Beispiel:
ENDESATZ
Sonderprüfung bei Relationen
Wird eine angelieferte Schlüsselrelation tatsächlich zum Einspeichern eines bestimmten Wertes gebraucht, erfolgt eine zusätzliche Prüfung: Der Wert muss in mindestens einer Verdichtungsstufe vorkommen, in der alle Teilschlüssel der Relation ausgeprägt sind. Somit ist gewährleistet, dass der Wert nach Einspeicherung auch bzgl. der Relation auswertbar ist.
5.4 Allgemeine Bemerkungen zur Folgeeinspeicherung
Streng genommen muss zwischen Erst- und Folgeeinspeicherung unterschieden werden. Die Ersteinspeicherung eines Arbeitsgebietes ist die allererste Übernahme von Daten aus der externen Schnittstelle in eine ASS-Summendatenbank.
Sie hat besondere Bedeutung. In der Ersteinspeicherung wird das kleinste Datum festgelegt, zu dem Summendaten existieren dürfen. Dieses Datum wird in der Steuerungsdatenbank unter Datum 1. Einspeicherung festgehalten. Die Zeiträume aller späteren Einspeicherungen müssen größer oder gleich dem Datum der 1. Einspeicherung sein. Der Grund hierfür ist folgender: Um Platz in der Summendatenbank zu sparen, speichert ASS Zeiträume nicht in Datumsform (z. B. JJMM), sondern von Null beginnend durchgezählt. Der Monat der ersten Einspeicherung erhält Null, der nächste Monat 1 usw. Eine Änderung ist nur möglich, wenn man wieder ganz von vorne beginnt und alle Erst- und Folgeeinspeicherungen wiederholt.
Schnittstellendateien, die die ASS-Zeit in der Form JJMMTT anliefern, können in Arbeitsgebiete auf Monatsbasis eingespeichert werden, wobei dann über den Tag verdichtet wird (Addition der verschiedenen Tage eines Monats).
Schnittstellendateien, die die ASS-Zeit in der Form JJMM anliefern, können in Arbeitsgebiete auf Tagesbasis nicht eingespeichert werden.
Die Behandlung von BEWEGUNGswerten
Bewegungswerte können nur als Bewegung angeliefert werden. Die Zahlen aus der Schnittstelle werden unter dem in der Schnittstelle angegeben Zeitaspekt in der Summendatenbank abgelegt, evtl. auch aufaddiert. Nullen werden nicht gespeichert. Sie können Bewegungen auch noch nachträglich für bereits eingespeicherte Zeiträume nachliefern (ergänzen).
Die Behandlung von BESTANDswerten
Die Behandlung von Bestandswerten ist etwas schwieriger als die von Bewegungen. Ein Bestandswert gilt immer stichtagsbezogen. Einen neuen Stichtagsbestand erhalten Sie, wenn Sie einen alten Stichtagsbestand haben und die Änderungen, die sich bis zum neuen Stichtag ergeben haben, in der Schnittstelle anliefern.
Man nennt dies Fortschreiben von Beständen. Offensichtlich braucht die Bestandsfortschreibung einen "alten" Bestand. Das bedeutet für die Ersteinspeicherung von Bestandswerten, dass sie in der Form von Beständen angeliefert werden müssen (eine sogenannte Bestandsübernahme).
Beispiel:
Sie führen für den Januar 2000 eine Bestandsübernahme durch. Den Bestand für Februar erhalten Sie, wenn Sie die Änderungen, die im Laufe des Februars angefallen sind, in Form von Bewegungen anliefern. Technisch ist jedoch auch eine komplette Bestandsübernahme für den Februar möglich. Mischformen sind ebenso zulässig, etwa immer eine Bestandsübernahme im Januar, eine Fortschreibung durch Bewegungen für die restlichen Monate des Jahres, dann wieder Bestandsübernahme für den Januar des Folgejahres (weil eventuell die Befürchtung besteht, dass bei der Fortschreibung durch Bewegungen nicht garantiert werden kann, dass in der Schnittstelle immer alle Bewegungen richtig angeliefert werden können).
Wird die Kopf-Satzart 4 verwendet, so können Bestandswerte bei der ersten Einspeicherung von Summendaten in ein Arbeitsgebiet auch als Bewegung angeliefert werden. In diesem Fall wird ein "alter" Bestand (der eigentlich noch nicht existiert), der überall 0 ist, durch die Bewegungsanlieferung fortgeschrieben.
HINWEIS: Die Fortschreibung eines Bestandes in der Folgeeinspeicherung ist im allgemeinen deutlich billiger als eine regelmäßige Bestandsübernahme, weil die externe Schnittstelle bei Bewegungsfortschreibung in der Regel deutlich kleiner als der Gesamtbestand ist.
ANMERKUNG: Angenommen, dass ein Bestandswert bereits für ein ganzes Jahr, also von Januar bis Dezember eingespeichert ist. Jetzt wird eine Bewegung für April geliefert. Diese Bewegung wird als "vergessene" Bewegung interpretiert und in die Bestandszahlen der Monate April bis Dezember eingearbeitet. Die Bewegung habe den numerischen Inhalt 1. Dies erhöht dann den Bestand für April, Mai, ... , Dezember um 1. Will man jedoch erreichen, das sich nur der Bestand für April um 1 erhöht, so muss für Mai eine Bewegung mit -1 angeliefert werden. Dies saldiert sich dann für die Monate Mai, Juni, ... , Dezember zu 0.
6 Datenbankbeschreibungen
Es folgt die Beschreibung der ASS-Datenbanken - jedoch nur die logische Struktur. Die physikalische Struktur ist abhängig vom DB-Träger-System (DLI, ADABAS, ISAM, UDS). Sie ist Gegenstand einer individuellen Installation (vgl. Handbuch INSTALLATION).
Die Datenbanken Wertedatenbank, Schlüsseldatenbank und Steuerungsdatenbank sind Parameterdatenbanken. Ein immenser Vorteil der Speicherung in den Parameterdatenbanken besteht darin, dass Schlüssel und Werte zentral gespeichert und gepflegt werden (können) und somit Redundanzen vermieden werden.
6.1 Wertedatenbank

Beim Speichern eines Wertes in die Wertedatenbank legt ASS einen Satz (Segment) vom Typ SST001WE an.
Wird ein Wert in einem Arbeitsgebiet verwendet, so wird ein Satz (Segment) vom Typ SST002WA angelegt, der dem betreffenden Wert untergeordnet ist.
6.2 Schlüsseldatenbank
Die Schlüsseldatenbank hat folgende logische (hierarchische) Struktur:
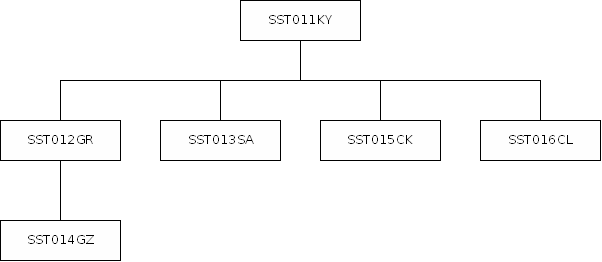
ASS legt für jeden Schlüssel, der in der Schlüsseldatenbank gespeichert wird, einen Satz (Segment) vom Typ SST011KY ab. Für jede Gruppierung eines Schlüssels wird ein Satz (Segment) vom Typ SST012GR gespeichert, der dem betreffenden SST011KY untergeordnet ist. Die Gruppenzugehörigkeiten, die ja eigentlich erst eine Gruppierung ausmachen, werden in Sätzen (Segmenten) vom TYP SST014GZ gespeichert. Für jede Gruppenzugehörigkeit wird ein Satz (Segment) vom Typ SST014GZ gespeichert und dem betreffenden SST012GR untergeordnet. Für jede Ausprägung eines Schlüssels, die in die Schlüsseldatenbank aufgenommen werden soll, wird ein Satz (Segment) vom Typ SST013SA gespeichert und dem betreffenden SST011KY untergeordnet.
In den Segmenten SST015CK und SST016CL legt ASS Schlüsselcaches an. In ihnen werden noch einmal die wichtigsten Informationen zu den Ausprägungen des übergeordneten Schlüssels aus SST011KY abgelegt. Dabei sind die Informationen noch einmal komprimiert worden. Außerdem werden in einem Segment mehrere Ausprägungen berücksichtigt.
SST015CK unterscheidet sich von SST016CL dadurch, dass in SST016CL mehr Informationen über die Ausprägungen enthalten sind als in SST015CK. Deswegen werden sie auch als kurzer und langer Schlüsselcache bezeichnet.
Ferner sind auf der Schlüsseldatenbank sogenannte Schlüsselrelationen abgespeichert (Beschreibung im Handbuch HST06 im Kapitel 6). Sie sind in den Segmenten SST017RE, SST018RA und SST019RV abgespeichert:
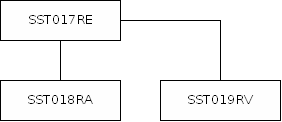
In SST017RE wird die Relation beschrieben: Hier stehen Relationsnummer, Relationsbezeichnung , Relationsabkürzung und Relationsart sowie die Schlüsselnummern der Schlüssel, auf die sich die Relation bezieht.
Die zur Relation gehörenden Kombinationen von Schlüsselinhalten dieser Schlüssel sind in Form ihrer internen Nummern in den Segmenten vom Typ SST018RA abgespeichert.
Schließlich bilden die Segmente SST019RV einen Verwendungsnachweis für die Relationen bzgl. der Schlüssel: Für jeden Schlüssel und jede Relation, in der der Schlüssel verwendet wird, legt ASS ein Segment ab.
6.3 Steuerungsdatenbank
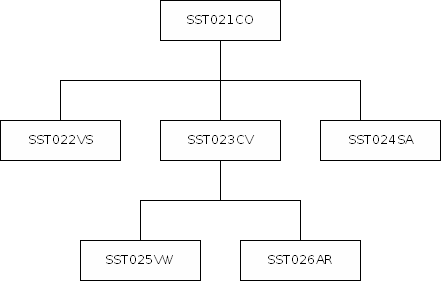
Die Steuerungsdatenbank hat folgende logische (hierarchische) Struktur:
Für jedes Arbeitsgebiet, das definiert wird, wird ein
Satz (Segment) vom Typ SST021CO gespeichert. Die ein
Arbeitsgebiet ergänzenden Beschreibungen werden in den
betreffenden, SST021CO untergeordneten Sätzen (Segmenten)
gespeichert.
Für jeden verwendeten Schlüssel speichert ASS einen Satz
(Segment) vom Typ SST022VS.
Für jede Verdichtungsstufe wird ein Satz (Segment) vom Typ SST023CV gespeichert. Für jeden in einer Verdichtungsstufe verwendeten Wert, wird ein Satz (Segment) vom Typ SST025VW gespeichert und dem betreffenden SST023CV untergeordnet.
Für jede dem System bekannte Speicherungsart wird ein Satz vom Typ SST026AR in der Steuerungsdatenbank abgelegt und der betreffenden Verdichtungsstufe SST023CV untergeordnet (z. B. ausgelagerte Zeiträume).
Gibt es in einem Arbeitsgebiet einen Schlüsselausschluss, d. h. in dem betreffenden Arbeitsgebiet sind nicht alle Ausprägungen eines bestimmten Schlüssels gültig, die in der Schlüsseldatenbank gespeichert sind, so wird für jeden Schlüssel, für den ein Schlüsselausschluss definiert wird, ein Satz (Segment) vom Typ SST024SA angelegt. Im betreffenden SST024SA werden dann die zugelassenen Ausprägungen aufgezählt.
Schlussbetrachtung zu Schlüsselausprägungen
ASS speichert alle gültigen Ausprägungen, die ein Schlüssel überhaupt annehmen kann (über alle Arbeitsgebiete) in der Schlüsseldatenbank (SST013SA). Die Menge der zulässigen Ausprägungen innerhalb eines Arbeitsgebiets ist dann eine Teilmenge aller möglichen Ausprägungen.
In der Steuerungsdatenbank wird gespeichert, welche Ausprägungen der Gesamtmenge in diesem Arbeitsgebiet gültig sind (SST024SA). Sollen alle Ausprägungen eines Schlüssels im betreffenden Arbeitsgebiet gültig sein, so dürfen für diesen Schlüssel keine Sätze SST024SA angelegt werden. Wenn es solche Angaben zu einem Schlüssel gibt, der hierarchisch untergeordnete Schlüssel hat, so sind implizit auch alle untergeordneten Ausprägungen im betreffenden Arbeitsgebiet gültig.
Werden nun mehrere Arbeitsgebiete zusammen betrachtet (z. B. eine Auswertung über mehrere Arbeitsgebiete gemeinsam), so sind die Ausprägungen eines Schlüssels gültig, die in mindestens einem der betrachteten Arbeitsgebiete gültig sind (Vereinigungsmenge). Es ergeben sich weiterhin Konsequenzen für die Folgeeinspeicherung, das Sichern von Arbeitsgebieten und außerdem für
Schlüsselgruppierungen :
Gibt es zu einer Schlüsselgruppierung eines Schlüssels ausgeschlossene Ausprägungen, so bleiben bei der Listerzeugung alle ausgeschlossenen Ausprägungen unberücksichtigt. Wurde eine Ausprägung unterdrückt, nach der eine Zwischensummenbildung gewünscht wurde, so entfällt zusätzlich diese Zwischensummenbildung.
6.4 Summendatenbanken

Die Menge der verwendeten Schlüssel eines Arbeitsgebiets legt die Struktur der Schlüsseltabelle der zugeordneten Summendatenbank fest. Die Menge der verwendeten Werte eines Arbeitsgebiets legt analog die Struktur der Wertetabelle der zugeordneten Summendatenbank fest.
Die Summendatenbanken sind ganz einfache Datenbanken mit nur einem Satztyp (Segmenttyp). Die Sätze haben einen festen und einen variablen Teil und sind somit insgesamt variabel lang. Die Sätze haben einen eindeutigen Schlüssel, mit dessen Hilfe ein Direktzugriff auf einen Summensatz möglich ist.
Pro Arbeitsgebiet wird eine Summendatenbank angelegt. Sie enthält stets einen Kopfsatz und n Summensätze.
Abhängig vom Arbeitsgebiet hat der Schlüssel folgenden Aufbau:
- Verdichtungsstufennummer BIN FIXED(15) (Halbwort)
- Schlüsseltabelle
Anzahl Elemente = Anzahl verwendeter Schlüssel des Arbeitsgebietes. - Wertetabelle
Anzahl Elemente = variabel, abhängig von in der Verdichtungsstufe verwendeten Werten und gespeicherten Zeiten.
Verdichtung auf Ebene der Schlüsselausprägungen:
Ein Summensatz einer Verdichtungsstufe wird nur dann physikalisch abgespeichert, wenn in der Wertetabelle mindestens ein Wert mit Werteinhalt ungleich Null existiert.
Verdichtung der Werte:
Es werden zwei Wertearten unterschieden, Bestandswerte und Bewegungswerte (vgl. Kap. 2.1). Bewegungen werden nur dann abgespeichert, wenn sie einen von Null verschiedenen Inhalt haben. Bestände werden erst ab dem Zeitpunkt gespeichert, wenn sie zum ersten Mal einen von Null verschiedenen Inhalt haben. Ein weiterer Bestandswert wird erst dann mit seinem neuen Inhalt abgelegt, wenn er sich zum zeitlich davorliegenden Inhalt geändert hat.
6.4.1 Interner Satzaufbau der Verdichtungsstufen
Jeder logische Satz einer Verdichtungsstufe besteht aus dem fixen
und variablen Teil. Der fixe Teil enthält die
Verdichtungsstufennummer und sämtliche verwendete Schlüssel des
Arbeitsgebiets. Der variable Teil enthält die Werte. Der fixe Teil
ist der primäre Schlüssel der Datenbank.
Der erste Satz ist der Kopfsatz mit der nicht möglichen
Verdichtungsstufennummer 0 und der restliche Teil des fixen Teils
ist low value. Der variable Teil hat den folgenden Aufbau:
EDATUM JJMMTT
ADATUM JJMMTT
AGNR Halbwort, Arbeitsgebietsnummer
CARVERS Halbwort, Versionsnummer
CSDAT JJMMTTHH, Versionsdatum
CELET1 JJMM, Datum der letzten Einspeicherung
Die folgenden Sätze sind die Summensätze. Die ersten zwei Bytes enthalten die Verdichtungsstufennummer als Halbwort und danach die Schlüssel. Ein Schlüsseleintrag belegt KEINL Bytes. Es werden dort die verdichteten Schlüsselinhalte (Zählnummern) gespeichert.
Normale Verdichtungsstufen
(weder Schlüsselreihenfolge noch -relation):
Die Schlüssel sind entsprechend Hierarchienummer und Hierarchiestufe
(verwendete Schlüssel) sortiert. Schlüssel, die in der
Verdichtungsstufe mit 1 gekennzeichnet sind, enthalten als
Inhalt konstant high value.
Gedrehte Verdichtungsstufen
(Verdichtungsstufen mit individueller Schlüsselreihenfolge):
Die verdichteten Schlüsselinhalte werden in der Reihenfolge
hinter der Verdichtungsstufennummer abgelegt, wie es in der
ST06 vorgegeben wurde. Der Rest des fixen Teiles wird mit
high value aufgefüllt.
Index-Verdichtungsstufen (Schlüsselrelation):
Hinter der Verdichtungsstufennummer werden die verdichteten
Schlüsselinhalte der maximal 10 angegebenen Schlüssel abgelegt
und zwar in der Reihenfolge, wie in der ST06 vorgegeben.
Der Rest des fixen Teiles wird mit high value aufgefüllt.
Normale Verdichtungsstufen und Schlüsselreihenfolgen enthalten immer den variablen Teil, während er bei Schlüsselrelationen immer leer ist.
Ein Werteeintrag ist vier bis elf Bytes lang. Das erste Byte
enthält die relative Wertenummer (CWNRRE), die nächsten 10 Bits
das relative Datum und die nächsten 6 Bits sind konstant
low value. Das Datum ist wie folgt kodiert: die niederwertigen
8 Bits gefolgt von den höherwertigen zwei Bits. Es werden die
Monate nach dem Datum der ersten Einspeicherung (CEERS1) gezählt,
beginnend mit 0. Bei Arbeitsgebieten auf Tagesbasis werden die
letzten 5 Bits des 2. Datumsbyte's genutzt. Es werden die
Tage von 1 bis 32 des betreffenden Monats abgelegt, und zwar
binär von 0 bis 31 (B'00000' bis B'11111').
Die ersten drei Bits des vierten Bytes geben die Anzahl
der folgenden Bytes an. Das nächste Bit ist das Vorzeichen
und der restliche Teil enthält den Inhalt im Zweierkomplement.
Die Werteeinträge sind sortiert nach Nummer und Datum (chronol.).
Es gibt einen Unterschied zwischen Bestands- und Bewegungswerten. Bewegungswerte werden nur gespeichert, wenn der zugehörige Werteinhalt ungleich 0 ist. Bestandswerte werden nur gespeichert, wenn sich der Werteinhalt zum zeitlich davorliegenden Inhalt verändert hat.
6.5 Bibliothek für Listanforderungen

Die Datenbank für Listanforderungen ist eine ganz einfache Datenbank mit nur einem Satztyp (Segmenttyp). Alle Sätze sind gleich lang.
Diese Datenbank enthält Listanforderungen und Formeln. Es gibt folgende Arten von Listanforderungen/Formeln, im folgenden auch Bibliotheken genannt:
- Sichergestellte Listanforderungen
- Listanforderungen für einmalige Auswertung
- Listanforderungen für periodische Auswertungen
- installationsabhängige Bibliotheken für periodische bzw. einmalige Auswertungen
- Formeln
- Wertegruppierungen
- Schlüsselgruppierungen
- Parameterfilter
- Umbuchungsanweisungen
Eine Listanforderung bzw. Formel wird als ein Bibliothekselement bezeichnet.
Jedes Bibliothekselement besteht aus einem Kopfsatz und n Folgesätzen. Der Kopfsatz enthält die allgemeinen Daten wie Erstelldatum, Datum letzte Ausführung usw. In den Folgesätzen werden die eigentlichen Listanforderungen in formatfreier Sprache abgelegt.
6.6 SPA-Datenbank

Die SPA-Datenbank ist eine reine Arbeitsdatenbank, die nur in IMS-Umgebung und UTM-Umgebung existiert.
Die Transaktion ST31 (Listanforderung) braucht je nach Dialogsituation einen vergleichsweise großen Datenbereich, wo die eine Listanforderung beschreibenden Daten oder die Daten einer ONLINE-Statistik zwischengespeichert werden. Hierfür wird die SPA-Datenbank benutzt (man kann sie sich vereinfacht als logische Fortsetzung der IMS-SPA oder des UTM-KB vorstellen).
Je nach Dialogsituation werden die erforderlichen Sätze (0 bis n Stück) zu Beginn eines Dialogschritts aus der SPA-Datenbank gelesen bzw. am Ende eines Dialogschrittes in die SPA-Datenbank geschrieben.
7 Analyse eines Arbeitsgebietes
7.1 Zielsetzung des Kapitels
Dieses Kapitel soll - ausgehend von den ASS-Grundbegriffen - Ansätze und Vorschläge aufzeigen, die dem ASS-Anwender auf der Suche nach dem für ihn richtigen Arbeitsgebiet und den dazu passenden Komponenten hilfreich sein können.
Ein großer Vorzug von ASS besteht darin, dass es dem Anwender bei der Gestaltung eines Arbeitsgebietes hinsichtlich des Volumens und der inhaltlichen Zusammensetzung der Daten enorme Freiheiten bietet. Diese Freiheiten müssen vom ASS-Anwender genutzt werden, um sein Arbeitsgebiet möglichst genau an die Gegebenheiten und Bedürfnisse seines Unternehmens anzupassen. Je exakter diese Abstimmung getroffen wird, desto erfolgreicher wird die Arbeit mit ASS. Daher kommt bei der Anlage eines Arbeitsgebietes der der eigentlichen Definition vorausgehenden Analysearbeit entscheidende Bedeutung zu. Wir können an dieser Stelle infolge der eben angesprochenen Gestaltungsmöglichkeiten und der erforderlichen Berücksichtigung der Situation des jeweiligen Anwenders kein Patentrezept geben.
Die im folgenden beschriebenen Wege zur Einrichtung eines Arbeitsgebietes können nur Entscheidungshilfen sein, die keinesfalls Anspruch auf Ausschließlichkeit oder Vollständigkeit erheben.
Die technische Seite, wie ein Arbeitsgebiet mittels Online-Dialog ST06 einzurichten ist, wird im Handbuch 'Einrichten eines Arbeitsgebietes' ausführlich beschrieben.
7.2 Komponenten des ASS-Konzepts
Aus der Analyse verschiedener Statistiken ergeben sich folgende
drei Faktoren, die in jeder statistischen Information anzutreffen
sind:
In jeder Statistik wird ein Zeitbezug ausgedrückt, um den
Zeitpunkt oder Zeitraum zu präzisieren, für den die
statistische Aussage Gültigkeit hat. Von wesentlichem Interesse
sind naheliegenderweise bei jeder statistischen Information die
wert-, mengen- oder größenbezogenen Daten. Schließlich
beinhalten Statistiken noch beliebig viele Selektions- oder
Gruppierungsbegriffe, über die eine Aufteilung beziehungsweise
Zusammenfassung der eben genannten numerischen Kategorien erzielt
wird. Ein kleines Beispiel soll dies verdeutlichen:
Beispiel
In der Geschäftsstelle Hannover waren im ersten Halbjahr 2000 70 Auszubildende beschäftigt, davon sind 30 weiblich.
Bei der Analyse der oben angesprochenen Faktoren ist unschwer der Zeitraum 'erstes Halbjahr 2000' zu erkennen. Etwas schwieriger ist die Einstufung unter die übrigen Faktoren. Die Zahlen 70 und 30 präzisieren Mengen, die mit dem Begriff ANZAHL AUSZUBILDENDER' überschreibbar sind. 70 ist die Gesamtzahl der Auszubildenden, 30 eine Auswahl aus der Gesamtzahl, die über den allgemeinen Begriff GESCHLECHT und dessen konkreten Inhalt WEIBLICH erzielt wird. Analog könnte man über den Begriff GESCHLECHT eine weitere Auswahl aus der Gesamtzahl von 70 treffen, wenn statt WEIBLICH jetzt der Inhalt MAENNLICH genommen wird. Es ergibt sich dann die Zahl männlicher Auszubildender in der Geschäftsstelle Hannover im ersten Halbjahr 2000. Zielt man nur auf die Gesamtzahl aller Auszubildender ab, so wird der Selektionsbegriff GESCHLECHT einfach aus der statistischen Anforderung herausgenommen. Am Datenbestand und somit an der numerischen Größe ANZAHL AUSZUBILDENDER ändert diese Maßnahme nichts. Es sind weiterhin 30 weibliche und 40 männliche Auszubildende. Diese Zahlen können aus den vorhandenen Daten durch die Aufnahme des Selektionsbegriffes GESCHLECHT und die Inhalte MAENNLICH und WEIBLICH jederzeit geliefert werden.
Nur der von der Statistik betrachtete Ausschnitt hat sich geändert. Der nun fehlende Begriff GESCHLECHT führt zu einer Zusammenfassung. Betrachten wir dieses kleine Statistik-Beispiel aus der Warte der Unternehmensleitung, die auch mit Personalfragen der Geschäftsstellen München und Hamburg konfrontiert ist, so ist leicht vorstellbar, dass die bisher gezeigte statistische Auswertung auf Geschäftsstellenebene nicht ausreicht.
Der verantwortliche Personalfachmann möchte vielleicht zusätzlich erfahren, wieviele Auszubildende das Unternehmen insgesamt hat, und wieviele davon weiblichen oder männlichen Geschlechts sind. Es muss also noch ein weiterer Begriff gefunden werden, über den bei Bedarf nach einer oder mehreren Geschäftsstellen selektiert werden kann, bzw. über dessen Ausklammerung in Statistiken eine Zusammenfassung aller Geschäftsstellen erreicht werden kann. Als umfassenden Begriff könnte man sich GESCHAEFTSSTELLEN vorstellen, konkrete Inhalte dazu wären z. B. Hamburg, Hannover und München. Alle diese bisher analysierten Komponenten und Wesensmerkmale statistischer Aussagen finden sich im ASS-Konzept wieder. Es sind im wesentlichen drei Komponenten:
- die Komponente ZEIT
- die Komponente WERT
- die Komponente SCHLUESSEL
Soll ASS die Beziehung zu den im Beispiel gebrauchten Begriffen herstellen, so ist mit ZEIT der dort angesprochene Zeitraum- oder Zeitpunktbezug der statistischen Aussage gemeint. Als WERT im Sinne von ASS sind die mengen-, wert- und größenbezogenen Statistikdaten zu verstehen, z. B. ANZAHL AUSZUBILDENDER. Werte sind somit Daten, die ein Mess-, Zähl- oder Schätzergebnis wiedergeben. Werte besitzen eine tatsächlich ausgedrückte oder nur gedachte Wertedimension, z. B. DM, Stück, Liter, Personen usw., nach der sie zu interpretieren sind.
SCHLUESSEL hingegen sind abstrakte Begriffe, die mehrere konkrete Inhalte zusammenfassen. Über diese Schlüssel und ihre Inhalte kann in der oben gezeigten Weise eine Selektion bzw. Zusammenfassung der Werte einer Anforderung vorgenommen werden. Im ASS-Sprachgebrauch sind die konkreten Schlüsselinhalte SCHLUESSELAUSPRAEGUNGEN oder einfach AUSPRAEGUNGEN. Das obige Beispiel enthält folgende Schlüssel und Ausprägungen:
| Schlüssel | Ausprägungen |
|---|---|
| GESCHLECHT | WEIBLICH |
| MAENNLICH | |
| GESCHAEFTSSTELLE | HAMBURG |
| HANNOVER | |
| MUENCHEN |
Im Gegensatz zu den Werten stellen Schlüssel und Ausprägungen keine Größen dar, mit denen man Rechenoperationen durchführt, auch wenn die Ausprägungen eines Schlüssel durchaus numerischen Inhalt haben können. Es macht wohl Sinn, zum Beispiel die Zahl männlicher und weiblicher Auszubildender zu addieren, um so die Gesamtzahl zu erhalten. Doch es ist kaum sinnvoll, die numerischen Ausprägungen des Schlüssels POSTLEITZAHL z. B. 80333, 57518 und 40710 aufzuaddieren oder irgendwelche Rechenoperationen mit den Ausprägungen eines Schlüssels JAHRGANG z. B. 1970, 1971 durchzuführen.
Es ist in der ASS-Statistikauswertung zwar möglich, eine Summenformel '1970' + '1971' anzufordern. Doch in diesem Fall wird keineswegs eine Summierung der Ausprägungen vorgenommen. Vielmehr werden die zu den Ausprägungen gespeicherten Werte addiert. Im Gegensatz zu den Werten stellen Schlüssel, auch wenn ihre Inhalte Zahlen sind, keine numerischen Größen dar, die in erster Linie auf ihre Mess- oder Zählbarkeit abzielen. Schlüssel und Schlüsselausprägungen verkörpern Kriterien, nach denen ein an sich gleichbleibender Gesamtbetrag eines Wertes in - je nach Umfang der gewünschten Schlüssel und Ausprägungen - verschieden viele und verschieden große Teilmengen aufgeteilt wird.
Die bisher aufgeführten ASS-Komponenten liessen sich durchwegs aus bestehenden Statistiken ableiten. Das ARBEITSGEBIET stellt nun eine Komponente dar, die in anderen Statistiken nicht anzutreffen ist.
7.3 Vorgehensweisen zur Ermittlung des benötigten Arbeitsgebietes
Der Begriff des Arbeitsgebietes ist ASS-spezifisch. Und oft ist die Herleitung einer solchen Einheit kompliziert. Als Erstes bietet sich das bisher praktizierte Gliederungsprinzip als Ausgangspunkt an. Erscheinen die hier auftretenden Einheiten für eine Zuordnung auf ASS-Arbeitsgebiete geeignet, so ist die Festlegung der gewünschten Arbeitsgebiete einfach.
Jedoch ist eine kritiklose Übernahme bisher gepflegter Strukturen auf das ASS-Arbeitsgebiets-Konzept nicht immer zu empfehlen. Eventuell ist es besser, bisher aus technischen Gründen oder wegen der Zuständigkeiten getrennt gehaltene, statistische Einheiten unter einem Arbeitsgebiet zusammenzufassen.
So ist die Pflege der Daten wesentlich einfacher zu handhaben,
ohne dass auf irgendwelche bisher gebrauchten Statistiken
verzichtet werden muss oder dass irgendeine Beeinträchtigung
der Zuständigkeiten in Kauf genommen werden muss.
Erscheint die Ableitung der ASS-Arbeitsgebiete aus den bisher
gepflegten Strukturen des jeweiligen Statistikwesens nicht
sinnvoll, so kann alternativ bei der Einteilung der Arbeitsgebiete
die Situation des Unternehmens als Grundlage dienen.
Eventuell können die betriebliche Struktur oder die im Unternehmen
repräsentierten Sparten einen Lösungsansatz bieten.
Führt auch dieser Weg zu keinem brauchbaren Ergebnis, so bietet
sich an, aus der Art der gewünschten Statistiken geeignete
Arbeitsgebiete abzuleiten.
So könnten Arbeitsgebiete erschlossen werden, die alles vereinen,
was z. B. mit Verkaufsstatistiken oder Schadenstatistiken
zusammenhängt.
Außerdem könnte die Einteilung in Arbeitsgebiete über die Art der Werte vorgenommen werden: Das Resultat wäre ein Arbeitsgebiet, das nur Bewegungswerte aufnimmt und daher auf Bewegungsstatistiken abzielt. Ein zweites Arbeitsgebiet könnte analog dazu Bestandsstatistiken zum Inhalt haben.
7.4 Vorgehensweisen zur Ermittlung von Schlüsseln und Werten
Zwei Vorgehensweisen sind denkbar:
Die erste Methode sieht vor, dass man vom Primärdatenbestand
ausgeht und daraus alle irgendwie als Schlüssel oder Werte
denkbaren Kategorien übernimmt. Auf diese Weise wird jedes
Risiko vermieden. Statistiken, die vielleicht jetzt noch nicht
gebraucht werden, können später jederzeit hinzugenommen
werden. Denn bei der Auswahl der Schlüssel und Werte wird das
gesamte Statistikwesen berücksichtigt und nicht nur die Belange
einiger, im Augenblick geplanter, statistischer Anforderungen.
Diese Methode ist wegen dieses Sicherheitsaspektes vor allem
am Anfang der Beschäftigung mit ASS zu empfehlen, wenn die
Zusammensetzung der aus dem Arbeitsgebiet zu beziehenden
Statistiken noch nicht genau feststeht.
Aber der Speicherplatzaufwand ist in diesem Fall relativ hoch.
Mit der Erfahrung aus dem Praxiseinsatz kann aber später leicht
festgestellt werden, welche Schlüssel- und Wertedefinitionen nun
völlig überflüssig sind und somit nur unnötig Speicherplatz
verbrauchen. Eine Löschung solcher nicht gebrauchter Begriffe
und Daten ist nachträglich immer möglich und ohne größeren
Aufwand zu bewerkstelligen.
Werden aber für neu hinzugekommene Statistiken zusätzliche
Schlüssel oder Werte benötigt, so ist eine nachträgliche
Definition in einem kleineren Rahmen zwar auch möglich,
erfordert aber erheblichen Aufwand und kann unter Umständen eine
völlige Reorganisation der eingespeicherten Daten nach sich
ziehen.
Es ist auf jeden Fall leichter, zu viel gespeicherte
Daten wieder zu löschen, als nicht gespeicherte Daten
nachträglich und eventuell rückwirkend aufzunehmen.
Die zweite Methode sieht eine ganz bewusste Reduzierung der Schlüssel und Werte auf das unbedingt benötigte Maß vor. Man geht hier nicht vom Datenbestand, sondern von den Bedürfnissen der geplanten Statistiken aus. Die Fragestellung ist hier also nicht, welche Schlüssel und welche Werte lassen sich aus dem gesamten statistischen Datenbestand ableiten, sondern: welche Schlüssel und welche Werte werden für die zukünftigen, in ihrem Aufbau und in ihrer Zahl schon ganz genau feststehenden statistischen Anforderungen benötigt. Der Sicherheitsaspekt ist in diesem Fall nicht gegeben. Ein Anwender, der nach dieser Methode vorgeht, muss davon ausgehen, dass sich die Zusammensetzung seiner Statistiken hinsichtlich zusätzlicher Schlüssel oder Werte, wenn überhaupt, nur unter größerem Aufwand realisieren lässt. Allerdings kann ein Anwender, der dieses Sicherheitsrisiko bewusst in Kauf nehmen kann, weil er eben sicher weiss, dass sich an den Statistiken nicht mehr sehr viel ändern wird, sehr viel Aufwand an Speicherplatz und Einrichtungsarbeit sparen.
Wie bei der Wahl des Arbeitsgebiets können wir auch bei der Entscheidung für eine dieser beiden Vorgehensweisen kein Patentrezept geben, da auch hier sehr stark die spezielle Situation des jeweiligen Anwenders hereinspielt. In der Regel empfehlen wir - vor allem bei entsprechender ASS-Erfahrung - einen Zwischenweg zu suchen, bei dem zwar nicht der gesamte Primärdatenbestand berücksichtigt wird, der aber doch erheblich mehr Informationen festhält, als eine strikte Auslegung der zweiten Methode zulassen würde.
7.5 Arbeitsgebietsübergreifende Definitionen und Auswertungen
Arbeitsgebiete dürfen sich hinsichtlich der verwendeten Werte,
Schlüssel und Zeiträume durchaus überschneiden. Die Definition
eines Schlüssels oder Wertes als solches legt den entsprechenden
Begriff noch nicht für die Verwendung in einem Arbeitsgebiet
fest. Dies erfolgt erst durch die Definition des Arbeitsgebietes,
bei der Zuweisung der verwendeten Schlüssel und Werte. Es gibt
also eine Gesamtmenge an ASS-Schlüsseln und eine Gesamtmenge an
ASS-Werten. Bei der Arbeitsgebietsdefinition weist man nun dem
Arbeitsgebiet zwei Auswahlmengen aus diesen beiden Gesamtmengen
zu. Diese Auswahlmengen können sich natürlich, betrachtet man
mehrere Arbeitsgebiete, in einem beliebig großen Ausschnitt
überschneiden.
Obwohl das Arbeitsgebiet von der Strukturierung der erfassten
Daten her gesehen, die höchste logische Einheit darstellt,
heißt das nicht, dass statistische Auswertungen über mehrere
Arbeitsgebiete hinweg nicht möglich sind. ASS lässt Statistiken
zu, die auf bis zu fünf Arbeitsgebiete bezugnehmen.
7.6 Das Problem zeitabhängiger Schlüssel
Beispiel: ein Schlüssel ALTERSSTUFE. Für die Altersstufe 31 bis 35 (Schlüsselausprägung) sind am 1.2.2000 genau 5000 Kunden ermittelt worden. Wenn nun an diesem Stichtag 800 dieser Personen 35 Jahre alt waren, so wird dieselbe Statistik ein Jahr später, ohne dass sich am Kundenbestand etwas geändert hat, 800 Personen weniger aufweisen, während der Kundenbestand für die Altersstufe 36-40 sich um den entsprechenden Betrag erhöht hat, ohne dass eine wirkliche Bestandsveränderung aufgetreten ist. Die Versorgung eines derartigen Schlüssel erfordert also zusätzlichen Aufwand, der von den Gegebenheiten her eigentlich nicht gerechtfertigt wird. Denn nimmt man statt der Altersstufe das Geburtsjahr, so fehlt diesem neuen Schlüssel diese ungewollte, zeitabhängige Dynamik. Bei der Festlegung der Schlüssel ist es daher ratsam, auf derartige unerwünschte Begleiterscheinungen zu achten und sie, wenn möglich zu vermeiden. Es sei denn, dieser zusätzliche Aufwand muss in Kauf genommen werden, weil eben die Aussagekraft eines Schlüssels ALTERSSTUFE höher ist als die eines Schlüssels Jahrgang.
7.7 ASS-Wertfestlegungen
Für jeden Wert im ASS-System ist eine Festlegung der Werteart an sich sowie der Anlieferungsart des Wertes speziell bei der Schnittstellenanlieferung für die Erst- und Folgeeinspeicherung erforderlich.
7.7.1 Werteart
Die Werteart legt zunächst fest, welche Art von Zeitbezug ein in
den Summenbeständen gespeicherter Wertinhalt repräsentiert:
Je nachdem, ob ein Wertinhalt stichtags- oder zeitraumbezogen zu
interpretieren ist, spricht man von einem Bestands- oder einem
Bewegungswert. Bei einem Bewegungswert werden nur die in einem
bestimmten Zeitraum aufgetretenen Veränderungen festgehalten.
Bei einem Bestandswert dagegen wird der tatsächliche Bestand,
der für einen bestimmten Tag ermittelt wurde, gespeichert.
Dieser neue Bestand stellt die Summe aus dem ursprünglichen
Bestand und den inzwischen aufgetretenen Bewegungen dar.
Zusätzlich kennzeichnet die Werteart eines Wertes auch dessen
Verwendung in den Auswertungen. Im ASS-Konzept stehen den
unabhängig auswertbaren Werten sogenannte Umrechnungswerte
gegenüber, die nur in Werteformeln in Zusammenhang mit
unabhängigen Werten eingesetzt werden können. Sie enthalten
bestimmte Umrechnungssätze, nach denen unabhängige Werte in den
Auswertungen neu berechnet werden, z. B. Währungskurse.
7.7.2 Anlieferungsart
Die Anlieferungsart beschreibt einen Wert hinsichtlich der
Behandlung des Wertes bei der Einspeicherung seiner Inhalte in
die ASS-Bestände. Über die Anlieferungsart wird die Interpretation
des Zeitbezuges der angelieferten Wertinhalte gesteuert.
ASS-Werte können als stichtagsbezogene Bestandswerte oder als
zeitraumbezogene Bewegungswerte angeliefert werden.
Normalerweise werden die Wertinhalte mit derselben Zeitbezugsart, mit der
sie angeliefert werden, auch gespeichert. Soll ein Wert aber als
Bestandswert festgehalten werden, so kann er, nach erfolgter
Ersteinspeicherung, auch als Bewegungswert angeliefert werden.
Bei der Einspeicherung wird dann aus dem schon vorhandenen
Bestand und den neu angelieferten Bewegungen der neue Bestand
abgeleitet.
Neben dieser Art des Zeitbezuges legt die Anlieferungsart auch
die Art der Einspeicherung und Pflege eines Wertes fest. So
werden im ASS-System Werte unterschieden, die nur im BATCH
eingespeichert werden können und Werte, die auch ONLINE gepflegt
werden können. Da ein Wert, der ONLINE gepflegt werden kann,
notwendigerweise wegen des Erfassungsaufwandes keine großen
Datenmengen beinhalten darf, normale IST-Werte aber in der Regel
diese Voraussetzung nicht erfüllen, werden vor allem Plan- oder
Sollwerte und evtl. Umrechnungswerte für Wertumrechnungen im
Dialog verwaltet oder vorgegeben. In der ASS-Terminologie handelt
es sich um "Vorgabewerte", wenn Werte aufgrund ihrer Anlieferungsart
die Möglichkeit der ONLINE-Pflege besitzen.
7.8 ASS-Werttypen
Aus den verschiedenen Kombinationsmöglichkeiten von Werte- und
Anlieferungsart lässt sich eine entsprechende Zahl von Werttypen
ableiten. Bei der Werteanalyse sollte zunächst die Art der
Verwendung eines Wertes in der Auswertung bestimmt werden:
Soll der Wert für sich allein aussagekräftige Inhalte
repräsentieren oder sollen seine Inhalte Umrechnungssätze für
andere Werte darstellen? Die zusätzlichen Aussagen von Werte-
und Anlieferungsart unterteilen diese zwei Kategorien in je vier
Untergruppen.
7.8.1 Unabhängig auswertbare Ist- und Soll-Werte
Zu dieser Hauptgruppe der ASS-Werte zählen alle in statistischen
Auswertungen eines Unternehmens auftretenden mess- oder
zählbaren Wertgrößen, z. B. Anzahl Kunden, Anzahl Verträge,
Leistung, Soll-Leistung. Die Inhalte von Ist- und Soll-Werten
werden nach den jeweiligen Schlüsselinhalten aufgegliedert
gespeichert. Das Weglassen bzw. Anfordern von Schlüsselinhalten,
nach denen der Wert ausgeprägt vorliegt, führt in der
Auswertung zu einem Zusammenfassen bzw. Auffächern des
betreffenden Wertes. Für Auswertungen mit Schlüsseln, nach
denen der Wert nicht eingespeichert vorliegt, steht der Wert in
der Regel nicht zur Verfügung (Ausnahme: Auswertung über
mehrere Arbeitsgebiete mit nicht gemeinsamen Schlüsseln).
Werte dieser Gruppe können für sich allein oder in Formeln
zusammen mit anderen Werten ausgewertet werden. Aus den weiteren
Festlegungen von Werteart und Anlieferungsart ergeben sich
folgende Untergruppen:
- Im BATCH gepflegte, allein auswertbare Bestandswerte
- Im BATCH gepflegte, allein auswertbare Bewegungswerte
- Im ONLINE gepflegte, allein auswertbare Bestandswerte
- Im ONLINE gepflegte, allein auswertbare Bewegungswerte
Da an wirkliche Planwerte sehr häufig die Anforderung gestellt wird, dass sie möglichst schnell und einfach zu ändern sein sollen, werden Soll-Werte in der Regel als ONLINE zu pflegende Werte definiert.
7.8.2 Nur mit anderen Werten in Formeln auswertbare Umrechnungswerte
Diese Gruppe von Werten bietet für die Umrechnung bestimmter anderer Werte Berechnungssätze. Umrechnungswerte können ebenfalls nach bestimmten Schlüsselinhalten gespeichert werden. Allerdings sind diese Werte auch für Schlüsselinhalte verfügbar, nach denen sie gar nicht selektiert vorliegen. Wird in einer Anforderung ein Umrechnungswert in Zusammenhang mit einem Schlüssel angesprochen, nach dem der Wert ausgeprägt vorliegt, so werden die jeweiligen Inhaltsanteile, die zu den einzelnen Ausprägungen dieses Schlüssels vorliegen, für die Berechnung herangezogen. Für alle Schlüsselkombinationen, die die gleiche Ausprägung dieses einen Schlüssels enthalten, wird derselbe Wertinhalt angesprochen, da der Wert ja nicht nach den Ausprägungen der anderen Schlüssel ausgeprägt ist. Weglassen oder Setzen von Inhalten dieses Schlüssels führt zur Kumulation bzw. Auffächerung des Wertes, nicht aber das Weglassen oder Setzen von Inhalten anderer Schlüssel, nach denen der Wert nicht ausgeprägt vorliegt. Wird der Schlüssel, nach dem der Umrechnungswert selektiert gespeichert ist, nicht angefordert, so wird der Wert über diesen Schlüssel kumuliert, d. h. für alle Schlüsselkombinationen gilt dann dieser kumulierte Gesamtwert. Aus den weiteren Festlegungen von Werteart und Anlieferungsart ergeben sich folgende Untergruppen:
- Im BATCH gepflegte, nur zur Umrechnung eines anderen Wertes zu verwendende Bestandswerte
- Im BATCH gepflegte, nur zur Umrechnung eines anderen Wertes zu verwendende Bewegungswerte
- Im ONLINE gepflegte, nur zur Umrechnung eines anderen Wertes zu verwendende Bestandswerte
- Im ONLINE gepflegte, nur zur Umrechnung eines anderen Wertes zu verwendende Bewegungswerte
7.9 Die Berücksichtigung der ASS-Komponente Zeit
Die Werteunterscheidung nach Bewegung und Bestand bedingt auch eine
entsprechende Unterscheidung des zeitlichen Aspekts in Zeitraum und
in Zeitpunkt. Wie schon angesprochen, beziehen sich Bestände immer
auf einen Zeitpunkt (Stichtag), Bewegungen nehmen hingegen auf
einen Zeitraum Bezug.
Der kleinste Zeitraum, der für Auswertungen gewählt werden kann,
ist ein Monat und ab Version 7.30 ein Tag. Bestehende
Monatsarbeitsgebiete können einmalig mit PCL1011 auf
Tagesarbeitsgebiete umgestellt werden.
Die Aktualität der eingespeicherten Daten wird durch die
Häufigkeit der Folgeeinspeicherung bestimmt. Üblicherweise wird
im Monatsrhythmus einmal monatlich eingespeichert, doch spricht
nichts dagegen, bei entsprechendem Bedarf, täglich
Einspeicherungen vorzunehmen. ASS erlaubt es, die monatliche
Einspeicherung in beliebig vielen Portionen an verschiedenen Tagen,
also auch täglich, vorzunehmen.
Der Zeitpunkt, auf den Bestandswerte bezogen sind, ist der
Stichtag, an dem die Daten für die Schnittstelle zusammengestellt
wurden. Wird am 2. Februar eine Einspeicherung für den Monat
Januar vorgenommen und die Bestandswerte der Schnittstelle
enthalten die Bestände, die am 28. Januar angefallen waren, so ist
der 28. Januar der Bezugszeitpunkt für Bestandswerte des Monats
Januar.
Pro Arbeitsgebiet wird ein ASS-Statistikjahr definiert. Dieses kann
zwischen 12 und 16 Monate umfassen.
8 Spezielle ASS-Einrichtungen
8.1 Zugriffsberechtigung
Die Zugriffsberechtigung ist auf Basis folgender Elemente realisiert:
- Arbeitsgebiete
- Schlüssel (mit Schlüsselinhalten)
- Werte
- Zeiträume
- Listanforderungen und Formeln
- Sonstiges
Unter dem Begriff 'Sonstiges' werden folgende Berechtigungen zusammengefasst:
- Auswertungen über nicht freigegebene Zeiträume
- Sicherstellen von einmalig und periodisch auszuführenden Listanforderungen
- Anzeige einer Statistik im Dialog (STAT)
- Unterdrückung der Anzeige von Listanforderungen und deren Sicherstellung durch die Sperrung der Kommandos LIST, STAT und ENDE in der zentralen Maske VS101 der Listerstellung im Dialog. Alle anderen Kommandos dieser Maske sind erlaubt.
- Berechtigung für ändernde Zugriffe auf Anforderungsdatenbank
- Erfassung/Änderung von Vorgabewerten im Dialog
Einer bestimmten Person (identifiziert durch ihre Personalnummer) werden zugeordnet eine Menge von
- Arbeitsgebieten
- Schlüsseln (mit Inhalten)
- Werten
- Zeiträumen
- Listanforderungen und Formeln
sowie bestimmte Elemente aus Sonstiges.
Sie erhält die Zugriffsberechtigung für alle Elemente des kartesischen Produktes obiger fünf Mengen, das heißt sie ist berechtigt für eine Kombination Arbeitsgebiet, Schlüssel (mit Inhalt), Wert, Zeitraum, Element aus Sonstiges, wenn sie die Zugriffsberechtigung für das betreffende Arbeitsgebiet und für den betreffenden Schlüssel (mit Inhalt) und den betreffenden Wert und den betreffenden Zeitraum und für das betreffende Element aus Sonstiges hat.
Darüber hinaus können bestimmte Personen auch zur Anforderung bestimmter Schlüssel gezwungen werden (sogenannter Muss-Schlüssel). Ist eine derartige Person nur für einen Teil der Schlüsselausprägungen eines Muss-Schlüssels berechtigt, so wird auf diesem Weg erreicht, dass sie nie das Gesamtgeschäft des Unternehmens ermitteln kann.
Das Unterprogramm MCL0076 prüft die Berechtigungen, vorausgesetzt, dass die Zugriffsberechtigungen vorher in programminterne Tabellen gelesen worden sind.
Dieses Einlesen übernimmt das Unterprogramm MCL0077.
ASS greift für seine Security-Regelung auf bereits angelegte Security-Datenbestände zurück und kann auf diese Weise in bestehende, hausinterne Berechtigungsverfahren integriert werden. Dazu sind diese schon vorhandenen Bestände um einige zusätzliche, ASS-relevante Informationen zu erweitern, die dann dem ASS-Programm MCL0077 über eine geeignete Codierung des Include-Elements SST2036 zugänglich gemacht werden.
Kann nicht auf ein bereits bestehendes Berechtigungsverfahren zurückgegriffen werden, so ist es möglich, auf irgendeinem, online erreichbaren Datenträger einen speziellen ASS-Security-Datenbestand zu erfassen. Allerdings muss die Einrichtung eines solchen Bestandes mit ASS-fremden Mitteln erfolgen. Auch in diesem Fall wird über die Aufnahme geeigneter Zugriffs- und Verarbeitungsroutinen in das Include-Element SST2036 die Verbindung zu ASS hergestellt.
Schließlich ist es noch denkbar, diesen erforderlichen
Security-Bestand unmittelbar im ASS-Programm MCL0077 (SST2036)
zu definieren.
Welche Informationen in welcher Form für die entsprechenden
Regelungen in diesem Security-Datenbestand enthalten sein
müssen, ist aus der Definition der ASS-Privacy-Tabelle
(Include-Element SST2034) ableitbar.
Die Regelung der Zugriffsberechtigungen finden Sie auch in den entsprechenden Kapiteln im ASS-Handbuch 'Einrichten von ASS-Berechtigungen'.
8.2 Erweitertes Zählverfahren (Bitschlüssel)
Der Bitschlüssel ermöglicht ein Zählverfahren im Zusammenhang mit den im Arbeitsgebiet verwendeten Schlüsseln und Werten. Der Bitschlüssel ist eine vielseitig verwendbare Erweiterung, mit der das Auftreten von Ereignissen gezählt werden kann (relative Häufigkeit von Ereignissen im mathematischen Sinn).
Problemschilderung:
Es sei eine hierarchische Umgebung im Ausgangsdatenbestand vorgegeben,
z. B. MANTEL -> TARIF oder VERTRAG -> KUNDE -> TARIF
Mäntel bzw. Verträge seien in den Summendatenbanken nicht gespeichert. Dennoch sollen Fragestellungen wie "Wieviele Mäntel enthalten den Tarif 17" oder "Wieviele Kunden haben den Tarif 19 abgeschlossen" beantwortet werden. Beachtet werden muss hierbei, dass bei einem Mantel der Tarif 17 mehrfach vorkommen kann, und somit eine einfache Zählung der Tarife die gestellte Frage nicht beantworten kann.
Das Problem ist sogar noch komplizierter, wenn z. B. eine bestimmte Organisationstruktur zusätzlich berücksichtigt werden muss. Ein bestimmter Kunde kann zum Beispiel ein und denselben Tarif (u. U. mehrfach) bei verschiedenen Filialen abschließen. Es sollen dann auch Fragen wie "wieviele Kunden haben in der Filiale XY den Tarif 17 abgeschlossen?" beantwortet werden. (Auf dieses Beispiel gehen wir weiter unten noch ausführlich ein).
Der nachfolgende Teil des Kapitels schildert die Problemlösung mittels Bitschlüssel. Sie können ihn beim ersten Lesen überspringen, wenn Sie nicht gezielt das Thema Bitschlüssel bearbeiten wollen.
Problemlösung:
Es werden sogenannte "Bitschlüssel" eingeführt. Ein Bitschlüssel definiert eine Teilmenge der verwendeten Schlüssel eines Arbeitsgebietes. Ansonsten werden Bitschlüssel genauso wie die anderen Schlüssel behandelt.
Die verwendeten Schlüssel eines Arbeitsgebiets haben eine
sozusagen "kanonische" Sortierung (Reihenfolge), nämlich die
Reihenfolge, in der der verdichtete Inhalt im Schlüssel
der zugehörigen Summendatenbank gespeichert wird (Sortierung
nach CREPO).
Die durch den Bitschlüssel definierte Teilmenge enthält
eine bestimmte Anzahl (etwa n) von verwendeten Schlüsseln.
Daher sind die verwendeten Schlüssel durchzählbar,
1, 2, ... , n, jeder Schlüssel der Teilmenge ist also
durch eine Zahl zwischen 1 und n identifiziert.
Bei einem verwendeten Wert im Arbeitsgebiet kann ein Bezug
zu einem Bitschlüssel hergestellt werden. Dabei ist die
Nummer des entsprechenden Bitschlüssels beim verwendeten
Wert anzugeben.
Nachfolgend bezeichnet W1 immer einen Wert, der sich auf einen Bitschlüssel bezieht. Belegung des Inhaltes von Bitschlüsseln:
Es gibt 2**n Teilmengen der durch den Bitschlüssel definierten Schlüsselmenge.
Jeder dieser Teilmengen wird eine Zahl nach folgender Regel zugeordnet:
Es wird eine binäre Zahl der Länge n (n Bits) betrachtet: gehört der i-te Schlüssel zur betrachteten Teilmenge, so wird das i-te Bit auf '1' gesetzt, ansonsten auf Null. Der Wert der Binärzahl plus 1 ist die zugeordnete Zahl.
Beispiel:
vier Schlüssel (S1, S2, S3, S4) in dieser Reihenfolge.
Die binäre Zahl hat also eine Länge von 4 Bits. betrachten wir die Teilmenge (S2,S4) so ergibt das den Bitstring '0101', also den Wert 2**0 + 2**2 + 1 = 6.
Bei vier Schlüsseln kann man also insgesamt die Werte 1, 2, 3, ... , 16 erhalten.
Das System wertet den Wert W1 immer im Zusammenhang mit dem zugeordneten Bitschlüssel aus. Es soll eine Auswertung betrachtet werden, in der S2 und S4 als Kopf/Zeilenschlüssel angefordert werden. Der Wert W1 wird nur dann berücksichtigt, wenn beim Inhalt des zugeordneten Bitschlüssels das 6. Bit auf '1' gesetzt ist (von links in KEINH gezählt, (1, 2, 3, ...)). Durch diese Vorgehensweise wird erreicht, dass Werte in Abhängigkeit der angeforderten Schlüssel ausgewertet werden. Die Schnittstelle bestimmt, wie die Auswertung arbeitet, da sie den Inhalt der Bitschlüssel vergibt.
Soll der Wert W1 im Zusammenhang mit S2 und S4 berücksichtigt werden, so ist das 6. Bit zu setzen. Entsprechendes gilt für jede andere Teilmenge. Wird kein Schlüssel der definierten Teilmenge in der Auswertung angefordert, so wird bei W1 stets das erste Bit berücksichtigt.
In vielen Fällen kann die Schnittstelle beim Belegen der
Bits folgendermaßen verfahren:
Tritt die Schlüsselkombination S2, S4 zum erstenmal auf,
so wird das 6. Bit gesetzt, ansonsten nicht.
In einem Arbeitsgebiet können mehrere Bitschlüssel definiert werden. Ein verwendeter Wert bezieht sich immer auf genau einen Bitschlüssel.
Nicht benutzte Bits beim Schlüsselinhalt (KEINH) müssen entweder auf LOW oder auf HIGH gesetzt werden.
Definition von Bitschlüsseln im Arbeitsgebiet
Enthält die Schlüsselüberschrift eines verwendeten Schlüssels nur die Zeichen '0' und '1', so wird hierdurch ein Bitschlüssel definiert.
Jedes Zeichen entspricht einem verwendeten Schlüssel im Arbeitsgebiet. Das erste Zeichen entspricht dem 1. Schlüssel, das zweite Zeichen dem zweiten Schlüssel, usw. Die Reihenfolge der Schlüssel ist die oben erwähnte kanonische Reihenfolge.
Bedeutung der Zeichen:
- '0' : Der betreffende Schlüssel gehört nicht zu der zu definierenden Teilmenge.
- '1' : Der betreffende Schlüssel gehört zu der zu definierenden Teilmenge.
Da für die Schlüsselüberschrift 25 Zeichen zur Verfügung stehen, ist das betreffende Arbeitsgebiet so einzurichten, dass verwendete Schlüssel, auf die bei einem Bitschlüssel Bezug genommem werden soll, bei den ersten 25 verwendeten Schlüsseln vorkommen.
Beispiel für Bitschlüssel
Betrachtet werden sollen folgende Schlüssel:
TARIF, GESCHLECHT, ALTERSGRUPPE (AG)
bei folgendem Aufbau des Ausgangsbestandes:
Der Ausgangsbestand ist gegliedert nach Mänteln (Verträgen). In einem Mantel können mehrere Personen versichert sein, die wiederum mehrere Tarife abgeschlossen haben können.
Das Geschlecht männlich wird mit M und das Geschlecht weiblich wird mit W abgekürzt. Es gebe die Altersgruppen AG1 und AG2 und die Tarife T17, T18, T19, T20, T21, T31 und T40.
Folgendes Beispiel sei gegeben:
- Mantel-1
- Person-1 M AG1
- T17
- T18
- T19
- Person-2 M AG1
- T18
- T19
- T20
- Person-3 W AG2
- T17
- T21
- Person-1 M AG1
- Mantel-2
- Person-1 W AG1
- T17
- T31
- Person-2 M AG2
- T17
- T31
- Person-3 M AG2
- T18
- T19
- T40
- Person-1 W AG1
Es soll eine Personenzählung und eine Mantelzählung ermöglicht werden.
- W1: Mantelzähler
- W2: Personenzähler
Die Reihenfolge der Schlüssel im AG sei TARIF, GESCHLECHT, ALTERSGRUPPE.
Den Werten W1 und W2 wird je ein Bitschlüssel zugeordnet. Da 3 Schlüssel vorliegen, werden 2**3 = 8 Bits benötigt.
Die Zuordnung ist folgendermaßen:
kein Schlüssel : B'000' + 1 = 1. Bit
nur TARIF : B'100' + 1 = 5. Bit
nur GESCHLECHT : B'010' + 1 = 3. Bit
nur ALTERSGRUPPE : B'001' + 1 = 2. Bit
TARIF mit ALTERSGRUPPE : B'101' + 1 = 6. Bit
TARIF mit GESCHLECHT : B'110' + 1 = 7. Bit
GESCHLECHT mit ALTERSGRUPPE : B'011' + 1 = 4. Bit
TARIF, GESCHLECHT, ALTERSGRUPPE : B'111' + 1 = 8. BitDie im Beispiel aufgeführten Mäntel ergeben 8 + 7 = 15 Schnittstellensätze.
Diese Schnittstellensätze sind folgendermaßen aufgebaut:
TARIF GESCHLECHT AG Bitschlüssel(W1) Bitschlüssel(W2) W1 W2
Mantel-1
T17 M AG1 B'11111111' B'11111111' 1 1
T18 M AG1 B'00001111' B'00001111' 1 1
T19 M AG1 B'00001111' B'00001111' 1 1
T18 M AG1 B'00000000' B'11111111' 1 1
T19 M AG1 B'00000000' B'00001111' 1 1
T20 M AG1 B'00001111' B'00001111' 1 1
T17 W AG2 B'01110111' B'11111111' 1 1
T21 W AG2 B'00001111' B'00001111' 1 1
Mantel-2
T17 W AG1 B'11111111' B'11111111' 1 1
T31 W AG1 B'00001111' B'00001111' 1 1
T17 M AG2 B'01110111' B'11111111' 1 1
T31 M AG2 B'00000111' B'00001111' 1 1
T18 M AG2 B'00001111' B'11111111' 1 1
T19 M AG2 B'00001111' B'00001111' 1 1
T40 M AG2 B'00001111' B'00001111' 1 1
Für die externe Schnittstelle im Textformat (PCL1001 mit Option EXIT_TEXT) müssen die Bitschlüsselinhalte analog als 0-1-Strings angeliefert werden, z.B. '01110111...' usw.
Beispiele für Auswertungen:
1. Kein Schlüssel W1 W2
2 6
2. TARIF W1 W2
T17 2 4
T18 2 3
T19 2 3
T20 1 1
T21 1 1
T31 1 2
T40 1 1
3. TARIF GESCHLECHT W1 W2
T17 M 1 1
W 2 2
T18 M 2 3
W 0 0
T19 M 2 3
W 0 0
T20 M 1 1
W 0 0
T21 M 0 0
W 1 1
T31 M 1 1
W 0 1
T40 M 1 1
W 0 0
4. AG GESCHLECHT W1 W2
AG1 M 1 2
W 1 1
AG2 M 1 2
W 1 1
8.3 Universelle Auswertungs-Schnittstelle (Datei LDAT)
ASS bietet eine universell verwendbare Schnittstelle, mit der die Information aus ausgeführten Anforderungen bzw. Auswertungen an den Host oder an den Personal-Computer (PC) weitergegeben werden können. Somit können ASS-Summendatenbanken oder Teilinformationen aus ASS-Summendatenbanken für eine weitere Verarbeitung genutzt werden.
Diese Schnittstelle kann insbesondere für den PC genutzt werden.
Durch diese Schnittstelle eröffnen sich eine Fülle von
Möglichkeiten (z. B. für grafische Darstellung und Aufbereitung von
Statistiken und Einbindung in eigene Texte bzw. Berichte am PC).
Zu diesem Zweck werden Dateien zur Verfügung gestellt,
die dann mit bereits existierender Standard-Software
in den PC transferiert werden können.
Für die Weiterverarbeitung am PC können derzeit folgende Formate
angefordert werden:
- SYMPHONY
- FOCUS
- FOCUS2
- DBASE
- COBOL
- LOTUSD
- OA (OPEN ACCESS)
- EXCEL
- ALPHA
- SIPLAN
- PARADOX
- DB2 (DB2-Ladeformat - impliziert COBOL-Format)
Die PC-Dateien können Sie auf folgenden Wegen erzeugen:
- Weg: Die Anforderung wird im Dialog erstellt und unter der gewünschten Bibliotheksart (entweder einmalig ausführende oder periodisch auszuführende Anforderungen) gesichert. Das Programm PCL1016 führt im Batch diese gesicherte Anforderung aus und erstellt die PC-Datei(en). Durch die unterschiedliche Bibliotheksart ergibt sich eine komfortable Möglichkeit, Listen periodisch (z. B. monatliche Listen) und/oder einmalig (für Einmal- oder Sonderaktionen) zu erzeugen und zu pflegen.
- Weg: Die Anforderung wird in der Batchanforderungssprache erstellt. Das Programm PCL1003 führt im Batch diese Anforderung aus und erstellt die PC-Datei(en).
Einzelheiten zu PCL1038 sind im Benutzerhandbuch DIENSTPROGRAMME beschrieben. Die Erstellung von geeigneten Anforderungen und die genaue Beschreibung der Schnittstelle, die als Datei unter dem Namen LDAT geführt wird, ist im Benutzerhandbuch BETRIEB 1 beschrieben.
8.4 Statistik über Statistiken
8.4.1 Allgemeines
In ASS besteht die Möglichkeit, Protokoll über die
Anforderungen und die darin verwendeten Schlüssel, Werte
Arbeitsgebiete, Verdichtungsstufen, Formeln, Schlüssel-
und Wertegruppierungen zum Zeitpunkt der Anforderungsauswertung
bei Batch- (PCL1003, PCL1016, PCL1019) und Online-Auswertungen
(ST31, AXCEL, HTML) mitführen (loggen) zu lassen.
Zusätzlich können die Inhalte der Steuerungs- (DST003)
sowie der Anforderungs-Datenbank (DST004) protokolliert
bzw. statistisch erfasst werden. Beides zusammen ermöglicht
z.B. einen Überblick über alle auf der Anforderungsdatenbank
(DST004) abgespeicherten Anforderungen im Vergleich
zu den tatsächlich in einem bestimmten Zeitraum
ausgeführten Anforderungen, wobei auch fehlerhafte
Ausführungen erfasst werden. Eine solche Statistik über
Statistiken kann dann einen ASS-Administrator bei der Pflege
der Anforderungsdatenbank gezielt unterstützen.
Die mitgeführten Daten können mit Hilfe des BATCH-Programmes PCL1054 zu externen Schnittstellensätzen verarbeitet werden, die über die Programme der Folgeeinspeicherung in ein spezielles ASS-Arbeitsgebiet eingespeichert werden können.
Ebenso können die Inhalte der Steuerungs-Datenbank und der Anforderungs-Datenbank von PCL1054 auf externe Schnittstellen für das Statistik-Arbeitsgebiet abgebildet werden (siehe Dokumentation von PCL1054).
Dieses Statistik-Arbeitsgebiet besitzt eigene Schlüssel und Werte. Jede ASS-Auswertung wird zu einem bestimmten Zeitpunkt ausgeführt. Der Monat dieses Zeitpunkts wird generell für den ZEITRAUM des Statistik-Arbeitsgebiets hergenommen.
Das Statistik-Arbeitsgebiet besitzt einen Funktionsumfang, der sich nach den dort verwalteten Werten gliedern lässt:
- SCHLUESSEL-STATISTIK (der Wert ANZAHL_KEANF)
(Nutzungs-Statistik der in den Anforderungen verwendeten
Schlüssel)
Hier wird gezählt, wie oft ein Schlüssel in einer Anforderung vom Benutzer ausgewertet wurde. Standardmäßig werden in Joinanforderungen angeforderte Schlüssel nicht mitprotokolliert, da sie ja schon in der jeweiligen Unteranforderung protokolliert werden. Sollen sie trotzdem protokolliert werden, ist auf der Textdatenbank der Schalter STAT-JOIN-KEYS=J zu setzen. Die Zählung erfolgt mittels des Wertes ANZAHL_KEANF, der als Wert des Statistik-Arbeitsgebietes einzurichten ist (vgl. Handbuch 'Einrichten eines Arbeitsgebietes' und Handbuch 'Installation').
Die Zählung des Wertes ANZAHL_KEANF wird aufgeschlüsselt nach folgenden Kriterien (Schlüsselbezeichnung in Großbuchstaben):- der UMGEBUNG, in der die Anforderung ausgeführt wurde: BATCH bei den Programmen PCL1003, PCL1016 und PCL1019, ONLINE bei ST31, AXCEL und ASSINTERNET
- dem ANFORDERUNGSNAMEn (Name der Anforderung auf der Anforderungsbibliothek, falls vorhanden)
- dem ANFORDERER (d.h. Schlüsselbegriff, mit dem die ASS-Security zugeordnet wird, i.a. Personalnummer, Sachbearbeiternummer, etc.; entspricht dem BENUTZER in der ST09 bzw., falls direkt angemeldet, dem Berechtigungsprofil)
- dem PROFIL (das bei der Auswertung verwendete Berechtigungsprofil, ggf. also gleich dem ANFORDERER)
- der ARBEITSGEBIETsnummer
- der SCHLUESSELnummer (5-stellig)
- der BIART (Bibliotheksart der schlüsselenthaltenden Anf.)
- dem BITYP (A: normale Anf., J: Joinanforderung, V: verkettete Anforderung)
- dem AUSFUEHRUNGSDATUM der schlüsselenth. Anforderung
- der AUSFUEHRUNGSZEIT der schlüsselenth. Anforderung
- dem HAUPTPROGRAMM (aufrufende Plattform, s.u.)
- der TIEFE (hier entweder '00' oder, seit ASS 8.30, 'U#'; mit U# werden Schlüssel gekennzeichnet, die in Unteranforderungen von Joinanforderungen angefordert sind oder, bei verketteten Anforderungen, in einer Vorgängeranforderung; Schlüssel mit 'U#' sind also im Anforderungsergebnis nicht sichtbar; interessant, um die Anforderung von datenschutzkritischen Schlüsseln zu untersuchen)
- WERTE-STATISTIK (der Wert ANZAHL_ANF)
(Nutzungs-Statistik der in den Anforderungen verwendeten
Werte)
Hier wird gezählt, wie oft Werte und Verdichtungsstufen in einer Anforderung von einem Benutzer ausgewertet wurden. Die Zählung erfolgt mittels des Wertes ANZAHL_ANF, der als Wert des Statistik-Arbeitsgebietes einzurichten ist.
Die Zählung des Wertes ANZAHL_ANF wird aufgeschlüsselt nach folgenden Kriterien (Schlüsselbezeichnung in Großbuchstaben):
- der UMGEBUNG, in der die Anforderung ausgeführt wurde (s. o.)
- dem ANFORDERUNGSNAMEn (s. o.)
- dem ANFORDERER (s. o.)
- dem PROFIL (s. o.)
- der ARBEITSGEBIETsnummer
- der VERDICHTUNGsstufennummer (Arbeitsgebietsnummer, gefolgt von 5 Stellen Verdichtungsstufennummer)
- der WERTENUMMER (5-stellig)
- der BIART (Bibliotheksart der wertenthaltenden Anf.)
- dem BITYP (s. o.)
- dem AUSFUEHRUNGSDATUM der wertenth. Anforderung
- der AUSFUEHRUNGSZEIT der wertenth. Anforderung
- dem HAUPTPROGRAMM (s. o.)
- BESTANDS-STATISTIK (der Wert ANZAHL_DA)
Auf den Wert ANZAHL_DA werden alle in der Anforderungs-Datenbank existierenden Anforderungen, Formeln, Schlüssel-Gruppierungen, Werte-Gruppierungen und Anwendungen abgebildet.
Die Zählung des Wertes ANZAHL_DA wird aufgeschlüsselt nach folgenden Kriterien (Schlüsselbezeichnung in Großbuchstaben):
- der UMGEBUNG (='DST004')
- der BIART (s.o.)
- dem ANFORDERUNGSNAMEn (s.o.)
- dem BITYP (s.o.)
Auf den Wert ANZAHL_DA werden alle in der Steuerungs-Datenbank vorhandenen Werte, zu denen Daten eingespeichert sind, und alle ableitbaren Werte abgebildet.
Die Zählung des Wertes ANZAHL_DA wird aufgeschlüsselt nach folgenden Kriterien (Schlüsselbezeichnung in Großbuchstaben):
- der UMGEBUNG (='DST003')
- der ARBEITSGEBIETsnummer
- der VERDICHTUNGsstufennummer (Arbeitsgebietsnummer, gefolgt von 5 Stellen Verdichtungsstufennummer)
- der WERTENUMMER (5-stellig)
- BESTANDS-STATISTIK (der Wert ANZAHLKEDA)
Auf den Wert ANZAHLKEDA werden alle in der Steuerungs-Datenbank vorhandenen Schlüssel, zu denen Daten eingespeichert sind, abgebildet.
Die Zählung des Wertes ANZAHLKEDA wird aufgeschlüsselt nach folgenden Kriterien (Schlüsselbezeichnung in Großbuchstaben):
- der UMGEBUNG (='DST003')
- der ARBEITSGEBIETsnummer
- der SCHLUESSELnummer (5-stellig)
- STATISTIK UEBER AUFRUFHIERARCHIEN (der Wert ANZAUFRUFE)
(Statistik über Aufrufhierarchien bei Formeln, Schlüssel-
und Wertegruppierungen, verketteten Anf. und Join-Anf.)
Die Zählung des Wertes ANZAUFRUFE wird aufgeschlüsselt nach folgenden Kriterien (Schlüsselbezeichnung in Großbuchstaben):
- der UMGEBUNG (s. o.)
- dem ANFORDERUNGSNAMEn (Name des gerufenen Elements)
- dem ANFORDERER (s. o.)
- dem PROFIL (s. o.)
- der BIART (Bibliotheks-Art des gerufenen Elements)
- der BIARTRUFER (Bibliotheks-Art des rufenden Elements)
- dem BINAMERUFER (Name des rufenden Elements)
- der TIEFE (absolute Differenz der Hierarchietiefen von rufendem Element und gerufenem Element)
- dem AUSFUEHRUNGSDATUM (s. o.)
- der AUSFUEHRUNGSZEIT (s. o.)
- dem HAUPTPROGRAMM (s. o.)
Die Aufrufhierarchien werden umfangreich abgebildet. Dies lässt sich am besten an einem Beispiel erläutern:
A -> B -> C (das Element A ruft B und das Element B ruft C). Es gilt dann A als Rufer von B und C, und B gilt als Rufer von C.
- STATISTIK UEBER FEHLERHAFTE ANFORDERUNGEN
(der Wert ANZAHLFEHL)
Neben den erfolgreich ausgeführten Anforderungen werden auch Anforderungen protokolliert, bei denen während der Ausführung ein Fehler aufgetreten ist. Diese Anforderungen werden im Wert ANZAHLFEHL gezählt.
Die Zählung des Wertes ANZAHLFEHL wird aufgeschlüsselt nach folgenden Kriterien (Schlüsselbezeichnung in Großbuchstaben):
- der UMGEBUNG (s. o.)
- dem ANFORDERUNGSNAMEn (s. o.)
- dem ANFORDERER (s. o., falls bekannt)
- dem PROFIL (s. o., falls bekannt)
- der BIART (s. o.)
- dem BITYP (s. o.)
- dem AUSFUEHRUNGSDATUM (s. o.)
- der AUSFUEHRUNGSZEIT (s. o.)
- dem FEHLERCODE (ASS-Fehlernummer in der Form ASSnnnn)
- dem PROGRAMM_NAMEn (Name des Programms, in dem der Fehler auftrat)
- dem PROGRAMM_RTC (ASS-interner Rückkehrcode)
- dem HAUPTPROGRAMM (s. o.)
Die Schlüssel FEHLERCODE, PROGRAMM_NAME UND PROGRAMM_RTC dienen hauptsächlich dazu, Fehlerhäufungen zu erkennen. Diese Informationen können i.a. nur von Leuten genutzt werden, die über vertiefte ASS-Kenntnisse verfügen.
- ZUSATZINFORMATIONEN FUER ALLE STATISTIKARTEN
Die oben aufgeführten Schlüssel und Werte stehen der ASS-Auswertung zur Verfügung und können daher mit allen Möglichkeiten, die die ASS-Auswertung bietet, bearbeitet werden.
Durch Gegenüberstellung von Schlüssel und Werten, durch Differenzbildungen bzw. Spaltenbedingungen lassen sich zahlreiche Fragestellungen beantworten:- Welche Schlüssel und Werte werden wann, von wem wie häufig benutzt ?
- Welche Anforderungen, Arbeitsgebiete etc. stehen zur Verfügung ?
- Welche Anforderungen, Schlüsselgruppierungen etc. werden selten oder gar nicht benutzt ?
- Welche Anforderungen wurden fehlerhaft ausgeführt ?
- Bei hierarchischen Konstellationen:
- Welche Elemente werden wo benutzt ?
- Welche Elemente benutzen was ?
Weiter unten sollen einige einfache Beispiele hierzu Anregung geben.
Besonderheiten:
Anwendungen:
Werden Anforderungen in einer Anwendung ausgeführt, so
wird der Schlüssel S24 (s.u.) mit der aktuellen
Anwendungsnummer belegt, sonst mit "00000". D.h. die oben genannten
Statistiken lassen sich in diesem Fall um die
Anwendungsnummer erweitern.
In der Statistik der Aufrufhierarchien werden bei Anwendungen
nur die gerufenen Anforderungen protokolliert, um nicht zu
viele Datensätze entstehen zu lassen.
CPU-ZEIT:
Die verbrauchte CPU-Zeit wird nur erfasst, wenn dies in
der betreffenden ASS-Installation überhaupt möglich ist
und zusätzlich diese Möglichkeit aktiviert ist.
CPU-Zeit wird stets der Anforderung auf höchster
Ebene zugeordnet. Z.B. bei Join-Anforderung werden i.a.
mehrere elementare Anforderungen ausgeführt; die CPU-Zeit
wird nicht den einzelnen Anforderungen, sondern der
Join-Anforderung selbst zugeordnet.
Fehlerhaften Ausführungen von Anforderungen wird keine
CPU-Zeit zugeordnet.
Nach den Kriterien und der Zählung innerhalb der genannten
Teilgebiete ergeben sich für das Statistik-Arbeitsgebiet
folgende Schlüssel und Werte:
SCHLUESSEL
| Name | Erklärung | |
|---|---|---|
| S1 | UMGEBUNG | Umgebung, in der die Anforderung
erfolgte: - Ausprägung 'BATCH' bei den Programmen PCL1003/PCL1016/PCL1019 - Ausprägung 'ONLINE' bei ST31, AXCEL, ASSINTERNET - Ausprägung 'DST003' bzw. 'DST004' für Informationen aus der Steuerungs-DB bzw. Anforderungs-DB |
| S2 | ANFORDERUNGSNAME | Anforderungsname (Name der Anforderung in der Anforderungsbibliothek) |
| S3 | ANFORDERER | Hängt von der Anmeldung des ausführenden Users ab: Wenn als "Benutzer" im Sinne der ST09 angemeldet, dann dessen Name. Wenn die Anmeldung ohne Benutzer erfolgte, also direkt mit einem "Berechtigungsprofil" i.S.d. ST09, dann das Profil. Falls keins von beiden vorhanden, die Ausprägung '000000000000' |
| S4 | ARBEITSGEBIET | Arbeitsgebietsnummern der in der Anforderung verwendeten Arbeitsgebiete |
| S5 | SCHLUESSEL | Schlüsselnummer (5-stellig) der in der Anforderung verwendeten Schlüssel |
| S6 | VERDICHTUNG | Verdichtungsstufennummern der in
der Anforderung verwendeten
Verdichtungsstufen Wegen der Abhängigkeit der Verdichtungsstufen vom zugehörigen Arbeitsgebiet enthalten die Ausprägungen die Arbeitsgebietsnummer gefolgt von 5 Stellen Verdichtungsstufennummer |
| S7 | WERTENUMMER | Wertenummer (5-stellig)
der in der Anforderung verwendeten
Werte Weil sich unter der Betrachtungsweise der Werte-Statistik eine logische Abhängigkeit der Werte von der zugehörigen Verdichtungsstufe und dem zugehörigen Arbeitsgebiet ergeben, wird für die Werte-Statistik ein Bitschlüssel definiert. |
| S8 | BITSCHLUESSEL | Bitschlüssel zu den Werten W1 bis W8 ohne W4 für die getrennte Zählung nach Arbeitsgebieten, Verdichtungsstufen und Werten (d. h. die Schlüssel S4, S6, S7 in dieser Reihenfolge) |
| S9 | OPT_VST_1 | siehe S12 |
| S10 | OPT_VST_2 | siehe S12 |
| S11 | OPT_VST_3 | siehe S12 |
| S12 | OPT_VST_4 | OPT_VST wird nicht mehr unterstützt Die Schlüssel S9 bis S12 gehören logisch zusammen, weil die je 12 Buchstaben der vier Schlüsselinhalte von S9, S10, S11 und S12 zu einem String von 48 Buchstaben zusammengezogen zu betrachten sind. Diese 48 Buchstaben werden in 16 Teile zu je 3 Buchstaben unterteilt. Dieser String von 48 Buchstaben gibt 16 Schlüsselnummern wieder, die mit jeweils 3 Buchstaben in 36-adischer Darstellung aneinandergereiht werden. Die Schlüsselnummern, die in diesem String als Ausprägung in der beschriebenen Weise eingearbeitet werden, beziehen sich auf die optimal ausgeprägten Schlüssel der Anforderungen. Somit gibt es innerhalb des Statistik-Arbeitsgebiets nur einen Sinn die Schlüssel S9, S10, S11 und S12 und den Wert W3 gemeinsam anzufordern. |
| S13 | BIART | Bibliotheksart der Anforderung |
| S14 | BIARTRUFER | Bibliotheksart des Rufers |
| S15 | BINAMERUFER | Anforderungsname des Rufers |
| S16 | BITYP | Anforderungstyp (A: normale Anf., J: Join-Anf., V: verkettes Anf.) |
| S17 | FEHLERCODE | ASS-Fehlercode in der Form ASSnnnn mit der ASS-Fehlernummer nnnn |
| S18 | AUSFUEHRUNGSDATUM | Datum der Ausführung der Anforderung |
| S19 | AUSFUEHRUNGSZEIT | Uhrzeit der Ausführung der Anf. |
| S20 | PROGRAMM_NAME | Name des Programms, in dem ein ASS-Fehler zuerst auftrat |
| S21 | PROGRAMM_RTC | Rückkehrcode dieses Programms |
| S22 | HAUPTPROGRAMM | Aufrufende Plattform (ST31, PCL1003, PCL1016, PCL1019, AXCEL oder HTML (ASS-Internet)) |
| S23 | TIEFE | Absolute Differenz der Hierarchietiefen von rufendem Element und gerufenem Element (relative Tiefe); beim Wert Wert ANZAHL_KEANF zur kennzeichnung nicht sichtbarer Schlüssel verwendet (s.o.) |
| S24 | AWNR | Anwendungsnummer (5-stellig) |
| S25 | PROFIL | Bei der Auswertung benutztes Berechtigungsprofil (ggf. gleicher Inhalt wie beim ANFORDERER, s.o.) |
WERTE:
| Name | Erklärung | |
|---|---|---|
| W1 | ANZAHL_KEANF | Der Wert ANZAHL_KEANF gibt an, wie oft ein Schlüssel in einer Anforderung vom Benutzer verwendet wurde. |
| W2 | ANZAHL_ANF | Der Wert ANZAHL_ANF gibt an, wie oft Werte und Verdichtungsstufen in einer Anforderung vom Benutzer verwendet wurden, also implizit auch, wie oft eine Anf. angefordert wurde |
| W3 | ANZAHL_OPT_ANF | ANZAHL_OPT_ANF wird nicht mehr
unterstützt Der Wert ANZAHL_OPT_ANF gibt an, wie oft die unter der Ausprägungsauswahl der Schlüssel S9 bis S12 gezeigten Schlüssel in den Verdichtungsstufen optimal sind. |
| W4 | CPU_ZEIT | für die Ausführung der Anforderung verbrauchte CPU-Zeit |
| W5 | ANZAHLDA | Anzahl der auf der Anforderungs-Datenbank (DST004) vorhandenen Elemente bzw. der auf der Steuerungs-Datenbank (DST003) verfügbaren Werte |
| W6 | ANZAHLFEHL | Anzahl fehlerhafter Ausführungen von Anforderungen |
| W7 | ANZAHLKEDA | Anzahl der auf der Steuerungs-Datenbank (DST003) verfügbaren Schlüssel |
| W8 | ANZAUFRUFE | Anzahl der Aufrufe von untergeordneten Elementen |
ZEITRAUM:
Der Zeitraum gibt Monat und Jahr an, in dem die jeweilige Statistik angefordert wurde.
Die Schlüsselnummern bzw. Wertenummern für das Statistik-Arbeitsgebiet werden in den Copies SST1106 und SST1106B festgelegt. Diese Nummern können auch als installationsabhängige Variable in der Text-Datenbank eingetragen werden (siehe Handbuch HINSTALL), wobei folgende Zuordnung gilt:
- S1 hat auf der Textdatenbank den Namen KENR-1,
- S2 hat auf der Textdatenbank den Namen KENR-2,
- S3 hat auf der Textdatenbank den Namen KENR-3 usw.
- W1 hat auf der Textdatenbank den Namen WENR-1,
- W2 hat auf der Textdatenbank den Namen WENR-2,
- W3 hat auf der Textdatenbank den Namen WENR-3 usw.
Beispiele für die Statistik-über-Statistik-Anforderung:
- Schlüssel-Statistik:
ASS ; AG: 47; UE: 'STATISTIK UEBER ASS-STATISTIKEN', 'BEISPIEL FUER SCHLUESSEL-STATISTIK'; ZS: UMGEBUNG = (ONLINE,BATCH), ARBEITSGEBIET = (19,40), SCHLUESSEL; SS: WERTE=(ANZAHL_KEANF), ZEITRAUM=(0900-1000); END;Es entsteht folgender Listaufbau:ARBEITSGEBIET: 47: STATISTIK_GEBIET STATISTIK UEBER ASS-STATISTIKEN BEISPIEL FUER SCHLUESSEL-STATISTIK I WERTE I ANZAHL_KEANF I ZEITRAUM I 09.00-10.00 UMGEBUNG ARBEIT SCHLUES I SCHL ------------------------I--------------- ONLINE 19 01901 I 34 01902 I 25 01903 I 17 40 04020 I 23 04021 I 29 I BATCH 19 01901 I 12 40 04020 I 25 04021 I 33 04022 I 53 - Werte-Statistik:
ASS ; AG: 47; UE: 'STATISTIK UEBER ASS-STATISTIKEN', 'BEISPIEL FUER WERTE-STATISTIK'; KS: UMGEBUNG , ANFORDERER=(PCL1003,'097???'), ZEITRAUM = (0900-1000); ZS: ARBEITSGEBIET = (19), WERTENUMMER = ('019!!'); SS: WERTE=(ANZAHL_ANF); END;Es entsteht folgender Listaufbau:ARBEITSGEBIET: 47: STATISTIK_GEBIET STATISTIK UEBER ASS-STATISTIKEN BEISPIEL FUER WERTE-STATISTIK UMGEBUNG: BATCH ANFORDERER: PCL1003 ZEITRAUM: 09.00-10.00 I WERTE I ANZAHL_ANF ARBEIT WERTENU I WE ---------------I--------------- 19 01902 I 23 01903 I 12 01912 I 17 01913 I 66 ARBEITSGEBIET: 47: STATISTIK_GEBIET STATISTIK UEBER ASS-STATISTIKEN BEISPIEL FUER WERTE-STATISTIK UMGEBUNG: ONLINE ANFORDERER: 097??? ZEITRAUM: 09.00-10.00 I WERTE I ANZAHL_ANF ARBEIT WERTENU I WE ---------------I--------------- 19 01902 I 101 01903 I 36 01912 I 76 01913 I 77Schlüssel können hinsichtlich ihrer Verwendung in ausgeführ- ten Anforderungen und ihres Vorhandenseins in Arbeitsgebieten untersucht werden, z.B. mit folgender Statistik: - Schluesselstatistik Verwendung/Bestand
ASS ; AG: 47; UE: 'Schluesselstatistik Verwendung/Bestand'; KS: ZEITRAUM=(0205); SS: WERTE=(ANZAHL_KEANF,ANZAHLKEDA); ZS: SCHLUESSEL; END;Es entsteht folgender Listaufbau (Ausschnitt):ARBEITSGEBIET: 47: STATISTIK Schluesselstatistik Verwendung/Bestand ZEITRAUM: 02.05 I WERTE I ANZAHL_KEAN ANZAHLKEDA SCHLUESSEL I ANZ ANZ -------------+------------------------- 04440 I 0 3 04441 I 0 3 04442 I 0 3 04443 I 0 2 05701 I 17 1 05702 I 21 1 05703 I 0 1 05704 I 0 1 05705 I 6 1u.s.w.Erläuterung: Die Schlüssel 4440 bis 4442 sind in drei Arbeitsgebieten, der Schlüssel 4443 in zwei Arbeitsgebieten vorhanden. Alle vier Schlüssel wurden bislang in keiner ausgeführten Anforderung verwendet.
Die Schlüssel 5701 bis 5705 sind nur in einem Arbeitsgebiet angelegt worden. 5701 wurde bisher 17-mal, 5702 21-mal und 5705 6-mal angefordert, 5703 und 5704 hingegen wurden bislang gar nicht angefordert.
Mit Hilfe dieser oder ähnlicher Statistiken können Schlüssel ausfindig gemacht werden, die z.B. in vielen Arbeitsgebieten angelegt, aber nie angefordert wurden. - Statistik ueber fehlerhafte Anforderungen
ASS ; AG: 47; UE: 'Statistik ueber fehlerhafte Anforderungen'; KS: ZEITRAUM=(0205); SS: WERTE=(ANZAHLFEHL); ZS: AUSFUEHRUNGSZEIT,HAUPTPROGRAMM,BITYP,BIART, ANFORDERUNGSNAME,FEHLERCODE,PROGRAMM_NAME, PROGRAMM_RTC; END;Es entsteht folgender Listaufbau (Ausschnitt):ARBEITSGEBIET: 47: STATISTIK Statistik ueber fehlerhafte Anforderungen ZEITRAUM: 02.05 I WERTE I ANZAHLFEHL AUSFU HAUPTPRO BI BI ANFORDERUNGS FEHLERCO PROGRAMM PR I ANZ -------------------------------------------------------+------------ 11:25 HTML A B LEIERS06 ASS2481 MCL3307 02 I 1 11:31 HTML J B LEIJOIN3 ASS2481 MCL0007 02 I 1 11:44 AXCEL A B LEIERS1F ASS4603 MCL0009 GE I 1 LEIERS2F ASS2351 MCL3307 02 I 1 14:37 AXCEL A B LEIERS2F ASS2351 MCL3307 02 I 1u.s.w.Erläuterung am Bsp. von LEIJOIN3: Diese Join-Anforderung wurde um 11:31 aus ASS-Internet heraus einmal gestartet. Bei der Ausführung wurde der Fehler ASS2481 festgestellt, welcher vom Unterprogramm MCL0007 zusammen mit dem Returncode 02 gemeldet bzw. zurückgegeben wurde. Eine Join-Anforderung gilt dann als fehlerhaft, wenn mind. einer ihrer Bestandteile (selber Anforderungen) fehlerhaft ist (analog gilt dies auch für verkettete Anforderungen).
- Statistik ueber Zustand der Anforderungsdatenbank
ASS ; AG: 47; UE: 'Statistik ueber Zustand der Anforderungsdatenbank'; KS: ZEITRAUM=(0205); SS: WERTE=(ANZAHLDA,ANZAHL_ANF); ZS: BITYP,BIART,ANFORDERUNGSNAME; END;Es entsteht folgender Listaufbau (Ausschnitt):ARBEITSGEBIET: 47: STATISTIK Statistik ueber Zustand der Anforderungsdatenbank ZEITRAUM: 02.05 I WERTE I ANZAHLDA ANZAHL_ANF ANZAHLFEHL BI BI ANFORDERUNGS I ANZ ANZ ANZ -------------------+------------------------------------ A B LEIERS11 I 1 0 0 LEIERS12 I 1 0 0 LEIERS13 I 1 0 0 LEIERS14 I 1 7 0 LEIERS15 I 1 7 0 LEIERS1F I 1 0 1 LEIERS2F I 1 0 2 LEIERSL1 I 1 1 0 LEIERSPC I 1 1 0u.s.w.Erläuterung: Man erkennt nun leicht, dass LEIERS11, LEIERS12 und LEIERS13 bisher nie ausgeführt wurden und dass LEIERS1F und LEIERS2F fehlerhaft ausgeführt worden sind mit 1 bzw. 2 Ausführungsversuchen. Die anderen Anforderungen sind fehlerfrei und mindestens einmal ausgeführt worden.
- Statistik über Aufrufhierarchien
ASS ; AG: 47; UE: 'Aufrufhierarchie, sortiert nach rufenden Elementen'; KS: ZEITRAUM=(0205); SS: WERTE=(ANZAUFRUFE); ZS: BIARTRUFER,BINAMERUFER,BIART=(R),ANFORDERUNGSNAME, TIEFE; END;Es entsteht folgender Listaufbau:ARBEITSGEBIET: 47: STATISTIK Aufrufhierarchie, sortiert nach rufenden Elementen ZEITRAUM: 02.05 I WERTE I ANZAUFRUFE BI BINAMERUFER BI ANFORDERUNGS TI I ANZ -----------------------------------+------------- B LEIERS06 R LEIW 02 I 1 LEIW2 01 I 1 LEIW3 03 I 1 R LEIW R LEIW3 01 I 1 LEIW2 R LEIW 01 I 1 LEIW3 02 I 1Erläuterung: Die Anforderung LEIERS06 ruft die Wertegruppierung LEIW2 direkt (relative Tiefe ist 1) und die Wertegruppierungen LEIW und LEIW3 mittelbar (relative Tiefen sind 2 und 3) auf. Die Wertegruppierung LEIW2 ruft LEIW direkt (relative Tiefe ist 1) und LEIW3 indirekt (relative Tiefe ist 2) auf. Die Wertegruppierung LEIW ruft nur LEIW3 auf und zwar direkt (relative Tiefe ist 1).
Aus der Gesamtinformation lässt sich folgende Aufrufhierarchie ableiten: LEIERS06 -> LEIW2 -> LEIW -> LEIW3.ASS ; AG: 47; UE: 'Aufrufhierarchie, sortiert nach gerufenen Elementen'; KS: ZEITRAUM=(0205); SS: WERTE=(ANZAUFRUFE); ZS: BIART=(U),ANFORDERUNGSNAME,BIARTRUFER,BINAMERUFER, TIEFE; END;Es entsteht folgender Listaufbau:
ARBEITSGEBIET: 47: STATISTIK Aufrufhierarchie, sortiert nach gerufenen Elementen ZEITRAUM: 02.05 I WERTE I ANZAUFRUFE BI ANFORDERUNGS BI BINAMERUFER TI I ANZ -----------------------------------+------------- U 00100LE2 B LEIERS06 01 I 1 00105LE1 B LEIERS06 02 I 1 U 00105LES 01 I 1 00105LE2 B LEIERS06 03 I 1 U 00105LE1 01 I 1 00105LES 02 I 1 00105LE3 B LEIERS06 04 I 1 U 00105LE1 02 I 1 00105LE2 01 I 1 00105LES 03 I 1 00105LE4 B LEIERS06 05 I 1 U 00105LE1 03 I 1 00105LE2 02 I 1 00105LE3 01 I 1 00105LES 04 I 1 00105LES B LEIERS06 01 I 1 00105LM1 B LEIERS06 03 I 1 U 00105LE1 01 I 1 00105LES 02 I 1 00105LM2 B LEIERS06 05 I 1 U 00105LE1 03 I 1 00105LE2 02 I 1 00105LE3 01 I 1 00105LES 04 I 1Erläuterung: Die Schlüsselgruppierung 00105LM1 wird z.B. von der Anforderung LEIERS06 mittelbar (relative Tiefe ist 3), von der Schlüsselgruppierung 00105LE1 direkt (relative Tiefe ist 1) und von der Schlüsselgruppierung 00105LES indirekt (relative Tiefe ist 2) aufgerufen. Die dargestellte Gesamtinformation liefert folgende Aufrufhierarchien:
LEIERS06 -> 00100LE2,
LEIERS06 -> 00105LES -> 00105LE1 -> 00105LE2 -> 00105LE3 -> 00105LE4,
LEIERS06 -> 00105LES -> 00105LE1 -> 00105LM1,
LEIERS06 -> 00105LES -> 00105LE1 -> 00105LE2 -> 00105LE3 -> 00105LM2.
8.5 Ableitbare Werte
Bei der Definition von Werten reicht es aus, nur die elementaren Werte ins ASS zu übernehmen. Werte, die sich aus diesen elementaren Werten herleiten lassen, können über Werteformeln ermittelt werden.
Beispiel:
elementare Werte: BRUTTO_ABSATZ, RABATT
NETTO_ABSATZ = BRUTTO_ABSATZ - RABATT
Diese herleitbaren Werte müssen also nicht abgespeichert werden und benötigen daher keinen Platz auf den Summendatenbanken.
Ist dieser herleitbare Wert (wie z. B. NETTO_ABSATZ) ein häufig verwendeter Wert, so bedeutet dies, dass in den Anforderungen immer mit Formeln gearbeitet werden muss. Werden zusätzliche Angaben dazu benötigt, wie z. B. Zeitangaben beim Wert oder Schlüsselbedingungen zum Wert, müssen die Formeln zusätzlich noch entsprechend modifiziert werden. Dies bedeutet, dass nur eingeschränkt Standardformeln aus der Formelbibliothek verwendet werden können.
Deswegen besteht die Möglichkeit, einen sogenannten ableitbaren Wert in der Wertedatenbank (via Transaktion ST06) zu definieren und in Arbeitsgebiete aufzunehmen. Ein ableitbarer Wert wird nicht in den Summendaten abgelegt, lässt sich aber in der Auswertung wie ein echter Wert ansprechen und auswerten. Die Regel, mit der dieser Wert hergeleitet werden kann, wird in einer Formel abgelegt. Diese Formel wird aber nicht mehr explizit in die Anforderung übernommen.
Da ein ableitbarer Wert nicht in den Summendaten gepflegt wird, darf er auch nicht in den externen Schnittstellen angeliefert werden.
ACHTUNG:
In der Auswertung bewirken ableitbare Werte eine Verschlechterung
der Performance. Deswegen sollte nicht jede Größe, die sich aus
elementaren Werten herleiten lässt, als ableitbarer Wert
festgelegt werden. Das ist nur sinnvoll, wenn es eine häufig
gebrauchte Größe ist, die in sehr vielen Statistiken benötigt
wird. In den anderen Fällen empfehlen wir, mit expliziten
Formeln in der Anforderung zu arbeiten.
Ein ableitbarer Wert lässt sich in einer Anforderung nur auswerten, wenn jeder elementare Wert, der zur Herleitung benötigt wird, für sich in der Anforderung auswertbar ist.
8.6 Verkettete Schlüssel
ASS-Schlüssel der internen Länge 1 können bis zu 250 und solche der internen Länge 2 bis zu 65500 Ausprägungen verwalten. Der Grund dafür liegt in der internen Darstellung zur Speicherung in den Summendaten (verdichteter Inhalt). Die Verwaltung von Massenschlüsseln, wie etwa Versicherungsschein-, Kunden- oder Produktnummer mit mehr als 65500 Ausprägungen kann in diesem Rahmen nicht gelöst werden.
Für die Übernahme solcher Begriffe aus den Stammdaten des operativen Systems bietet ASS zwei generell verschiedene Lösungen an:
- Möglichkeit:
Verkettete Schlüssel
Es besteht die Möglichkeit, den Begriff in mehrere ASS-Schlüssel aufzuteilen und zu verketten (siehe auch Handbuch ST06, Kap. 6, Schlüsselrelation). Dabei wird er in Statistiken wieder zusammenhängend dargestellt.Beispiel
Der Begriff Versicherungschein ist 13-stellig und besitzt 1.500.000 Ausprägungen. In ASS legt man z. B. 3 Schlüssel an, wobei die Inhalte des ersten Schlüssels die ersten 5 Stellen des Versicherungsscheins, die Inhalte des zweiten die Stellen 6 bis 9 und die Inhalte des dritten Schlüssels die letzten vier Stellen sind.
Die installationsabhängig bestehende Grenze der maximalen Schlüssellänge kann also mittels einer Verkettung umgangen werden. ( Standardmäßig liegt diese Grenze bei 12 Zeichen, sie kann installationsabhänging in einer COBOL-Installation auf bis zu 50 Zeichen erhöht werden.)
Bei den verketteten Schlüsseln ist zu beachten, dass die Verkettung nur in der Auswertung zum Tragen kommt. Dazu müssen die Schlüssel entsprechend angefordert werden (s. Handbuch AUSWER- TUNG, Kap. 4.3.13). Bei der Einspeicherung, bei Reorganisationen und in der Transaktion ST06 ist die Verkettung nicht bekannt, d. h. die einzelnen Schlüssel werden unabhängig voneinander behandelt.
- Möglichkeit:
Schlüssel der internen Länge 3 und 4
Andererseits kann ein Begriff mit vielen Ausprägungen im ASS als sogenanter Massenschlüssel abgebildet werden. Dabei gelten folgende Grenzen:
Schlüssel der internen Länge max. Anzahl Ausprägungen 3 16 Millionen 4 900 Millionen Wertung
Bezüglich der Auswertung von Verketteten Schlüsseln bestehen noch gewisse Restriktionen (z.B. Anforderung im Spaltenbereich Schlüsselbedingungen beim Wert). Diese Einschränkungen entfallen zwar bei den Schlüsseln der internen Länge 3 und 4, erstere verhalten sich aber bei der Auswertung performanter (geringerer Zeitbedarf).
8.7 Sichten
Es gibt Situationen, in denen in einem Arbeitsgebiet bestimmte Werte mit bestimmten Schlüsseln keine sinnvolle Aussage ergeben (z.B. der Wert GEZAHLTE_PRAEMIE zusammen mit dem Schlüssel SCHADENURSACHE). Gibt es in einem Arbeitsgebiet derartige Situationen, so können die "sinnvollen" Kombinationen von Schlüssel und Werten auf "Sichten" abgebildet werden. Eine Sicht ist dabei eine Menge von Schlüsseln und Werten eines Arbeitsbebiets. In einem Arbeitsgebiet darf es mehrere Sichten geben. Gibt es in einem Arbeitsgebiet Sichten, so müssen alle Schlüssel und Werte einer ASS-Anforderung, die sich auf das betreffende Arbeitsgebiet beziehen, vollständig in einer Sicht enthalten sein, anderfalls wird die betreffende Anforderung als fehlerhaft abgewiesen.
Sichten werden mit Hilfe der ST06 definiert. Hierzu sind Verdichtungsstufen mit der Art "S" anzulegen. Jede Verdichtungsstufe der ART "S" definiert eine Sicht. Die in dieser Verdichtungsstufe ausgeprägten Schlüssel legen die Menge der Schlüssel der betreffenden Sicht fest. Die Werte der betreffenden Sicht werden mit Hilfe von verwendeten Werten in der betreffenden Verdichtungsstufe (Sicht) beschrieben. Alle verwendeten Werte dieser Verdichtungsstufe bilden die Menge der Werte der betreffenden Sicht.
Verschiedene Sichten eines Arbeitsgebiets dürfen sich bzgl. ihrer Schlüssel- bzw. Werte-Mengen überschneiden.
8.8 Aliasschlüssel
Es gibt mitunter Schlüssel, die im Prinzip gleich sind, jedoch unterschiedliche Datensichten ermöglichen sollen, z.B. bei Versicherungen betreuende Bezirksdirektion im Vergleich zur abschließenden Bezirksdirektion. Diese Schlüssel haben in Grunde die gleichen Schlüsselausprägungen. Um eine Mehrfachwartung dieser Schlüssel zu vereinfachen, gibt es sogenannte Aliasschlüssel. Aliasschlüssel werden durch Verweise von einem Schlüssel auf einen anderen dargestellt.
Bei einem Schlüssel kann daher ein Verweis auf einen anderen Schlüssel angegeben werden. Dieser Verweis muss einer der folgenden Typen sein.
- '1': Es werden auch die ST31-Gruppierungen des Schlüssels, auf den verwiesen wird, angeboten bzw. akzeptiert. Hierduch kann eine Mehrfachverwendung von ST31-Gruppierungen erreicht werden. Dieser Typ ist die schwächste Form eines Verweises.
- '2': wie '1'. Zusätzlich werden Schlüsselinhaltsbezeichnung und Schlüsselinhaltsabkürzung von dem Schlüssel gelesen, auf den verwiesen wird. Schlüsselinhaltsbezeichnung bzw. Schlüsselinhaltsabkürzung brauchen dann nur an einer Stelle gepflegt zu werden. Es sind jedoch u.U. zusätzliche Zugriffe zur Schlüssel-DB erforderlich (Performance).
- '3': echter Alias: wie '1'. Ebenso werden die Schlüsselausprägungen und damit auch die Eigenschaften 'externe Länge' und 'interne Länge' von dem Schlüssel genommen, auf den verwiesen wird. Ein Schlüssel mit Verweis-Typ '3' hat daher i.a. keine Schlüssel-Ausprägungen. Hat er doch welche, so werden diese ignoriert.
Die Verweis-Typen '1' und '2' sind dazu gedacht, auch bei bereits existierenden Arbeitsgebieten Eigenschaften von Schlüsseln mehrfach zu nutzen. Der Verweis-Typ '3' kann nur beim Neuaufbau von Arbeitsgebieten genutzt werden, da bei verschiedenen Schlüsseln mit gleichen Schlüsselausprägungen die Zuordnung Schlüsselinhalt zu verdichtetem Schlüsselinhalt i.a. nicht gleich ist.
Alias-Schlüssel dürfen bei Sonderschlüsseln nicht verwendet werden (KENR-PARAM-ONLINE, KENR-PARAM-BATCH, KERN-PARAM-ANWENDUNG KENR-MONAT und KENR-ZEIT), ebenso nicht in Hierarchieketten (siehe SST2076). D.h. die genannten Schlüssel dürfen nicht auf andere Schlüssel verweisen und umgekehrt darf nicht auf sie verwiesen werden.
8.9 Tages-Arbeitsgebiete, Folgesätze auf der Summen-Datenbank
Standardmäßig wird in einem ASS-Arbeitsgebiet die ASS-Zeit auf Monatsbasis verwaltet. Man kann aber auch einem Arbeitsgebiet die Eigenschaft geben, die ASS-Zeit auf Tagesbasis zu verwalten. Man spricht dann von Monats-Arbeitsgebieten bzw. Tages-Arbeitsgebieten. Monats- bzw. Tagesbasis ist eine Arbeitsgebiets-Eigenschaft.
In einem Tages-Arbeitsgebiet hat jeder Monat 32 Tage. Auf den 32. Tag können z.B. endgültige Monatsabschlüsse gebucht werden (analog zu der Tatsache, dass ein Arbeitsgebiet mehr als 12 Monate haben kann).
Werden Tagesarbeitsgebiete eingerichtet, so hat dies vielfältige Konsequenzen. Insbesondere müssen externe Schnittstellen dann Daten mit Tag bei der ASS-Zeit anliefern.
Eine wesentliche Konsequenz erfährt die Behandlung von Summensätzen. Bei Tages-Arbeitsgebieten muss davon ausgegangen werden, dass in einem Summensatz deutlich mehr Wert-/Zeitkombinationen gespeichert werden müssen als in Monats-Arbeitsgebieten. Summensatze werden daher bei Tages-Arbeitsgebieten sehr schnell lang und stoßen an Systemgrenzen (z.B. maximale Satzlänge). Daher werden in Tages-Arbeitsgebieten Summensätze gesplittet. Eine logische Schlüsselkombination wird auf mehrere physikalische Summensätze verteilt. Um dies möglich zu machen, wird im Key der Summensätze ein zusätzliches Byte benutzt, um die physischen Summensätze, die zu einer Schlüsselkombination gehören, durchzuzählen. Dieses Byte wird im Key ganz rechts angeordnet. Es wird binär von 0 beginnend gezählt. Ein logischer Summensatz kann somit auf maximal 255 physische Summensätze aufgeteilt werden.
In Tages-Arbeitsgebieten gilt
Länge des SU-DB-Keys = 2 + Summe interner Schlüssellängen + 1
Bestehende Monats-Arbeitsgebiete können auf Tages-Arbeitsgebiete umgestellt werden. Dies erfordert jedoch eine einfache Reorganisation. Einzelheiten hierzu siehe Handbuch Betrieb2 bei PCL1011.
Die Auswertung von Tages-Arbeitsgebieten erfolgt analog zu Monats-Arbeitsgebieten. Besonders interessant ist die gemeinsame Auswertung von Tages- und Monats-Arbeitsgebieten (Mischkonstellation). Dies wird im Rahmen der Auswertung dokumentiert.
Die Aufteilung einer logischen Schlüsselkombination auf
mehrere physische Summensätze kann auch in Monats-Arbeitsgebieten
genutzt werden. Hierzu muss dem betreffenden Monats-Arbeitsgebiet
die Eigenschaft zugeordnet werden, Summensätze splitten zu können.
Soll bestehenden Monats-Arbeitsgebieten diese Eigenschaft
zugeordnet werden, so ist analog zur Umstellung von Monats- auf
Tagesarbeitsgebiete eine einfache Reorganisation erforderlich.
Die genannte Eigenschaft reduziert das gelegentlich auftretende
Problem zu langer Summensätze deutlich.
8.10 Protokoll-Arbeitsgebiet
In ASS besteht die Möglichkeit, wesentliche Daten aus
Ablaufprotokollen von Batch-Programmen in einem sogenannten
Protokoll-Arbeitsgebiet zu verwalten.
Es werden nicht alle Batch-Programme unterstützt, sondern
nur die, die "wesentliche" Änderungen an ASS-Datenbanken
vornehmen.
Das Protokoll-Arbeitsgebiet soll es erleichtern,
Batch-Abläufe zu kontrollieren bzw. Protokolle verschiedener
Batch-Programme gegeneinander abzugleichen.
Im einzelnen werden folgende Programme unterstützt:
- PCL1001
- PCL1002
- PCL1005
- PCL1007
- PCL1011
- PCL1013
- PCL1015
- PCL1024
- PCL1032
- PCL1036
- PCL1042
- PCL1043
- PCL1045
- PCL1051
- PCL1055
- PCL1058
- PCL1124
Die Pflege eines Protokoll-Arbeitsgebiets ist standardmäßig nicht aktiv. Das Protokoll-Arbeitsgebiet muss explizit eingerichtet werden.
Das unten Gesagte gilt nur, wenn das Protokoll-Arbeitsgebiet aktiv ist.
Damit nicht ständig schreibend auf Datenbanken zugegriffen werden muss und damit korrekte von fehlerhaften Programmläufen getrennt werden können, werden bei allen oben genannten Batch-Programmen drei Arbeitsdateien benutzt: ASSOUT1, ASSOUT2 und ASSOUT3. Alle Dateien sind sequentiell mit variabler Satzlänge, maximale Satzlänge 1004 Byte (einschließlich Satzlängenfeld). Sie enthalten vereinfachte externe Schnittstellen.
Die JCL der oben genannten Programme muss um diese drei Dateien erweitert werden. Bei der Pflege des Protokoll-Arbeitsgebiets gibt es zwei grundsätzliche Methoden:
- Die oben genannten Programme schreiben die zu protokollierenden Daten in die drei genannten Arbeitsdateien. Diese Arbeitsdateien werden mit einem eigenen Programm (PCL1177) in einem eigenen Step verarbeitet. In dieser Variante gibt es dann keine zusätzlichen schreibenden Zugriffe auf ASS-Datenbanken (von dem ursprünglichen Programm). Es müssen jedoch die Arbeitsdateien sauber an PCL1177 weitergereicht werden. PCL1177 führt dann die entsprechenden Folgeeinspeicherungen für das Protokoll-Arbeitsgebiet durch.
- Das Protokoll-Arbeitsgebiet wird sofort gepflegt.
Es werden dann praktisch während eines Batch-Programmlaufs
mehrere kleine Folgeeinspeicherungen in das
Protokoll-Arbeitsgebiet durchgeführt.
Auch in diesem Fall werden die drei genannten
Arbeitsdateien benutzt.
Genau genommen werden drei Folgeeinspeicherungen
durchgeführt:
- Am Programmanfang wird der aktuelle Programmlauf als fehlerhaft verbucht.
- Am Programmende werden alle sonstigen Protokolldaten verbucht.
- Ist am Programmende noch kein Fehler aufgetreten, so wird der aktuelle Programmlauf als korrekt verbucht (Gegenbuchung zur ersten Folgeeinspeicherung).
Welche der beiden Methoden verwendet wird, wird installationsabhängig durch die Text-DB via PROT-AG-SOFORT = J/N festgelegt. Voreingestellt ist PROT-AG-SOFORT = N (Text-DB-Name: PROT-AG-SOFORT, Text-DB-Nummer: 110). Pro Batch-Programmlauf kann die gewählte Methode durch die Vorlaufkarten-Angabe PROT_AG_SOFORT = J/N übersteuert werden.
Die zweite Methode (sofortige Pflege des Protokoll-Arbeitsgebiets) ist i.a. nicht empfehlenswert, da es insbesondere bei fehlerhaften Programmläufen oder bei Programmabbrüchen i.a. nicht möglich ist, die Wirksamkeit der DB-Updates auf das Protokoll-Arbeitsgebiet bzw. der "eigentlichen" DB-Updates sauber zu trennen (Ein Checkpoint z.B. fixiert alle DB-Updates). Ebenso ist es schwierig, bei Programmabbrüchen Datenbanken zurückzusetzen und dabei die Konsistenz des Protokoll-Arbeitsgebiets zu erhalten.
Tritt bei der zweiten Methode während des Programmlaufs ein Fehler auf, so wird auf die erste Methode umgeschaltet. Hierdurch soll verhindert werden, dass durch das Protokoll-Arbeitsgebiet irgendwelche DB-Updates fixiert werden (z.B. durch Schreiben eines Checkpoints). Da auch in diesem Fall die Protokolldaten noch in den Work-Dateien ASSOUT1, ASSOUT2 bzw. ASSOUT3 enthalten sind, können sie, falls gewünscht, anschließend (nachträglich) noch mit PCL1177 verbucht werden.
Bei der ersten Methode kann im Einzelfall leicht auf die Pflege des Protokoll-Arbeitsgebiets verzichtet werden. Nach dem "eigentlichen" Programmlauf reicht es, die Work-Dateien ASSOUT1, ASSOUT2 und ASSOUT3 zu löschen und auf das Verbuchen mit PCL1177 zu verzichten.
Formaler Aufbau des Protokoll-Arbeitsgebiets:
Das Protokoll-Arbeitsgebiet muss wie ein "normales" Arbeitsgebiet eingerichtet werden. Arbeitsgebietsnummer, Schlüssel- und Wertenummern werden installationsabhängig via Textdatenbank festgelegt. Arbeitsgebiet, Schlüssel und Werte müssen mit der ST06 erfasst (definiert) werden.
Die Arbeitsgebietsnummer wird festgelegt durch
Text-DB-Name: PROT-AG-AGNR Text-DB-Nummer: 110
(z.B. PROT-AG-AGNR = 55)
Das Protokoll-Arbeitsgebiet ist ein Tages-Arbeitsgebiet, der Startzeitpunkt des Batch-Programmlaufs wird auf die ASS-Zeit abgebildet.
Das Protokoll-Arbeitsgebiet enthält folgende Schlüssel:
- Programm-Name (z.B. PCL1001)
Text-DB-Name: PROT-AG-KENR-PGM Text-DB-Nummer: 111
(z.B. PROT-AG-KENR-PGM = 4711)
Externe Länge: 8, Interne Länge: 1 - Startzeitpunkt des Programms (HH:MM)
Text-DB-Name: PROT-AG-KENR-TME Text-DB-Nummer: 111
Externe Länge: 5, Interne Länge: 2 - Vorgangsart (z.B. Erst- oder Folgeeinspeicherung)
Text-DB-Name: PROT-AG-KENR-VA Text-DB-Nummer: 111
Externe Länge: 12, Interne Länge: 2 - Arbeitsgebietsnummer
Text-DB-Name: PROT-AG-KENR-AGNR Text-DB-Nummer: 111
Externe Länge: 5, Interne Länge: 2 - Schlüsselnummer
Text-DB-Name: PROT-AG-KENR-KENR Text-DB-Nummer: 111
Externe Länge: 5, Interne Länge: 2 - Wertenummer
Text-DB-Name: PROT-AG-KENR-WENR Text-DB-Nummer: 111
Externe Länge: 5, Interne Länge: 2 - Verdichtungsstufennummer
Text-DB-Name: PROT-AG-KENR-CSNR Text-DB-Nummer: 111
Externe Länge: 5, Interne Länge: 2 - Laufende Nummer einer externen Schnittstelle
(wegen Verkettung von externen Schnittstellen)
Text-DB-Name: PROT-AG-KENR-EXNR Text-DB-Nummer: 111
Externe Länge: 5, Interne Länge: 2 - ASS-Zeit einer Kontrollsumme (JJMM bzw. JJMMTT)
Text-DB-Name: PROT-AG-KENR-KTME Text-DB-Nummer: 111
Externe Länge: 6, Interne Länge: 2 - ergänzter Schlüsselinhalt
Text-DB-Name: PROT-AG-KENR-INH Text-DB-Nummer: 111
Externe Länge: installationsabhänge maximale Länge von Schlüsselinhalten, mindestens 12, Interne Länge: 4 - Dateiname (DD-Name bzw. Link-Name oder entsprechendes
Kürzel, z.B. ASSOUNN).
Text-DB-Name: PROT-AG-KENR-DDN Text-DB-Nummer: 111
Externe Länge: 8, Interne Länge: 2 - Versionsnummer (einer Summendatenbank)
Text-DB-Name: PROT-AG-KENR-CARVERS Text-DB-Nummer: 111
Externe Länge: 5, Interne Länge: 2 - Erstelldatum (einer Summendatenbank, JJMMTTHH)
Text-DB-Name: PROT-AG-KENR-CSDAT Text-DB-Nummer: 111
Externe Länge: 8, Interne Länge: 2, werden täglich mehrere Arbeitsgebiete eingespeichert, so sollte über eine interne Länge von 3 nachgedacht werden.
Das Protokoll-Arbeitsgebiet enthält folgende Werte:
- Anzahl Fehler
Text-DB-Name: PROT-AG-WENR-ANZF Text-DB-Nummer: 112 - Gelesene Sätze (insgesamt)
Text-DB-Name: PROT-AG-WENR-GLI Text-DB-Nummer: 112 - Geschriebene Sätze (Insgesamt)
Text-DB-Name: PROT-AG-WENR-GSI Text-DB-Nummer: 112 - Gelesene Sätze (pro Verdichtungsstufe)
Text-DB-Name: PROT-AG-WENR-GLC Text-DB-Nummer: 112 - Geschriebene Sätze (pro Verdichtungsstufe)
Text-DB-Name: PROT-AG-WENR-GSC Text-DB-Nummer: 112 - Gemischte Sätze (pro Verdichtungsstufe)
Text-DB-Name: PROT-AG-WENR-GMC Text-DB-Nummer: 112 - Maximale Satzlänge (pro Verdichtungsstufe)
Text-DB-Name: PROT-AG-WENR-MSL Text-DB-Nummer: 112 - Kontrollsumme
Text-DB-Name: PROT-AG-WENR-KSU Text-DB-Nummer: 112
Da alle Kontrollsummen (von PCL1001) auf einen Wert abgebildet werden, werden sie ohne Kommastellen gespeichert und ausgewertet. - Anz-Ergänzte Schlüsselinhalte
Text-DB-Name: PROT-AG-WENR-AERG Text-DB-Nummer: 112
(i.a. 1) - Anzahl Sort'S
Text-DB-Name: PROT-AG-WENR-ASRT Text-DB-Nummer: 112 - Anzahl Aussagen
Text-DB-Name: PROT-AG-WENR-PGM Text-DB-Nummer: 112
Dieser Wert sorgt dafür, dass Sätze auf der Summen-Datenbank gespeichert werden. Eine numerische Betrachtung macht i.a. keinen Sinn.
Schlüsselinhalte, die nicht sinnvoll belegt werden können, werden mit einem Dummy-Inhalt gefüllt (z.B. Schlüsselnummer: 00000).
Die Protokollierung von Schlüsselinhalten kann via Text-DB aktiviert bzw. deaktiviert werden.
- Text-DB-Name: PROT-AG-MIT-KEINH Text-DB-Nummer: 110
Voreingestellt ist PROT-AG-MIT-KEINH = N.
Das Protokollieren von ergänzten Schlüsselinhalten
kann zu einem großen Datenvolumen führen. Zum einen
muss davon ausgegangen werden, dass für jeden ergänzten
Schlüsselinhalt ein Satz auf der Schlüssel-DB entsteht.
Weiterhin entstehen auch entsprechend viele Summensätze
auf der Summen-DB des Protokoll-Arbeitsgebietes.
Da u.U. nicht immer ergänzte Schlüsselinhalte protokolliert
werden sollen, kann pro Programmlauf via Vorlaufkarte
diese Protokollierung ein- bzw. ausgeschaltet werden:
PROT_AG_MIT_KEINH = J/N (bei PCL1001, PCL1036 und PCL1055).
PCL1055 protokolliert die gelöschten Schlüsselinhalte.
Das Copy SST6677
Da in der Vorlaufkartenbehandlung die Methode der Protokollierung angegeben werden kann (PROT_AG_SOFORT=J/N), erfolgen Protokollausgaben erst nach der Vorlaufkartenbehandlung. Tritt hierbei ein Fehler auf, so erfolgt keinerlei Protokollausgabe.
Soll sichergestellt werden, dass jeder Batch-Programmlauf
protokolliert wird, so kann in diesem Copy angegeben
werden, dass praktisch als erste Maßnahme in den
Arbeitsdateien für das Protokoll-Arbeitsgebiet ein
fehlerhafter Programmlauf vermerkt wird.
Hierdurch wird die zeitliche Lücke zwischen
Programminitialisierungen, Vorlaufkartenbehandlung etc.
und ersten Protokollausgaben geschlossen.
Da zu diesem frühen Zeitpunkt die Methode der Protokollierung
noch nicht feststeht, müssen diese Grundinitialisierungen
mit PCL1177 verbucht werden.
Wird grundsätzlich mit PROT_AG_SOFORT=N gearbeitet,
so empfiehlt sich die beschriebene Grundinitialisierung
mit Hilfe von SST6677.
Das Programm PCL1177
Das Programm PCL1177 verbucht die in den Dateien
ASSOUT1, ASSOUT2 und ASSOUT3 enthaltenen Protokolldaten.
Diese drei Dateien werden gelesen.
Auf ASSLIST wird das übliche Ablaufprotokoll geschrieben.
Es wird schreibend auf die Datenbanken DST001, DST002,
DST003 und die Summen-Datenbank des Protokoll-Arbeitsgebiets
zugegriffen.
Auf die Text-Datenbank (DST007) wird lesend zugegriffen.
PCL1177 führt im Prinzip Folgeeinspeicherungen
(PCL1001 + PCL1002) durch.
8.11 Datenschutzkritische Schlüssel
Mit Einführung des sog. "Code of Conduct: Datenschutz", eines selbstauferlegten Verhaltenskondex hinsichtlich des Umgangs mit personenbezogenen Daten seitens des Gesamtverbandes der Deutschen Versicherungswirtschaft (GDV), entstand die Notwendigkeit, bestimmte ASS-Schlüssel (bzw. deren Inhalte) in Auswertungsergebnissen entweder vollständig oder teilweise unkenntlich zu machen.
Dabei soll die Datenbasis (d.h. die Information auf der Schlüssel-DB und den entsprechenden Summendatenbanken) vollständig erhalten bleiben. Über entsprechende Security-Einstellungen kann für jeden ASS-Benutzer gesteuert werden, ob datenschutzkritische Schlüssel für ihn vollständig, teilweise oder gar nicht anonymisiert werden.
Neben ASS-Schlüsseln können auch Schlüsselrelationen als datenschutzkritisch gekennzeichnet werden. Im Folgenden sei zur Vereinfachung jedoch nur von Schlüsseln die Rede.
Bei einer vollständigen Anonymisierung werden sämtliche Inhalte des entsprechenden Schlüssels im Auswertungsergebnis durch Sterne (*) ersetzt. Bei einer teilweisen Anonymisierung werden nur bestimmte Inhalte eines Schlüssels unkenntlich gemacht. Diese müssen dem ASS über das Batch-Programm PCL1265 mitgeteilt werden. Da dabei für jeden Inhalt dessen Darstellung im Auswertungsergebnis individuell festgelegt werden kann, sprechen wir hier von "Pseudonymisierung". Zur Funktionsweise von PCL1265 siehe Handbuch "Betrieb II", Kap. 8.22.
Wichtig: Die kritischen Inhalte werden nur in der Anzeige anonymisiert bzw. pseudonymisiert! Sie können nach wie vor angefordert werden. Insbesondere ältere Anforderungen, in denen solche Inhalte explizit angesprochen werden, liefern dadurch i.W. dieselben Zahlen wie ohne Anonymisierung, d.h.:
- Die Werte bleiben erhalten
- End- und Zwischensummen bleiben erhalten: Bei teilweiser Anonymisierung werden zwar die pseudonymisierten Inhalte nach hinten sortiert (bei Kopf- und Zeilenschlüsseln), bei angeforderten Zwischensummen aber eben nur ans Ende des aktuellen Blocks (vgl. Beispiel unten)
- Anforderungs-Join: Die Anonymisierung findet nur in der obersten Präsentationsanforderung statt, nicht in den Unteranforderungen
Hierzu ein einfaches Beispiel, zunächst ohne Anonymisierung:
I WERTE
I NEUBEITRAG
NAME SPARTE I EUR
--------------------------+-------------
HUBER KFZ I 100
LEBEN I 150
MAIER KFZ I 200
HPF I 100
* I 550
MUELLER LEBEN I 200
SCHMIDT FEUER I 150
* I 350
** I 900
Selbes Beispiel, Schlüssel NAME wird komplett anonymisiert:
I WERTE
I NEUBEITRAG
NAME SPARTE I EUR
--------------------------+-------------
******** KFZ I 100
LEBEN I 150
******** KFZ I 200
HPF I 100
* I 550
******** LEBEN I 200
******** FEUER I 150
* I 350
** I 900
Selbes Beispiel, Schlüssel NAME wird pseudonymisiert (hier HUBER -> gesperrt und MUELLER -> gelöscht), man beachte die Umsortierung innerhalb der Summenblöcke:
I WERTE
I NEUBEITRAG
NAME SPARTE I EUR
--------------------------+-------------
MAIER KFZ I 200
HPF I 100
gesperrt KFZ I 100
LEBEN I 150
* I 550
SCHMIDT FEUER I 150
gelöscht LEBEN I 200
* I 350
** I 900
Die kritischen Inhalte bleiben zwar anforderbar, jedoch werden sie nicht in den Auswahllisten der Anforderungserstellung oder Parameterbelegung angeboten, es sei denn der Anwender hat die Berechtigung "VC" (s. Handbuch "ST09", Kap. 2.1).
Kennzeichnung datenschutzkritischer Schlüssel
Ein Schlüssel wird als datenschutzkritisch gekennzeichnet, indem er über die Transaktion ST06 das Datenschutz-Level "1" erhält (siehe Handbuch "ST06", Kap. 3.5.2 bzw. 6.5 für Relationen).
Achtung: Schlüssel mit Verweis-Typ "3" erben das Datenschutz-Level des Schlüssels, auf den verwiesen wird!
Für Anwender, die weder die Berechtigung "V1" noch "VA" haben (s. "ST09", Kap. 2.1), wird der Schlüssel vollständig anonymisiert. Für Anwender, die die Berechtigung "V1", nicht jedoch "VA" haben, wird der Schlüssel nur teilweise anonymisiert, d.h. der Anwender sieht bei den mit PCL1265 verarbeiteten Inhalten ggf. nur deren Pseudonyme. Anwender mit Berechtigung "VA" sehen alle Inhalte im Original, d.h. es findet keinerlei Anonymisierung statt.
Darüber hinaus kann in einer Anforderung unabhängig von der Berechtigung des Benutzers verlangt werden, dass alle datenschutzkritischen Schlüssel vollständig anonymisiert werden (ASS-Excel: Unter Zusätze -> Textierung und Allgemeines; ST31: siehe Handbuch "Auswertung", Kap. 8.1). Die Anforderung wird also ausgeführt, als hätte der Benutzer weder Berechtigung "V1" noch "VA".
Bedingte Pseudonymisierung
Ob ein bestimmter Schlüsselinhalt datenschutzkritisch ist oder nicht, hängt mitunter auch von den Inhalten anderer Schlüssel ab.
Hierzu wieder ein einfaches Beispiel:
I WERTE
I NEUBEITRAG
KUNDENNUMMER NAME I EUR
--------------------------+-------------
000000001 HUBER I 100
000000002 MAIER I 200
000000003 SCHMIDT I 150
000000004 MAIER I 175
In diesem Beispiel gibt es zwei (unterschiedliche) Kunden mit Namen "MAIER". Es kann nun z.B. festgelegt werden, dass der Name MAIER nur dann durch das Wort "anonym" ersetzt wird, wenn der Schlüssel KUNDENNUMMER die Ausprägung "000000002" hat, da nur diese hier den Kunden eindeutig identifiziert. Derartige Bedingungen müssen dem ASS ebenfalls via PCL1265 mitgeteilt werden, siehe Handbuch "Betrieb II", Kap. 8.22.
Ein Benutzer mit Berechtigung V1 (nicht VA) würde dann folgendes Bild erhalten:
I WERTE
I NEUBEITRAG
KUNDENNUMMER NAME I EUR
--------------------------+-------------
000000001 HUBER I 100
000000002 anonym I 200
000000003 SCHMIDT I 150
000000004 MAIER I 175
HINWEIS: In PCL1019 gibt es keine bedingte Pseudonymisierung, d.h. die Bedingungen einer Pseudonymisierungsregel gelten immer als erfüllt, d.h. in PCL1019 wäre das Ergebnis:
I WERTE
I NEUBEITRAG
KUNDENNUMMER NAME I EUR
--------------------------+-------------
000000001 HUBER I 100
000000002 anonym I 200
000000003 SCHMIDT I 150
000000004 anonym I 175
ACHTUNG:
Die bedingte Pseudonymisierung ist nur dann möglich, wenn
sowohl der datenschutzkritische Schlüssel (hier NAME) als
auch der Bedingungsschlüssel (hier KUNDENNUMMER) im Kopf-
oder Zeilenbereich angefordert sind. Fehlt der Schlüssel
KUNDENNUMMER oder ist NAME in der Spalte angefordert,
so wird die Ausprägung MAIER grundsätzlich anonymisiert,
hier z.B.:
I WERTE
I NEUBEITRAG
I KUNDENNUMMER
I 000000001 000000002 000000003 000000004
NAME I EUR EUR EUR EUR
------------+-------------------------------------------------
HUBER I 100 0 0 0
SCHMIDT I 0 0 150 0
*********** I 0 200 0 175
Ähnlich verhält es sich, wenn beim Bedingungsschlüssel ein nicht prüfbarer Inhalt steht, z.B. ein Mengen- oder Formelname. Im Beispiel seien die Kundennummern die angezeigten Kundennummern in einer Menge mit Namen ALLE zusammengefasst.
Ohne Pseudonymisierung:
I WERTE
I NEUBEITRAG
KUNDENNUMMER NAME I EUR
--------------------------+-------------
ALLE HUBER I 100
MAIER I 375
SCHMIDT I 150
Mit Pseudonymisierung:
I WERTE
I NEUBEITRAG
KUNDENNUMMER NAME I EUR
--------------------------+-------------
ALLE HUBER I 100
SCHMIDT I 150
*********** I 375
Im obigen Beispiel gibt es zur Vereinfachung nur eine Schlüsselbedingung, die erfüllt sein muss, damit der Inhalt MAIER pseudonymisiert wird, nämlich KUNDENNUMMER = 000000002. Insgesamt können für jeden Inhalt aber bis zu 10 Schlüsselbedingungen formuliert werden, die dann alle erfüllt sein müssen (logische "UND"-Verknüpfung). In diesen Bedingungen können auch Relationen angegeben werden. Ferner können für jeden Inhalt wiederum beliebig viele solcher Pseudonymisierungsregeln formuliert werden. Die (ggf.erste) Regel, die erfüllt ist, bestimmt dann das statt des Inhalts angezeigte Pseudonym.
Beispiel:
- Regel: MAIER -> anonym, wenn KUNDENNUMMER = 000000002 und SPARTE = KFZ
- Regel: MAIER -> gesperrt, wenn KUNDENNUMMER = 000000002 und SPARTE = FEUER
- Regel: MAIER -> ********, wenn KUNDENNUMMER = 000000002 und VERTRAGSNR = 12345
Ohne Pseudonymisierung:
I WERTE
I NEUBEITRAG
KUNDENNUMMER NAME VERTRAGSNR SPARTE I EUR
--------------------------------------------+-------------
000000001 HUBER 54321 KFZ I 100
000000002 MAIER 12345 FEUER I 200
11111 KFZ I 300
22222 HPF I 400
000000003 SCHMIDT 33333 HPF I 150
000000004 MAIER 44444 FEUER I 175
Mit Pseudonymisierung:
I WERTE
I NEUBEITRAG
KUNDENNUMMER NAME VERTRAGSNR SPARTE I EUR
--------------------------------------------+-------------
000000001 HUBER 54321 KFZ I 100
000000002 MAIER 22222 HPF I 400
gesperrt 12345 FEUER I 200
anonym 11111 KFZ I 300
000000003 SCHMIDT 33333 HPF I 150
000000004 MAIER 44444 FEUER I 175
Teilschlüssel von Relationen
Enthält eine Relation einen datenschutzkritischen Schlüssel, hat aber selbst kein Datenschutz-Level, so wird die Relation komplett anonymisiert.
Umgekehrt gilt analog: Ein nicht datenschutzkritischer Schlüssel, der nicht als Teil einer Relation angefordert ist, wird komplett anonymisiert, wenn er in irgendeiner Relation vorkommt, bei der ein Datenschutz-Level gesetzt ist (diese muss nicht angefordert sein!).
Batch-Auswertungen
Bei Batch-Auswertungen mit PCL1003/PCL1016/PCL1019 gelten, falls vorhanden, die Berechtigungen des in der "PR"-Anweisung angegebenen Benutzers (bei PCL1016 i.d.R. der, der zuletzt gespeichert hat). Dann gelten natürlich auch dessen Berechtigungen bzgl. Anonymisierung. Fehlt die "PR"-Anweisung, so wird die Anforderung ohne die Berechtigungen "V1" und "VA" ausgeführt.
Falls gesetzt, gilt natürlich auch hier die Anforderungsoption zur Anonymisierung aller datenschutzkritischen Schlüssel.
Die Anonymisierung kann allerdings auch komplett umgangen werden, indem man statt PCL1016 und PCL1019 die Programme PCL1016A bzw. PCL1019A verwendet. Sie unterscheiden sich lediglich dadurch, dass bei den letzteren nichts anonymisiert wird.
ACHTUNG: Standardmäßig werden PCL1016A und PCL1019A in der Variante ausgeliefert, die die Anonymisierung berücksichtigt, d.h. sie unterscheiden sich nicht von PCL1016 und PCL1019. Die obige Variante erhält man, indem man den Schalter "S2271-OHNE-ANONYM" im Copy SST2271 beim Kompilieren auf 'J' setzt.
8.12 Indexschlüssel und Indexrelationen
Um in ASS-Auswertungen Texte anzeigen zu können, die länger als die Ausprägungsbezeichnungen eines Schlüssels sind, wird i.Allg. das User-Exit-Programm MCL0097 (oder MCL0897) verwendet. Diese ggf. vom ASS-Anwender selbst erstellten Programme weisen den Ausprägungen eines entsprechend angeforderten Schlüssels bis zu 250 Zeichen lange Texte für die Anzeige zu. Diese Zuweisungen "Ausprägung -> Text" sind vom ASS-Administrator anzulegen und zu pflegen, z.B. über das Batch-Programm PCL1231 für den "Standard-User-Exit".
Die sog. "Indexschlüssel" sind gedacht für den speziellen Fall, dass die eigentlichen Ausprägungen eines Schlüssels i.W. für die Anzeige uninteressant sind und nur als Verweise (Indizes) auf die ihnen zugeordneten Texte dienen. Der Schlüssel muss bei der (Folge-)Einspeicherung natürlich mit diesem "Index" versorgt werden, welcher als ASS-Ausprägung auf der Schlüssel-DB gespeichert wird. Bei steigendem Datenvolumen kann es mitunter mühsam sein, die gewünschten Indizes für die Einspeicherung zu bestimmen, insbesondere muss für jeden neuen Index auch der entsprechende Text zugeordnet und diese Zuordnung gespeichert werden (z.B. durch ein Neuladen der Texte-Datenbank mit PCL1231).
Bei einem Indexschlüssel werden diese Aufgaben vom ASS automatisch während der Einspeicherung übernommen:
- In der externen Schnittstelle werden nicht die Schlüsselinhalte angeliefert, sondern die langen Texte.
- PCL1001 sucht jeden Text auf der sog. "Indexdatenbank" und generiert bei neuen Texten einen Schlüsselinhalt (im "klassischen ASS-Sinn"), der eine einfache Zählnummer (Index) darstellt. Die Zuordnung "Index <-> Text" wird auf der Indexdatenbank gespeichert.
- PCL1001 erhält also einen regulären ASS-Inhalt zurück, und die Einspeicherung geht wie gewohnt vonstatten. Das bedeutet z.B., dass neu generierte Indizes natürlich auch als neue Inhalte auf der Schlüsseldatenbank ergänzt werden (wenn beim Schlüssel so eingestellt, was in diesem Fall dringend ratsam ist).
Für das Verfahren müssen vom ASS-Administrator lediglich der/die Indexschlüssel sowie die Indexdatenbank(en) angelegt werden, um den Rest kümmert sich das ASS.
Analog kann auch mit "Indexrelationen" gearbeitet werden, alles Folgende gilt daher gleichermaßen für Schlüssel wie Relationen.
Indexdatenbank anlegen
Für die Indexdatenbank muss eine Arbeitsgebietsnummer reserviert werden, deren Summen-DB dann als Index-DB genutzt wird. Diese ist auf der Text-DB unter D A 109, "TEXT-INDEX-DB-1 = …" anzulegen. Da der DB-Key bei Summen-DBs max. 250 Bytes lang ist, bleiben wegen 3 Bytes für Schlüsselnummer und Satzart noch 247 Bytes für die langen Texte übrig, d.h. die einzuspeichernden Texte dürfen max. 247 Zeichen haben.
Auch wenn die Angabe der TEXT-INDEX-DB-1 theoretisch ausreichen würde, empfiehlt es sich evtl. aus Platzgründen, die Installation ein wenig zu verfeinern:
- User-Exit-Daten auf separate Datenbank:
Für jede Zuordnung "Index <-> Text" werden von PCL1001 zwei Sätze angelegt: Der eine enthält im DB-Key den Text und im Datenteil den Index und wird von PCL1001 selbst genutzt, um für einen angelieferten Text den entsprechenden Index zu finden. In der Auswertung dann ist die umgekehrte Richtung erforderlich, da der User-Exit MCL0097 den Index erhält und den zugehörigen Text finden muss. Da der DB-Key aber in jedem DB-Satz gleich lang ist und die generierten Indizes nicht länger als 12 Byte werden, würden bei jedem solchen Satz 247 – 12 = 235 Byte verschwendet. Deshalb kann man auf D A 109 mit "INDEX-TEXT-DB = …" eine separate Summendatenbank für die in MCL0097 gebrauchten Sätze definieren, deren Key-Länge dann statt 250 nur 15 Byte lang ist. Der Datenteil wird immer nur in der benötigten Länge weggespeichert und verschwendet deshalb keinen Platz. - Bei kürzeren Texten Key-Länge reduzieren:
Weiß man im Voraus, dass die Texte der Indexschlüssel nicht länger als bspw. 30 werden, so kann man mit der Angabe "TEXT-INDEX-TL-1 = 30" die Key-Länge der Index-DB auf die ausreichenden 33 (=30 + 3) Bytes beschränken. Man kann aber auch eine 2. (oder 3.) Datenbank definieren mit jeweils unterschiedlichen Key-Längen. Diesen können dann verschiedene Indexschlüssel zugeordnet werden (siehe nächster Punkt). Analog zu TEXT-INDEX-DB-1 und TEXT-INDEX-TL-1 gibt es deshalb auch TEXT-INDEX-DB-2, TEXT-INDEX-TL-2, TEXT-INDEX-DB-3 sowie TEXT-INDEX-TL-3.
Die Indexdatenbanken müssen wie üblich initialisiert werden, für PCL1050 wurden deshalb die Optionen ergänzt, mit denen einzelne oder alle definierten Index-DBs initialisiert werden können:
| Option PCL1050 | Zu setzende Text-DB-Variable |
|---|---|
| TEXT-INDEX-1 | TEXT-INDEX-DB-1 |
| TEXT-INDEX-2 | TEXT-INDEX-DB-2 |
| TEXT-INDEX-3 | TEXT-INDEX-DB-3 |
| INDEX-TEXT | INDEX-TEXT-DB |
| INDEX-DB | (alle obigen, soweit gesetzt) |
Analog zu den anderen "speziellen" Summen-DBs (Berichte, Anforderungs-Cache usw.) können und sollten auch die Index-DBs gelegentlich mit PCL1024 abgezogen und mit PCL1013 neu geladen werden, um sie kompakt zu halten. Dies muss allerdings für jede physische Index-DB (d.h. für jede benutzte AG-Nummer) gesondert durchgeführt werden.
Indexschlüssel anlegen
Indexschlüssel (und –relationen) werden in der ST06 über das Feld
TEXTIERUNG-LAENGE definiert: Hier ist die max. Textlänge des Schlüssels
(also max. 247) einzutragen. PCL1001 entscheidet dann anhand dieser
Länge, auf welcher Index-DB dessen Text-Index-Zuordnungen gespeichert
werden.
Es wird empfohlen, die Indexschlüssel (auch Teilschlüssel von
Indexrelationen) als neue Schlüssel anzulegen bzw. deren Ausprägungen
komplett von PCL1001 erzeugen zu lassen. So ist die Konsistenz von
Ausprägungen auf der Schlüssel-DB und Zuordnungen auf der Index-DB am
einfachsten gewährleistet.
Hinweis:
Die externe und interne Länge des Schlüssels definieren jeweils eine
Obergrenze für die Anzahl der indizierten Texte auf der Index-DB. Die
"klassischen" Ausprägungen des Index-Schlüssels sind die von PCL1001
generierten Indizes, also einfache Zählnummern. Für einen Indexschlüssel
mit externer Länge 5 kann z.B. maximal der Index "99999" generiert
werden, andererseits legt die interne Länge wie immer die Gesamtanzahl
der Schlüsselausprägungen fest.
Insbesondere bei einer Indexrelation ist also darauf zu achten, dass
zumindest ab dem 2. Teilschlüssel externe und interne Länge
zusammenpassen:
| Int. Länge | Ext. Länge | Max. Index | Hinweis |
|---|---|---|---|
| 1 | <= 2 | 99 | |
| 2 | <= 4 | 9.999 | |
| 3 | <= 7 | 9.999.999 | In Relation nicht empfohlen |
| 4 | <= 8 | 99.999.999 | In Relation nicht empfohlen |
PCL1001 generiert max. 12-stellige Indizes. Sinnvoll wäre also ein Indexschlüssel mit interner Länge 4 (max. 900 Mio. Ausprägungen) und externer Länge 9. Die vollen 12 Stellen lassen sich nur durch eine Indexrelation nutzen: Empfohlen sind hier drei Teilschlüssel der internen Länge 2 mit externer Länge 4, dann kann jeder Teilschlüssel die Zahlen "0000"-"9999" aufnehmen.
Einspeichern mit PCL1001
Die Anlieferung der Texte für die Indexschlüssel kann nur über eine
externe Schnittstelle im Textformat (Option "EXIT_TEXT") erfolgen. Bei
kurzem oder langem Format werden die Indexschlüssel (und die angelieferten
Inhalte) wie normale Schlüssel behandelt. Im Folgenden sei EXIT_TEXT
vorausgesetzt.
PCL1001 erkennt die Indexschlüssel automatisch (TEXTIERUNG-LAENGE > 0)
und ordnet jeden einer bestimmten Index-DB zu:
- Gibt es zu einem Schlüssel bereits Einträge auf einer Index-DB, bleibt er dieser zugeordnet, unabhängig davon, ob die aktuelle TEXTIERUNG-LAENGE zur Key-Länge dieser Index-DB passt.
- Ansonsten wird der Schlüssel der Index-DB mit der kürzesten Key-Länge zugeordnet, welche Texte der Länge TEXTIERUNG-LAENGE aufnehmen kann. Gibt es keine solche Index-DB, bricht das Programm ab.
WICHTIG: Die zugeordnete Index-DB (also NICHT die TEXTIERUNG-LAENGE) definiert dann, wie lang die angelieferten Texte für den jeweiligen Indexschlüssel sein dürfen. Ein Summensatz mit zu langem Text wird als fehlerhafter Summensatz behandelt.
Ein für einen Indexschlüssel angelieferter Inhalt wird immer als Text interpretiert und über die dem Schlüssel zugeordnete Index-DB in einen Index umgeschlüsselt. Auf der Index-DB wird ggf. eine neue Zuordnung generiert, d.h. dann entsteht ein neuer Index und damit eine neue Ausprägung für die Schlüssel-DB (in jedem Fall bei Schlüsseln, nicht unbedingt bei Relationen: das entscheidet sich erst nach dem "Zerteilen" der Ausprägung auf die Teilschlüssel).
Es kann mitunter wünschenswert sein, Indexschlüssel bei der Einspeicherung
wie normale Schlüssel zu behandeln, also die angelieferten Inhalte wie
normale Ausprägungen zu behandeln und nicht über die Index-DB in Indizes
umzuschlüsseln.
Dann sind die betroffenen Indexschlüssel im Kopfsatz mit dem Präfix "I"
zu versehen (also "I123" statt "123"), Relationen mit dem Präfix "J"
("J456" statt "R456")".
Ein Anwendungsfall wäre z.B., wenn die angelieferten Inhalte Indizes
darstellen, die bereits Texten zugeordnet sind. Dadurch beschleunigt
sich die Einspeicherung, da die Index-DB nicht abgefragt werden muss.
Eine derartige Schnittstelle ließe sich z.B. mit PCL1019 erstellen
(siehe "Betrieb II", Kap. 4.1.14).
Auf diese Weise lassen sich aber natürlich auch beliebige
nichtnumerische Inhalte einspeichern, die in der Auswertung dann ggf.
nicht über den User-Exit textiert werden können.
HINWEIS:
Die für die Schlüssel-DB generierten Indexausprägungen werden bis
zur externen Länge mit führenden Nullen aufgefüllt. Insbesondere
entstehen dadurch bei Relationen keine leeren Inhalte für die
Teilschlüssel.
Auswertung via User-Exit
Die langen Texte werden über den User-Exit MCL0097 ausgewertet: Für Indexschlüssel im Kopf- und Zeilenbereich, bei denen die Inhaltsbezeichnung angefordert ist (mit oder ohne Inhalt) und die nicht über das kundeneigene User-Exit-Unterprogramm MCL0897 (falls installiert) oder den Standard-User-Exit (PCL1231) textiert werden, werden die Bezeichnungen von der Index-DB gelesen.
Wird der User-Exit über ein kundeneigenes Copy SST2165 gesteuert, so können die Zugriffe auf die Index-DB dem Quellcode von MCL0097 entnommen werden.
PCL1274/PCL1275: Index-DB sichern/laden/bearbeiten
Zum Sichern und Laden der Index-DBs gibt es die Batch-Programme PCL1274 bzw. PCL1275, welche in Ihrer Funktionalität den Programmen PCL1264/PCL1265 (Pseudonym-DB) ähneln. PCL1274 zieht alle Index-DBs (oder ggf. einzelne Indexschlüssel) auf eine sequentielle csv-Datei ab, welche mit PCL1275 wieder geladen werden kann. Für technische Details siehe "Betrieb II", Kap. 8.23.
ACHTUNG:
Durch einen Ladelauf mit PCL1275 können neue Indizes generiert werden,
diese werden aber nicht als Ausprägungen auf der Schlüssel-DB ergänzt.
Dies geschieht nur in PCL1001!
Die Sätze in der PCL1275-Schnittstelle haben folgenden Aufbau:
| Feld | Bedeutung | Hinweis |
|---|---|---|
| 1 | Verarbeitungskennzeichen | leer oder "ADD","MOD","DEL" |
| 2 | Satzart | leer (für künftige Erweiterungen) |
| 3 | Schlüssel-/Relationsnr. | Pflichtfeld; Relationsnr. mit "R"-Präfix |
| 4 | Textierung | Pflichtfeld, wenn 1. Feld leer oder "ADD","MOD" |
| 5 | Index (Ausprägung) | Pflichtfeld, wenn 1. Feld "ADD","MOD","DEL" |
Beispiel für eine PCL1275-Schnittstelle:
; ;123;Dies ist ein Text für Indexschlüssel Nr. 123;
ADD; ;123;Text für Index 538 beim Schlüssel 123 ;538
MOD; ;123;Text bei Index 74 wird überschrieben ;74
DEL; ;123; ;8999
Alle Sätze des Beispiels betreffen den Indexschlüssel 123:
- Der 1. Satz (leeres Verarbeitungskennzeichen) ergänzt den angelieferten Text unter einem neuen Index auf der Datenbank, wenn er nicht bereits einem Index zugeordnet ist. Der Index kann nicht vorgegeben werden, das 5. Feld ist leer bzw. wird sein Inhalt ignoriert.
- Der 2. Satz (ADD) ergänzt den angelieferten Text unter dem Index 538, aber nur, wenn Text und Index noch nicht anderweitig zugeordnet sind (sonst Fehler).
- Der 3. Satz (MOD) überschreibt den Text zum Index 74 mit dem angelieferten Text, aber nur, wenn Index 74 bereits zugeordnet ist, der angelieferte Text aber noch nicht (sonst Fehler).
- Der 4. Satz (DEL) löscht die Zuordnung zum Index 8999 von der Index-DB. Das Textfeld wird ignoriert.
Es wird also nicht spezifiziert, auf welcher physischen Index-DB die Indizierungen der einzelnen Schlüssel gespeichert sind (PCL1274) bzw. werden sollen (PCL1275). PCL1275 entscheidet das ebenso wie PCL1001: steht der Indexschlüssel schon auf einer bestimmten Index-DB, werden auch die Schnittstellensätze dorthin gespeichert. Bei einem neuen Schlüssel wird dessen TEXTIERUNG-LAENGE (ST06) abgefragt, im Unterschied zu PCL1001 wird hier aber bei deren Fehlen vom Maximalwert 247 ausgegangen (lediglich Warnhinweis im Protokoll).
Wie PCL1001 ergänzt/pflegt auch PCL1275 für jede Indizierung zwei Datenbanksätze: einer enthält im DB-Key den Text (für die Nutzung in PCL1001), der andere den Index (für den User-Exit), letzterer ggf. auf einer separaten Datenbank (siehe INDEX-TEXT-DB oben).
Vorlaufkartenoptionen:
- PCL1274, "KEY = …": Einzelne Schlüssel abziehen, z.B. "KEY = 123, KEY = R456"
- PCL1275:
- "ADD" oder "MOD" oder "DEL": Wird auf alle Sätze mit leerem Verarbeitungskennzeichen angewandt.
- "DELETE_KEY = … ": Einzelne Schlüssel löschen, z.B. "DELETE_KEY = 123, DELETE_KEY = R456". Danach wird die Eingabeschnittstelle verarbeitet.
- "DELETE_ALL": Alle Schlüssel löschen. Danach wird die Eingabeschnittstelle verarbeitet.
Soll z.B. der Indexschlüssel 123 auf eine andere physische Index-DB umgeladen werden, um z.B. längere Texte zu ermöglichen, muss er mit PCL1274 abgezogen (Vorlaufkarte: "KEY = 123"), die TEXTIERUNG-LAENGE in der ST06 wie gewünscht geändert und der PCL1274-Abzug mit PCL1275 wieder geladen werden (Vorlaufkarte: "DELETE_KEY = 123", damit der Schlüssel seiner neuen Index-DB zugewiesen werden kann).
8.13 Änderungen an ASS-Daten loggen (Log-Datenbank)
Um Änderungen an ASS-Datenbanken dokumentieren zu können, wurde mit ASS 8.70 die sog. "Log-Datenbank" eingeführt.
Alle in der ST06 (auch Web-ST06 und Clientversion ST16) und ST09 (auch Web-ST09 und Clientversion ST19) vorgenommenen Änderungen an den ASS-Datenbanken DST001, DST002,
DST003, DST007 und DST009 werden bei entsprechender Installation auf einer Datenbank vermerkt.
Außerdem werden Passwortänderungen geloggt, welche aus den Anmeldemasken von ASS-Excel oder ASS-Internet heraus vorgenommen wurden.
Analog zum AG-Cache, zur Berichtsdatenbank u.Ä. wird hierfür die Summendatenbank eines zu reservierenden Arbeitsgebietes verwendet (s. AG-LOGDB). Siehe auch PCL1284 Log-DB abziehen und PCL1285 Log-DB Pflege. Für das Initialisieren der Datenbank mit PCL1050 steht dort die Vorlaufkartenoption "LOG-DB" zur Verfügung.
Jede geloggte Transaktion erhält eine eindeutige Nummer (Transaktions-ID), unter welcher der ändernde Benutzer, dessen aktuelles Berechtigungsprofil sowie ein Zeitstempel (Datum und sekundengenaue Zeit) festgehalten wird. Jedes neu angelegte, geänderte oder gelöschte DB-Segment wird geloggt, bei Neuanlage und Änderung komplett (z.B. beim Schlüsselsegment mit Nummer, Bezeichnung, Abkürzung, interner/externer Länge etc.). Beim Löschen werden jeweils nur die nötigen Infos geloggt (z.B. beim Schlüssel nur dessen Nummer). Da die Änderung eines DB-Segmentes evtl. weitere, implizit vom ASS ausgeführte Änderungen nach sich ziehen kann (z.B. werden beim Löschen eines Schlüssels alle Arbeitsgebiete, die diesen enthalten, auf "ungeprüft" gesetzt), können unter einer Transaktions-ID mehrere geänderte Segmente geloggt werden. I.d.R. wird ein Segment auch nur geloggt, wenn es wirklich geändert wurde (ein AG in obiger Situation also nur, wenn es nicht schon auf "ungeprüft" steht). Somit können auch "leere" Logeinträge (d.h. ohne geänderte Segmente) entstehen.
Die Logeinträge können mit dem Dienstprogramm PCL1284 auf eine csv-Datei ($ASS/ASSLOGDB.CSV) ausgegeben werden. Für jedes geloggte Segment wird ein Ausgabesatz erzeugt,
d.h. mehrere Sätze können dieselbe Transaktions-ID haben.
Die Sätze in der Ausgabedatei haben folgenden Aufbau:
| Feld | Bedeutung | Hinweis |
|---|---|---|
| 1 | Datum | Format JHJJMMTT |
| 2 | Uhrzeit | Format HHMMSS |
| 3 | Transaktions-ID | Wie beschrieben |
| 4 | Angemeldeter Benutzer | Angemeldeter Security-Master, ST09-Benutzer oder ASS-Benutzer (leer, wenn direkt mit Profil angemeldet) |
| 5 | Berechtigungsprofil | Bei ST09-Änderungen nicht gesetzt |
| 6 | Umgebung | ST09 oder ST06 |
| 7 | Typ | Typ des geänderten Segments: WE: Wert KY: Schlüssel AU: Ausprägung RE: Relation AG: Arbeitsgebiet VS: Verwendeter Schlüssel im Arbeitsgebiet CV: Verdichtungsstufe im Arbeitsgebiet VW: Verwendeter Wert in Verdichtungsstufe SA: Beschreibender Text zu AG oder Verdichtungsstufe TE: Text auf Text-DB BE: Berechtigungsprofil ZU: Zugriffsprofil PR: Benutzer EM: E-Mail-Empfänger ME: E-Mail-Verteiler S9: ST09-Benutzer PW: Passwort für Security-Master PC: PC-Empfänger ER: Fehler (Error), der bei DB-Änderung auftrat. Die Transaktion wurde i.d.R. nicht ordentlich abgeschlossen. |
| 8 | OPC |
Art der Änderung: NA: Neuanlage AE: Änderung DL: Löschung |
| 9 | (Typabhängig) |
Je nach Typ: WE: Wertenr. KY/AU: Schlüsselnr. RE: Relationsnr. AG/VS/CV/VW/SA: AG-Nr. TE: Text-Sprache (i.d.R. also D) BE/ZU/PR/EM/ME/S9/PW/PC: Name des Elements |
| 10 | (Typabhängig) |
Je nach Typ (hier nur eine Auswahl): AU: Interner (verdichteter) Inhalt VS: Schlüsselnr. CV/VW/SA: Verdichtungsstufennr. (bei SA: 0 bedeutet AG-Beschreibung) TE: Textart BE/PR/S9: PA, wenn Passwort des Elements behandelt |
| 11 | (Typabhängig) |
Je nach Typ (hier nur eine Auswahl): AU: Externer Inhalt VW: Wertenr. TE: Textnr. BE/ZU/PR/EM/ME/S9/PC: Kommentar zum Element BE/PR/S9 bei Passwort (PA): "********", ggf. mit "INIT" für Initialpasswort |
| Rest | (Typabhängig) | Nicht weiter beschrieben |
9 Ordnungssystem bei der Namensvergabe
Folgende Objektklassen gehören zu ASS:
- Datenbanken
- Programme
- Include-Member
- PSB's (nur DLI)
- Bildschirmmaskenbeschreibungen
- MFS für IMS-Umgebung
- BMS für CICS-Umgebung
- FHS für UTM-Umgebung
- Transaktionscodes
Nachfolgend wird für jede Objektklasse beschrieben, wie die Namen der Elemente aufgebaut sind.
Die insgesamt vergebenen Namen können Sie den Handbüchern für INSTALLATION und BETRIEB oder der ASS-Versionstabelle entnehmen. Datenbanken:
Namensaufbau:
|
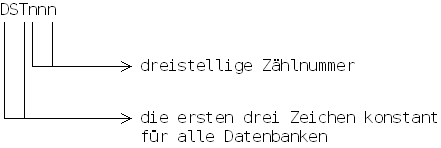
|
Die Zählnummern reichen von 110 für Arbeitsgebiet 1 bis 600 für Arbeitsgebiet 50.
Programme :
Namensaufbau:
|

|
INCLUDE-Member:
Namensaufbau:
|
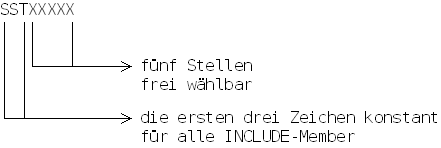
|
Vergebene Namen:
Auf eine Aufzählung der vergebenen Namen wird verzichtet, da der Informationsgehalt einer derartigen Liste gering ist. Zwei Namen weichen jedoch von der obigen Namenskonvention ab:
- ONDUMP1 : Fehlerbehandlung BATCH
- ONDUMP2 : Fehlerbehandlung BATCH
PSB's (nur DLI):
Namensaufbau:
|
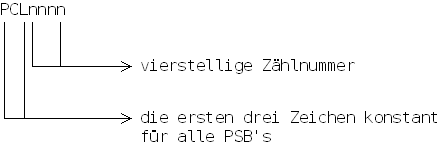
|
Masken:
Namensaufbau:
|
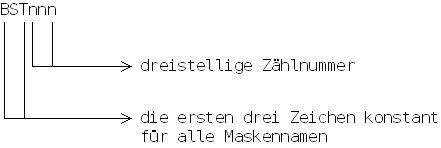
|
Transaktionscodes :
Namensaufbau:
|
|
vergebene Namen:
| Name | zugehöriges Prog. | Bemerkung |
|---|---|---|
| ST06 | PCL0006 | |
| ST31 | PCL0031 |
10 Weitere Beispiele
Dieser Abschnitt enthält einige etwas anspruchsvollere Beispiele zur Auswertung. Auf die optische Gestaltung des Druckbildes wurde hier kein besonderer Wert gelegt, da es primär darum geht, kurz zu zeigen, dass ASS vielfältige Anforderungen abdecken kann. Es wird auch kein Anspruch auf Vollständigkeit erhoben.
Beispiel 1 (Beispiel für aktuelle Gruppierungen)
ASS;
AG: 19;
ZS:
GESELLSCHAFT = ('1',
'2',
* ,
'3',
'4',
* );
SS:
WERTE = (
JAHRESBEITRAG (0100 ), /* 01904 */
JAHRESBEITRAG (0100 /* 01904 */
,GESELLSCHAFT /* 01902 */ = $$AKTUELL
,TARIFGRUPPE2 /* 01903 */ = $$AKTUELL ) ,
JAHRESBEITRAG (0100 /* 01904 */
,GESELLSCHAFT /* 01902 */ = $$AKTUELL
,TARIFGRUPPE2 /* 01903 */ ^='$$AKTUELL ') );
OPT: DINA4, BLANKS = 10;
END;
A S S V G **** L0701 **** 19.02.01 BLATT 1
ARBEITSGEBIET: 19: LEBEN_DEMO
I WERTE
I JAHRESBEITRAG
I 0100 0100 0100
I ------ GESELLSCHAFT GESELLSCHAFT
I ------ = $$AKTUELL = $$AKTUELL
I ------ TARIFGRUPPE2 TARIFGRUPPE2
I ------ = $$AKTUELL ^=$$AKTUELL
GESELL I DM DM DM
------------------------------------------------------------
I
1 I 184.080.877 178.929.307 5.151.570
2 I 252.933.100 228.692.840 24.240.260
I
* I 437.013.977 407.622.147 29.391.830
I
3 I 309.843.410 30.068.590- 339.912.000
4 I 8.114.760- 243.410 8.358.170-
I
* I 301.728.650 29.825.180- 331.553.830
Beispiel 2 (Beispiel für Ausprägungsmengen)
VSTAT ;
AG: 19;
ZS:
TARIFGRUPPE2 , /* 01903 */
ORGANISATIONSDIREKT /* 01901 */ =(
'1?',
'2?',
'3?',
'MITTEL'= ('1?' + '2?' + '3?') / 3 );
SS:
WERTE =(
ANZAHL_VERTRAEGE (0100 ), /* 01901 */
STAT_VERS_SUMME (0100 ), /* 01902 */
PRODUKTIONSWERT (0100 ), /* 01903 */
JAHRESBEITRAG (0100 ) ); /* 01904 */
OPT: DINA4, BLANKS = 10;
END;
A S S V G **** L0701 **** 19.02.01 BLATT 1
ARBEITSGEBIET: 19: LEBEN_DEMO
I WERTE
I ANZAHL_ STAT_VERS_SU PRODUKTIONSW JAHRESBEITRAG
I 0100 0100 0100 0100
TARIFG ORGANI I STUECK DM DM DM
-------------------------------------------------------------------
I
1 1? I 2.086 44.269.703 40.285.478 177.772.147
2? I 1.456 62.888.459 47.211.166 217.698.992
3? I 1.551 82.223.973 74.823.967 323.979.520
MITTEL I 1.698 63.127.378 54.106.870 239.816.886
I
2 1? I 18 14.855- 13.519- 1.157.160
2? I 1.238 12.043.721 10.959.785 10.993.848
3? I 21 2.983.787 2.715.246 2.506.020
MITTEL I 426 5.004.218 4.553.837 4.885.676
I
3 1? I 39 443.707 403.794 4.196.840
2? I 10 529.311 481.692 4.665.610
3? I 912- 6.510.596- 5.924.625- 30.068.590-
MITTEL I 288- 1.845.859- 1.679.713- 7.068.713-
I
4 1? I 2- 2.000- 1.820- 0
2? I 888- 749.977- 682.435- 0
3? I 24- 38.030- 34.607- 0
MITTEL I 305- 263.336- 239.621- 0
I
5 1? I 2 181.242 164.931 222.760
2? I 7 222.720 202.674 16.786.400
3? I 15 596.512 542.825 19.946.360
MITTEL I 8 333.491 303.477 12.318.507
I
6 1? I 4 604.800 550.368 170.880
2? I 2 2.088.000 1.900.080 813.560
3? I 81- 11.200.800- 10.192.728- 4.693.100-
MITTEL I 25- 2.836.000- 2.580.760- 1.236.220-
I
7 1? I 5- 19.672 17.903 561.090
2? I 31 243.635 221.707 1.974.690
3? I 4 189.272 172.240 1.826.800-
MITTEL I 10 150.860 137.283 236.327
Beispiel 3 (Beispiel für Ausprägungsmengen)
VSTAT ;
AG: 19;
ZS:
TARIFGRUPPE2 /* 01903 */ =(
'LEBEN'
(1,4),
'RENTE'
(5,
6,
7),
* ),
ORGANISATIONSDIREKT /* 01901 */ =(
'?1',
'?2',
'?3' );
SS:
WERTE =(
ANZAHL_VERTRAEGE (0100 ), /* 01901 */
STAT_VERS_SUMME (0100 ), /* 01902 */
PRODUKTIONSWERT (0100 ), /* 01903 */
JAHRESBEITRAG (0100 ) ); /* 01904 */
OPT: DINA4, BLANKS = 10;
END;
A S S V G **** L0701 **** 19.02.01 BLATT 1
ARBEITSGEBIET: 19: LEBEN_DEMO
I WERTE
I ANZAHL_ STAT_VERS_SU PRODUKTIONSW JAHRESBEITRAG
I 0100 0100 0100 0100
TARIFG ORGANI I STUECK DM DM DM
-------------------------------------------------------------------
I
LEBEN ?1 I 894 43.123.392 29.224.978 136.056.375
?2 I 1.509 52.210.773 47.511.899 213.645.987
?3 I 2.199 88.423.671 80.465.638 348.842.478
I
RENTE ?1 I 17- 3.206.180- 2.917.625- 3.632.332
?2 I 4- 237.564 216.184 18.104.058
?3 I 30- 4.116.331- 3.745.859- 12.093.010
I
* I 4.551 176.672.889 150.755.215 732.374.240
Beispiel 4 (Beispiel für Formeln, Spaltenumbruch, Summenblock)
VSTAT ;
AG: 19 ;
KS: ZEITRAUM = (
0200
);
ZS: 1903,
ORGANISATIONSDIREKT= (
11,
12,
13,
21,
LEERZEILE (2) ,
FO1 = '11' + '12' ,
FO2 = '11' + '13' ,
FO3 = '11' + '21' ,
LEERZEILE (2) ,
22,
23,
* ,
31,
** ,
32,
33,
**
);
SS: WERTE = (
ANZAHL_VERTRAEGE,
STAT_VERS_SUMME ,
S1 = ANZAHL_VERTRAEGE + STAT_VERS_SUMME ,(12,2,DIM1),
S2 = ANZAHL_VERTRAEGE - STAT_VERS_SUMME ,(12,2,DIM2),
S3 = ANZAHL_VERTRAEGE - STAT_VERS_SUMME
+ STAT_VERS_SUMME - ANZAHL_VERTRAEGE +
GESAMT(ORGANISATIONSDIREKT,ANZAHL_VERTRAEGE,**) ,
(12,2,DIM3)
);
GR: SUMMENBLOCK;
OPT: STARTSEITE = 5,DINA4, BLANKS=6 ,
KEUEB ,
KEBEZI,
NULLDRUCK ;
END ;
A S S V G **** L0701 **** 19.02.01 BLATT 5
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I WERTE
I ANZAHL_ STAT_VERS_SU
TARIFGRUPPE OD I STUECK DM
-------------------------------------------------------
GROSSLEBEN OD HANNOVER VAB I 271 2.392.459
OD KOELN VAB I 725 10.473.562
OD KARLSRUHE VAB I 738 16.148.225
OD NORD VEI I 219- 3.635.902-
I
I
FO1 I 996 12.866.021
FO2 I 1.009 18.540.684
FO3 I 52 1.243.443-
I
I
OD WEST VEI I 278- 2.509.219-
OD SUED VEI I 300- 18.287
I
* I 2.994 53.050.674
I
OD HAMBURG VK I 231 6.791.881
I
* I 231 6.791.881
I
** I 3.225 59.842.555
I
OD WIESBADEN VK I 245 4.757.629
OD MUENCHEN VK I 555 20.749.643
I
** I 800 25.507.272
I
*** I 4.025 85.349.827
I
RISIKO OD HANNOVER VAB I 2- 33.138
OD KOELN VAB I 5 1.001.841
OD KARLSRUHE VAB I 18 1.649.022
OD NORD VEI I 2 122.441
I
I
FO1 I 3 1.034.979
FO2 I 16 1.682.160
FO3 I 0 155.579
I
I
OD WEST VEI I 8 712.437
OD SUED VEI I 1 1.128.172-
I
* I 51 5.263.425
A S S V G **** L0701 **** 19.02.01 BLATT 6
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S1 S2
TARIFGRUPPE OD I DIM1 DIM2
----------------------------------------------------------------------
GROSSLEBEN OD HANNOVER VAB I 2.392.730,00 2.392.188,00-
OD KOELN VAB I 10.474.287,00 10.472.837,00-
OD KARLSRUHE VAB I 16.148.963,00 16.147.487,00-
OD NORD VEI I 3.636.121,00- 3.635.683,00
I
I
FO1 I 12.867.017,00 12.865.025,00-
FO2 I 18.541.693,00 18.539.675,00-
FO3 I 1.243.391,00- 1.243.495,00
I
I
OD WEST VEI I 2.509.497,00- 2.508.941,00
OD SUED VEI I 17.987,00 18.587,00-
I
* I 53.053.668,00 53.047.680,00-
I
OD HAMBURG VK I 6.792.112,00 6.791.650,00-
I
* I 6.792.112,00 6.791.650,00-
I
** I 59.845.780,00 59.839.330,00-
I
OD WIESBADEN VK I 4.757.874,00 4.757.384,00-
OD MUENCHEN VK I 20.750.198,00 20.749.088,00-
I
** I 25.508.072,00 25.506.472,00-
I
*** I 85.353.852,00 85.345.802,00-
I
RISIKO OD HANNOVER VAB I 33.136,00 33.140,00-
OD KOELN VAB I 1.001.846,00 1.001.836,00-
OD KARLSRUHE VAB I 1.649.040,00 1.649.004,00-
OD NORD VEI I 122.443,00 122.439,00-
I
I
FO1 I 1.034.982,00 1.034.976,00-
FO2 I 1.682.176,00 1.682.144,00-
FO3 I 155.579,00 155.579,00-
I
I
OD WEST VEI I 712.445,00 712.429,00-
OD SUED VEI I 1.128.171,00- 1.128.173,00
I
* I 5.263.476,00 5.263.374,00-
A S S V G **** L0701 **** 19.02.01 BLATT 7
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S3
TARIFGRUPPE OD I DIM3
----------------------------------------------------
GROSSLEBEN OD HANNOVER VAB I 3.225,00
OD KOELN VAB I 3.225,00
OD KARLSRUHE VAB I 3.225,00
OD NORD VEI I 3.225,00
I
I
FO1 I 3.225,00
FO2 I 3.225,00
FO3 I 3.225,00
I
I
OD WEST VEI I 3.225,00
OD SUED VEI I 3.225,00
I
* I 3.225,00
I
OD HAMBURG VK I 3.225,00
I
* I 3.225,00
I
** I 3.225,00
I
OD WIESBADEN VK I 800,00
OD MUENCHEN VK I 800,00
I
** I 800,00
I
*** I ------------
I
RISIKO OD HANNOVER VAB I 52,00
OD KOELN VAB I 52,00
OD KARLSRUHE VAB I 52,00
OD NORD VEI I 52,00
I
I
FO1 I 52,00
FO2 I 52,00
FO3 I 52,00
I
I
OD WEST VEI I 52,00
OD SUED VEI I 52,00
I
* I 52,00
A S S V G **** L0701 **** 19.02.01 BLATT 8
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I WERTE
I ANZAHL_ STAT_VERS_SU
TARIFGRUPPE OD I STUECK DM
-------------------------------------------------------
I
RISIKO OD HAMBURG VK I 1 833.565
I
* I 1 833.565
I
** I 52 6.096.990
I
OD WIESBADEN VK I 15 1.852.986
OD MUENCHEN VK I 17 2.763.463
I
** I 32 4.616.449
I
*** I 84 10.713.439
I
VBL OD HANNOVER VAB I 47- 479.170-
OD KOELN VAB I 29 151.538
OD KARLSRUHE VAB I 34 85.558
OD NORD VEI I 128- 1.614.244-
I
I
FO1 I 18- 327.632-
FO2 I 13- 393.612-
FO3 I 175- 2.093.414-
I
I
OD WEST VEI I 192- 1.808.063-
OD SUED VEI I 109- 54.808-
I
* I 619- 6.533.847-
I
OD HAMBURG VK I 6- 117.767-
I
* I 6- 117.767-
I
** I 625- 6.651.614-
I
OD WIESBADEN VK I 29- 103.143-
OD MUENCHEN VK I 32- 15.676
I
** I 61- 87.467-
I
*** I 686- 6.739.081-
A S S V G **** L0701 **** 19.02.01 BLATT 9
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S1 S2
TARIFGRUPPE OD I DIM1 DIM2
----------------------------------------------------------------------
I
RISIKO OD HAMBURG VK I 833.566,00 833.564,00-
I
* I 833.566,00 833.564,00-
I
** I 6.097.042,00 6.096.938,00-
I
OD WIESBADEN VK I 1.853.001,00 1.852.971,00-
OD MUENCHEN VK I 2.763.480,00 2.763.446,00-
I
** I 4.616.481,00 4.616.417,00-
I
*** I 10.713.523,00 10.713.355,00-
I
VBL OD HANNOVER VAB I 479.217,00- 479.123,00
OD KOELN VAB I 151.567,00 151.509,00-
OD KARLSRUHE VAB I 85.592,00 85.524,00-
OD NORD VEI I 1.614.372,00- 1.614.116,00
I
I
FO1 I 327.650,00- 327.614,00
FO2 I 393.625,00- 393.599,00
FO3 I 2.093.589,00- 2.093.239,00
I
I
OD WEST VEI I 1.808.255,00- 1.807.871,00
OD SUED VEI I 54.917,00- 54.699,00
I
* I 6.534.466,00- 6.533.228,00
I
OD HAMBURG VK I 117.773,00- 117.761,00
I
* I 117.773,00- 117.761,00
I
** I 6.652.239,00- 6.650.989,00
I
OD WIESBADEN VK I 103.172,00- 103.114,00
OD MUENCHEN VK I 15.644,00 15.708,00-
I
** I 87.528,00- 87.406,00
I
*** I 6.739.767,00- 6.738.395,00
A S S V G **** L0701 **** 19.02.01 BLATT 10
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S3
TARIFGRUPPE OD I DIM3
----------------------------------------------------
I
RISIKO OD HAMBURG VK I 52,00
I
* I 52,00
I
** I 52,00
I
OD WIESBADEN VK I 32,00
OD MUENCHEN VK I 32,00
I
** I 32,00
I
*** I ------------
I
VBL OD HANNOVER VAB I 625,00-
OD KOELN VAB I 625,00-
OD KARLSRUHE VAB I 625,00-
OD NORD VEI I 625,00-
I
I
FO1 I 625,00-
FO2 I 625,00-
FO3 I 625,00-
I
I
OD WEST VEI I 625,00-
OD SUED VEI I 625,00-
I
* I 625,00-
I
OD HAMBURG VK I 625,00-
I
* I 625,00-
I
** I 625,00-
I
OD WIESBADEN VK I 61,00-
OD MUENCHEN VK I 61,00-
I
** I 61,00-
I
*** I ------------
A S S V G **** L0701 **** 19.02.01 BLATT 11
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I WERTE
I ANZAHL_ STAT_VERS_SU
TARIFGRUPPE OD I STUECK DM
-------------------------------------------------------
KLEINLEBEN OD HANNOVER VAB I 0 0
OD KOELN VAB I 0 0
OD KARLSRUHE VAB I 0 0
OD NORD VEI I 97- 112.971-
I
I
FO1 I 0 0
FO2 I 0 0
FO3 I 97- 112.971-
I
I
OD WEST VEI I 147- 187.611-
OD SUED VEI I 38- 38.756-
I
* I 379- 452.309-
I
OD HAMBURG VK I 2- 1.000-
I
* I 2- 1.000-
I
** I 381- 453.309-
I
OD WIESBADEN VK I 8- 8.705-
OD MUENCHEN VK I 2- 1.000-
I
** I 10- 9.705-
I
*** I 391- 463.014-
I
LEIBRENTEN OD HANNOVER VAB I 2- 21.586
OD KOELN VAB I 0 0
OD KARLSRUHE VAB I 0 0
OD NORD VEI I 1- 103.200-
I
I
FO1 I 2- 21.586
FO2 I 2- 21.586
FO3 I 3- 81.614-
I
I
OD WEST VEI I 3- 90.000-
OD SUED VEI I 3- 108.000-
I
* I 16- 318.056-
A S S V G **** L0701 **** 19.02.01 BLATT 12
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S1 S2
TARIFGRUPPE OD I DIM1 DIM2
----------------------------------------------------------------------
KLEINLEBEN OD HANNOVER VAB I 0,00 0,00
OD KOELN VAB I 0,00 0,00
OD KARLSRUHE VAB I 0,00 0,00
OD NORD VEI I 113.068,00- 112.874,00
I
I
FO1 I 0,00 0,00
FO2 I 0,00 0,00
FO3 I 113.068,00- 112.874,00
I
I
OD WEST VEI I 187.758,00- 187.464,00
OD SUED VEI I 38.794,00- 38.718,00
I
* I 452.688,00- 451.930,00
I
OD HAMBURG VK I 1.002,00- 998,00
I
* I 1.002,00- 998,00
I
** I 453.690,00- 452.928,00
I
OD WIESBADEN VK I 8.713,00- 8.697,00
OD MUENCHEN VK I 1.002,00- 998,00
I
** I 9.715,00- 9.695,00
I
*** I 463.405,00- 462.623,00
I
LEIBRENTEN OD HANNOVER VAB I 21.584,00 21.588,00-
OD KOELN VAB I 0,00 0,00
OD KARLSRUHE VAB I 0,00 0,00
OD NORD VEI I 103.201,00- 103.199,00
I
I
FO1 I 21.584,00 21.588,00-
FO2 I 21.584,00 21.588,00-
FO3 I 81.617,00- 81.611,00
I
I
OD WEST VEI I 90.003,00- 89.997,00
OD SUED VEI I 108.003,00- 107.997,00
I
* I 318.072,00- 318.040,00
A S S V G **** L0701 **** 19.02.01 BLATT 13
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S3
TARIFGRUPPE OD I DIM3
----------------------------------------------------
KLEINLEBEN OD HANNOVER VAB I 381,00-
OD KOELN VAB I 381,00-
OD KARLSRUHE VAB I 381,00-
OD NORD VEI I 381,00-
I
I
FO1 I 381,00-
FO2 I 381,00-
FO3 I 381,00-
I
I
OD WEST VEI I 381,00-
OD SUED VEI I 381,00-
I
* I 381,00-
I
OD HAMBURG VK I 381,00-
I
* I 381,00-
I
** I 381,00-
I
OD WIESBADEN VK I 10,00-
OD MUENCHEN VK I 10,00-
I
** I 10,00-
I
*** I ------------
I
LEIBRENTEN OD HANNOVER VAB I 17,00-
OD KOELN VAB I 17,00-
OD KARLSRUHE VAB I 17,00-
OD NORD VEI I 17,00-
I
I
FO1 I 17,00-
FO2 I 17,00-
FO3 I 17,00-
I
I
OD WEST VEI I 17,00-
OD SUED VEI I 17,00-
I
* I 17,00-
A S S V G **** L0701 **** 19.02.01 BLATT 14
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I WERTE
I ANZAHL_ STAT_VERS_SU
TARIFGRUPPE OD I STUECK DM
-------------------------------------------------------
I
LEIBRENTEN OD HAMBURG VK I 1- 29.172-
I
* I 1- 29.172-
I
** I 17- 347.228-
I
OD WIESBADEN VK I 3 140.400
OD MUENCHEN VK I 0 0
I
** I 3 140.400
I
*** I 14- 206.828-
I
BV OD HANNOVER VAB I 0 0
OD KOELN VAB I 1 198.000
OD KARLSRUHE VAB I 3 648.000
OD NORD VEI I 2- 417.600
I
I
FO1 I 1 198.000
FO2 I 3 648.000
FO3 I 2- 417.600
I
I
OD WEST VEI I 5- 475.200-
OD SUED VEI I 2- 100.800-
I
* I 3- 1.951.200
I
OD HAMBURG VK I 17- 1.756.800-
I
* I 17- 1.756.800-
I
** I 20- 194.400
I
OD WIESBADEN VK I 6- 1.627.200-
OD MUENCHEN VK I 8- 489.600-
I
** I 14- 2.116.800-
I
*** I 34- 1.922.400-
A S S V G **** L0701 **** 19.02.01 BLATT 15
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S1 S2
TARIFGRUPPE OD I DIM1 DIM2
----------------------------------------------------------------------
I
LEIBRENTEN OD HAMBURG VK I 29.173,00- 29.171,00
I
* I 29.173,00- 29.171,00
I
** I 347.245,00- 347.211,00
I
OD WIESBADEN VK I 140.403,00 140.397,00-
OD MUENCHEN VK I 0,00 0,00
I
** I 140.403,00 140.397,00-
I
*** I 206.842,00- 206.814,00
I
BV OD HANNOVER VAB I 0,00 0,00
OD KOELN VAB I 198.001,00 197.999,00-
OD KARLSRUHE VAB I 648.003,00 647.997,00-
OD NORD VEI I 417.598,00 417.602,00-
I
I
FO1 I 198.001,00 197.999,00-
FO2 I 648.003,00 647.997,00-
FO3 I 417.598,00 417.602,00-
I
I
OD WEST VEI I 475.205,00- 475.195,00
OD SUED VEI I 100.802,00- 100.798,00
I
* I 1.951.197,00 1.951.203,00-
I
OD HAMBURG VK I 1.756.817,00- 1.756.783,00
I
* I 1.756.817,00- 1.756.783,00
I
** I 194.380,00 194.420,00-
I
OD WIESBADEN VK I 1.627.206,00- 1.627.194,00
OD MUENCHEN VK I 489.608,00- 489.592,00
I
** I 2.116.814,00- 2.116.786,00
I
*** I 1.922.434,00- 1.922.366,00
A S S V G **** L0701 **** 19.02.01 BLATT 16
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S3
TARIFGRUPPE OD I DIM3
----------------------------------------------------
I
LEIBRENTEN OD HAMBURG VK I 17,00-
I
* I 17,00-
I
** I 17,00-
I
OD WIESBADEN VK I 3,00
OD MUENCHEN VK I 3,00
I
** I 3,00
I
*** I ------------
I
BV OD HANNOVER VAB I 20,00-
OD KOELN VAB I 20,00-
OD KARLSRUHE VAB I 20,00-
OD NORD VEI I 20,00-
I
I
FO1 I 20,00-
FO2 I 20,00-
FO3 I 20,00-
I
I
OD WEST VEI I 20,00-
OD SUED VEI I 20,00-
I
* I 20,00-
I
OD HAMBURG VK I 20,00-
I
* I 20,00-
I
** I 20,00-
I
OD WIESBADEN VK I 14,00-
OD MUENCHEN VK I 14,00-
I
** I 14,00-
I
*** I ------------
A S S V G **** L0701 **** 19.02.01 BLATT 17
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I WERTE
I ANZAHL_ STAT_VERS_SU
TARIFGRUPPE OD I STUECK DM
-------------------------------------------------------
I
GRUPPEN OD HANNOVER VAB I 2- 28.235-
OD KOELN VAB I 0 0
OD KARLSRUHE VAB I 21 410.981
OD NORD VEI I 1- 128.760
I
I
FO1 I 2- 28.235-
FO2 I 19 382.746
FO3 I 3- 100.525
I
I
OD WEST VEI I 3 55.058-
OD SUED VEI I 6- 98.844-
I
* I 29 812.640
I
OD HAMBURG VK I 0 0
I
* I 0 0
I
** I 29 812.640
I
OD WIESBADEN VK I 14 2.664.301
OD MUENCHEN VK I 0 106.304-
I
** I 14 2.557.997
I
*** I 43 3.370.637
A S S V G **** L0701 **** 19.02.01 BLATT 18
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S1 S2
TARIFGRUPPE OD I DIM1 DIM2
----------------------------------------------------------------------
I
GRUPPEN OD HANNOVER VAB I 28.237,00- 28.233,00
OD KOELN VAB I 0,00 0,00
OD KARLSRUHE VAB I 411.002,00 410.960,00-
OD NORD VEI I 128.759,00 128.761,00-
I
I
FO1 I 28.237,00- 28.233,00
FO2 I 382.765,00 382.727,00-
FO3 I 100.522,00 100.528,00-
I
I
OD WEST VEI I 55.055,00- 55.061,00
OD SUED VEI I 98.850,00- 98.838,00
I
* I 812.669,00 812.611,00-
I
OD HAMBURG VK I 0,00 0,00
I
* I 0,00 0,00
I
** I 812.669,00 812.611,00-
I
OD WIESBADEN VK I 2.664.315,00 2.664.287,00-
OD MUENCHEN VK I 106.304,00- 106.304,00
I
** I 2.558.011,00 2.557.983,00-
I
*** I 3.370.680,00 3.370.594,00-
A S S V G **** L0701 **** 19.02.01 BLATT 19
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S3
TARIFGRUPPE OD I DIM3
----------------------------------------------------
I
GRUPPEN OD HANNOVER VAB I 29,00
OD KOELN VAB I 29,00
OD KARLSRUHE VAB I 29,00
OD NORD VEI I 29,00
I
I
FO1 I 29,00
FO2 I 29,00
FO3 I 29,00
I
I
OD WEST VEI I 29,00
OD SUED VEI I 29,00
I
* I 29,00
I
OD HAMBURG VK I 29,00
I
* I 29,00
I
** I 29,00
I
OD WIESBADEN VK I 14,00
OD MUENCHEN VK I 14,00
I
** I 14,00
I
*** I ------------
A S S V G **** L0701 **** 19.02.01 BLATT 20
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I WERTE
I ANZAHL_ STAT_VERS_SU
TARIFGRUPPE OD I STUECK DM
-------------------------------------------------------
I
GESAMT OD HANNOVER VAB I 218 1.939.778
OD KOELN VAB I 760 11.824.941
OD KARLSRUHE VAB I 814 18.941.786
OD NORD VEI I 446- 4.797.516-
I
I
FO1 I 978 13.764.719
FO2 I 1.032 20.881.564
FO3 I 228- 2.857.738-
I
I
OD WEST VEI I 614- 4.412.714-
OD SUED VEI I 457- 1.511.093-
I
* I 2.057 53.773.727
I
OD HAMBURG VK I 206 5.720.707
I
* I 206 5.720.707
I
** I 2.263 59.494.434
I
OD WIESBADEN VK I 234 7.676.268
OD MUENCHEN VK I 530 22.931.878
I
** I 764 30.608.146
I
*** I 3.027 90.102.580
A S S V G **** L0701 **** 19.02.01 BLATT 21
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S1 S2
TARIFGRUPPE OD I DIM1 DIM2
----------------------------------------------------------------------
I
GESAMT OD HANNOVER VAB I 1.939.996,00 1.939.560,00-
OD KOELN VAB I 11.825.701,00 11.824.181,00-
OD KARLSRUHE VAB I 18.942.600,00 18.940.972,00-
OD NORD VEI I 4.797.962,00- 4.797.070,00
I
I
FO1 I 13.765.697,00 13.763.741,00-
FO2 I 20.882.596,00 20.880.532,00-
FO3 I 2.857.966,00- 2.857.510,00
I
I
OD WEST VEI I 4.413.328,00- 4.412.100,00
OD SUED VEI I 1.511.550,00- 1.510.636,00
I
* I 53.775.784,00 53.771.670,00-
I
OD HAMBURG VK I 5.720.913,00 5.720.501,00-
I
* I 5.720.913,00 5.720.501,00-
I
** I 59.496.697,00 59.492.171,00-
I
OD WIESBADEN VK I 7.676.502,00 7.676.034,00-
OD MUENCHEN VK I 22.932.408,00 22.931.348,00-
I
** I 30.608.910,00 30.607.382,00-
I
*** I 90.105.607,00 90.099.553,00-
A S S V G **** L0701 **** 19.02.01 BLATT 22
ARBEITSGEBIET: 19: LEBEN_DEMO
ZEITRAUM: 0200
I
I S3
TARIFGRUPPE OD I DIM3
----------------------------------------------------
I
GESAMT OD HANNOVER VAB I 2.263,00
OD KOELN VAB I 2.263,00
OD KARLSRUHE VAB I 2.263,00
OD NORD VEI I 2.263,00
I
I
FO1 I 2.263,00
FO2 I 2.263,00
FO3 I 2.263,00
I
I
OD WEST VEI I 2.263,00
OD SUED VEI I 2.263,00
I
* I 2.263,00
I
OD HAMBURG VK I 2.263,00
I
* I 2.263,00
I
** I 2.263,00
I
OD WIESBADEN VK I 764,00
OD MUENCHEN VK I 764,00
I
** I 764,00
I
*** I ------------
11 ASS-Monitor
Mit dem neuen ASS-Monitor wurde ein Monitoring-Tool
geschaffen, mit welchem die derzeit aktiven und bereits
abgeschlossenen ASS-Batch-Programme überwacht werden
können. Voraussetzung für die Nutzung ist eine installierte
Log-Datenbank.
Wenn entsprechend installiert, kann hiermit für ein
momentan laufendes Programm ein Abbruch erzwungen werden.
Dies ist insbesondere für Windows-Umgebungen interessant,
da ein harter Abbruch z.B. über den Task-Manager manchmal
einen Rechnerneustart erfordert, da dann im Zugriff
befindliche ASS-Datenbanken nicht geschlossen wurden, was
in Linux-Umgebungen vom Betriebssystem nachgeholt wird.
Aber auch dann wären im Schreibzugriff befindliche
Datenbanken mitunter zerstört, d.h. ein Abbruch via ASS-Monitor
wäre künftig immer vorzuziehen. Insbesondere würde
dieser dann auch geloggt und im Batchprotokoll angedruckt.
Der ASS-Monitor ist als Java-Servlet analog zur Web-ST06
oder Web-ST09 realisiert. Seine Funktionalität kann auch
durch den Einsatz der Batchprogramme PCL1284 und PCL1285
erreicht werden, aber natürlich
nicht so komfortabel wegen fehlender graphischer
Benutzeroberfläche.
Analog zur Web-ST06 ist die Anmeldung an den Monitor für
entsprechend berechtigte, passwortgeschützte Benutzer (im
Sinne von ASS-Benutzern oder direkt Berechtigungsprofilen)
möglich. Für den Zugriff ist die Berechtigung "XM" unter
"Sonstiges" (ST09) erforderlich, für das Beenden von Batch-
Programmen die Berechtigung "XN", welche "XM"
impliziert. Damit das Beenden überhaupt möglich ist, muss
außerdem der Text-DB-Eintrag "TRANSAKTION-BEENDEN = J"
existieren.
 Beim Einstieg erhält man die Übersicht über alle Batch-
Transaktionen des aktuellen Monats, standardmäßig aber nur
max. 1000 Einträge. Diese Zahl kann jedoch über die Text-DB
geändert werden (WMNTR-GRENZWERT).
Beim Einstieg erhält man die Übersicht über alle Batch-
Transaktionen des aktuellen Monats, standardmäßig aber nur
max. 1000 Einträge. Diese Zahl kann jedoch über die Text-DB
geändert werden (WMNTR-GRENZWERT).Die angezeigten Transaktionen können über Datum- und ID-Angaben eingeschränkt werden, außerdem ist es möglich, entweder alle (bzgl. der Filterkriterien relevanten) Transaktionen oder nur die aktuell laufenden Transaktionen (dann werden die Filterkriterien ignoriert) anzeigen zu lassen. In der Übersichtstabelle hat man dann auch die in den ASS-Web-Anwendungen üblichen Sortier- und Filteroptionen. Durch Doppelklick auf eine Zeile oder Eingabe einer Transaktions-ID in das oberste Feld erhält man sämtliche Log-Einträge zu dieser Transaktion in einem neuen Fenster.

Ist die Transaktion schon abgeschlossen, so werden sämtliche zur Verfügung stehende Informationen in dem Infofenster präsentiert.
 Ist die Transaktion noch nicht abgeschlossen, kann man die
Anzeige manuell aktualisieren (Button "Aktualisieren")
oder, wenn so installiert und man berechtigt ist, ein Ende
der Transaktion anfordern (Button "Beenden"):
Ist die Transaktion noch nicht abgeschlossen, kann man die
Anzeige manuell aktualisieren (Button "Aktualisieren")
oder, wenn so installiert und man berechtigt ist, ein Ende
der Transaktion anfordern (Button "Beenden"):Wird die Transaktion beendet, passiert Folgendes: Es wird ein spezieller Satz auf die Log-DB geschrieben. Das zu beendende Programm prüft ab Programmstart in regelmäßigen Abständen, ob dieser Satz existiert, und beendet sich, wenn es diesen findet. Um die Lesezugriffe auf die Log-DB etwas einzuschränken, findet pro Minute max. eine Abfrage statt. Ggf. muss man also etwas warten, bis das Programm wirklich beendet wird.
Stichwortverzeichnis
A B D E F I K L M N O P S T U V W Z
- A
- Ableitbare Werte 8.5
- Aliasschlüssel 8.8
- Allgemeines Statistikaufbau 3
- Analyse eines Arbeitsgebietes 7
- Anforderung 2.10
- Anforderungsdatenbank 6.5
- Anlieferungsart (Wert) 7.7.2
- Arbeitsgebiet
2.5
- Verwendete Schlüssel 2.6
- Arbeitsgebietsanalyse 7
- Arbeitsgebietsdatenbank 6.3
- Arbeitsgebietsübergreifende Aspekte 7.5
- ASS-Dokumentation 0
- ASS-Funktionsumfang 4
- ASS-Monitor 11
- ASS-Zielsetzung 1
- Auswerterverhalten kontrollieren 8.4
- Auswertung
- Beispiele 10
- Auswertungs-Schnittstelle (Datei LDAT) 8.3
- B
- Begriffsdefinitionen 2
- Bestandswerte
- Folgeeinspeicherung 5.4
- Bewegungswerte
- Folgeeinspeicherung 5.4
- Bibliothek für Listanforderungen 6.5
- Bitschlüssel 8.2
- D
- Datei LDAT 8.3
- Dateibeschreibungen 6
- Datenbankbeschreibungen 6
- Datenschutzkritische Schlüssel 8.11
- Dokumentation (ASS) 0
- DST001
- Wertedatenbank 6.1
- DST002
- Schlüsseldatenbank 6.2
- DST003
- Steuerungsdatenbank 6.3
- DST004
- Anforderungsdatenbank 6.5
- DST005
- SPA-Datenbank 6.6
- DST009
- Securitydatenbank 8.1
- I
- Indexschlüssel, Indexrelation, Indexdatenbank 8.12
- N
- Namensvergabe
- internes Ordnungssystem 9
- O
- Ordnungssystem bei der Namensvergabe 9
- P
- Protokoll-Arbeitsgebiet 8.10
- S
- Schlüssel 2.3
- Schlüsselausprägung 2.4 6.3
- Schlüsseldatenbank 6.2
- Schlüsselinhalt 2.4
- Schnittstelle
- Security 8.1
- Sichten 8.7
- SPA-Datenbank 6.6
- Speicherungsart 2.9
- Statistik über Statistiken 8.4
- Statistikbild 3
- Statistikdatenbank (Summendatenbank
- Satzaufbau 6.4.1
- Statistikdatenbank (Summendatenbank) 6.4
- Steuerungsdatenbank 6.3
- Summendatenbank 6.4
- U
- Umrechnungswerte 7.8.2
- V
- Verdichtungsprinzipien 6.4
- Verdichtungsstufe 2.7
- Verdichtungsstufen
- Interner Aufbau 6.4.1
- Verkettete Schlüssel 8.6
- Verwendete Schlüssel im Arbeitsgebiet 2.6
- Verwendete Werte 2.8